作者:实验室小陈/大数据开放实验室
对于事务型数据库而言,最关键的功能是要保证事物ACID属性,其中原子性和持久性依靠恢复子系统保证。事务在进行中如果发现无法继续,就需要用恢复子系统进行回滚;或者出现系统崩溃,也需要依靠恢复子系统把数据库恢复到崩溃前状态。在本专栏中,我们主要介绍Logging Protocols / Recovery Algorithms,它们分别是事务型数据库恢复子系统中的两个关键部分。
Logging Schemes
恢复子系统中的关键是恢复算法,目的是要实现两个过程。首先是事务执行过程中为系统恢复做的准备工作,目前大多数系统通常采用日志记录方式,尽管事务执行过程中同时记录数据更新日志会有额外开销,但如果没有日志,一旦系统崩溃则无法实现系统恢复和未完成事务的回滚。此外,还有Shadow Paging方案,即数据每次修改都通过Copy-on-Write的方式进行。在更新数据时,复制一份原数据的副本并在副本上进行更新,最后通过用副本替换原始数据的方式完成操作。Shadow Paging方案开销较大,一般用在更新不频繁的场景下,如文本编辑器等类似场景,因此事务型数据库系统里大都采用基于日志的方案。第二个过程是在出现系统故障或事务回滚的情况时,如何利用系统记录的日志信息并采用合适策略来保证数据库能够恢复到正确状态。
Physical Logging & Logical Logging
Logging分为Physical Logging和Logical Logging两类。Physical Logging指在日志记录中记录对数据项的修改,如数据项A在修改之前的值为90,修改之后是100,Physical Logging会将数据项A的变化过程记录下来。在一个数据库系统中,Physical Logging可能是Value Logging,即记录数据项、数据项ID、修改前/后的属性值等信息;也可能是真正的物理Logging,即记录磁盘页面PageID、Offset和长度,以及修改前后的值。
另外一类是Logical Logging,不记录执行结果,只记录对数据修改的操作如delete / update等。较于Physical Logging根据修改前后的值进行恢复或重放,Logical Logging在重放时需要重新执行日志中的操作,在回滚时需要执行日志中所记录操作的逆操作,比如插入对应的删除等。
Physical Logging VS Logical Logging
两种Logging各有优缺点。Logical Logging记录的日志内容较少,比如update操作,Logical Logging只需要记录一条update语句即可,日志记录开销少。缺点是在并发场景下较难实现,当同时有多个事务产生更新操作时,数据库内部会将这些操作调度为串行化序列执行,需要机制来保障每次回放操作的执行顺序与调度产生的顺序一致。所以,大多数数据库系统采用Physical Logging来保证数据恢复的一致性,事务管理器(并发控制子系统)所产生的事务操作执行顺序会以日志的方式被记录下来,恢复子系统根据日志顺序能够保证每一个数据项修改的回滚和重放都按照顺序严格执行。但目前,有一些数据库系统依旧使用Logical Logging,如内存数据库引擎VoltDB,这是因为VoltDB引擎设计上没有并发控制,每个CPU内核都顺序执行所有操作,因此可以通过Logical Logging按序回放。
对于数据库管理系统而言,要保证故障发生情况下的数据持久性和正确性,因此恢复子系统不可或缺。在事务执行过程中,需要撤销时能够回滚以保障原子性;但同时恢复子系统会带来性能影响,因为所有日志记录只有刷到磁盘上才算真正落盘,即使事务所有操作全部完成,也一定要等日志落盘后才能响应客户端,因此Logging的性能往往成为整个系统的性能瓶颈。
Recovery System Optimization
对于日志或恢复子系统的优化,主要有两类技术,一类是Group Commit,另一类是Early Lock Release。
Group Commit
Group Commit是将并行执行的一组事务日志一起刷到磁盘,而非分事务每条日志刷一次。日志有单独的日志缓冲区,所有事务先把日志写进日志缓冲区,通过设置单独线程定时将日志缓冲区中的内容刷进磁盘,或当日志缓冲区存储满时再刷到磁盘。
操作系统提供了Sync、Fsync、Fdatasync等不同写磁盘的方式,其中Sync把数据刷到操作系统文件缓冲区时就视为结束,随后靠操作系统后台进程把缓冲区的内容刷到磁盘,因此通过Sync方式刷磁盘可能会造成数据丢失。数据库系统通常采用Fsync进行日志落盘,当记录真正写到磁盘里面时才返回。Fsync是将文件数据以及文件元数据如修改时间、文件长度等信息一起写到磁盘;而Fdatasync跟Fsync的区别在于其只刷数据而不刷元数据。
在一些DBMS中,会混用Fsync和Fdatasync:当元数据修改不影响Logging,比如只有文件修改时间变化,这时只用Fdatasync即可;但如果操作修改了文件长度,这时就不能用Fdatasync,因为Fdatasync并不保存元数据修改信息,在恢复时会造成内容部分缺失。由于很多DBMS在写日志时不是以增量方式增加日志文件内容,而是一次性为日志文件分配足够空间,在之后的写日志过程中日志文件长度保持不变,所以可以用Fdatasync将日志写到磁盘。可以看到,Group Commit每次将一组事务使用一个系统调用写到磁盘,合并很多事务I/O,从而降低整个系统的I/O。
Early Lock Release
在基于锁机制实现并发控制时,如果前序事务的锁没有释放,后面的事务只能处于等待锁的状态。图中黑色部分表示正在进行的事务操作,灰色部分是等待日志落盘的时间,虽然此时对数据不做修改,但只有等日志刷到磁盘后才能释放锁。Early Lock Release是一种面向此场景提高性能的优化方法,策略是当事务中处理工作的部分做完就释放锁,然后再将日志落盘,缩短下个事务等待锁的时间,提高并发执行程度。
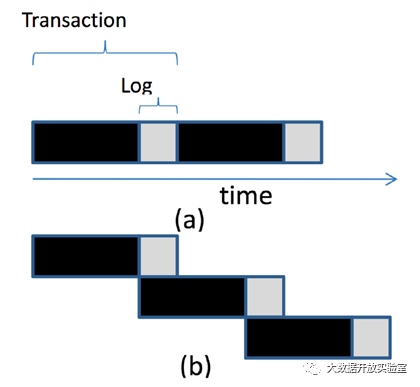
但这种方式同样存在缺陷,比如第一个事务已经释放锁,但在日志落盘时出现故障需要回滚,但由于此时锁已经被下一个事务获得,下一个事务要和上一个事务一起回滚,因此系统需要维护事务间的依赖关系。在现实中,锁的提前释放技术在数据库中被广泛使用。对于索引结构,如果对索引中的某个节点加锁,会产生较大影响范围,因为一个索引叶子节点往往涉及一连串的很多数据记录。如果对叶子节点加锁,相关记录都会被锁住。因此在索引的使用上,通常会采用Early Lock Release而非两阶段封锁协议,以缩短数据记录被锁住的时间。
ARIES算法
在基于磁盘的数据库系统中,恢复子系统大都是基于ARIES(Algorithms for Recovery and Isolation ExploitingSemantics)算法实现。ARIES对于数据缓冲区和日志缓冲区的管理采用Steal + No Force的管理策略(关于Steal + No Force的介绍在《内存数据库解析与主流产品对比(一)》中有详细提到)。在ARIES中,每条日志会有一个顺序号LSN(Log Sequence Number),如下图中LSN 10号的日志是事务T1写Page 5的更新操作;20号LSN是事务T2写Page 3的更新操作。需要注意的是,日志中会保留有事务end记录,标识事务已commit并返回客户端,表示该事务所有操作已经完成。如果日志中只有commit而没有end,那可能意味着事务已经完成,但客户端可能没有收到响应。

ARIES三阶段恢复
ARIES的恢复算法分三个阶段:Analysis、Redo、Undo,每阶段具体细节后面会详细介绍。
Analysis:在出现crash重启后,系统首先会从磁盘上读出日志文件,分析日志文件内容,判断哪些事务在系统crash时处于Active状态,以及哪些Page在出现故障时被修改过。
Redo:系统在redo阶段根据日志重现故障现场,包括将内存中的Dirty Page恢复到crash时的状态,相当于重放日志历史记录(Repeating History),并将每条日志记录都执行一遍,包括没有commit的事务日志。
Undo:Undo阶段系统开始撤销没有完成的事务。上图是日志记录的简单示例,系统在LSN 60后crash,其中日志中有事务T2 end的标记,所以T2已经提交,而事务T1和T3都尚未完成,事务T1和T3对于P1、P3和P5的修改如果已落盘,就需要从磁盘上撤销。
日志记录的数据结构
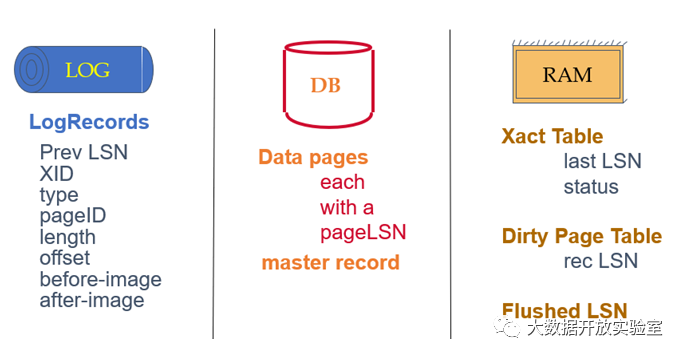
对于ARIES恢复子系统,恢复过程需要基于Logging所存储的信息进行。ARIES中日志由多条日志记录组成,一条日志记录里包含修改数据项的事务ID、Page ID + Offset、长度、修改前后的数值以及额外的控制信息。
ARIES的日志类型包括Update、Commit、Abort、End以及补偿日志记录CLR(Compensation Log Record )。CLR用于预防因事务回滚过程中出现故障造成影响,当事务回滚时,每回滚一条日志就记录一条CLR,系统可以通过CLR判断哪些操作已经回滚,如果不记录CLR则可能出现操作回滚两次的情况。

在正常记录日志时,ARIES会记录redo和undo信息,记录的日志包含修改前后的值等。一般来说,日志落盘是顺序写,因此数据库在配置上会为日志服务单独安排磁盘,不和存储数据记录的盘混用,以提升日志写的性能。
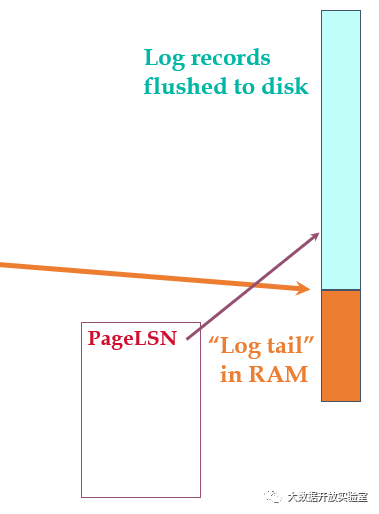
下面是ARIES中日志落盘示意图,图中右侧序列代表所有日志,青蓝色部分代表已经落盘的日志,橙色部分表示还在日志缓冲区里的日志。ARIES会记录Flushed LSN,代表目前已有哪些缓冲区的日志已经刷到磁盘。此外,保存数据的每个磁盘块中都会记录一个Page LSN,用来表示修改此数据Page的所有操作中对应的最大日志号(即最后一个修改数据Page的操作所对应的日志号)。在把数据缓冲区里的数据刷到磁盘时,通过判断Page LSN与flushed LSN的大小决定是否可以将数据刷到磁盘。如果Page LSN 小于等于Flushed LSN ,说明修改这个数据页面的所有日志记录都已落盘,因此数据也可以落盘,这就是所谓的WAL(Write-Ahead-Log),日志总是先于数据写到磁盘。
此外,日志记录中还保存了Prev LSN来对应日志所属事务的前一个日志号。由于在系统中所有事务共享日志缓冲区,因此产生的日志是穿插在一起的,可以通过Prev LSN把属于同一个事务的所有LSN串联起来,来找到事务所对应的所有日志。
恢复子系统中还需要维护Xact Table和Dirty Page Table。Xact Table用来记录所有活动的Transaction的状态如active、commit、abort、end等;同时还记录事务最后产生的日志号Last LSN。Dirty Page Table用来记录哪些数据Page从磁盘上加载到缓冲区后被修改过, 以及每个Page最早修改时的日志号Rec LSN(即数据Page被加载到缓冲区后第一个修改操作所对应的日志号)。
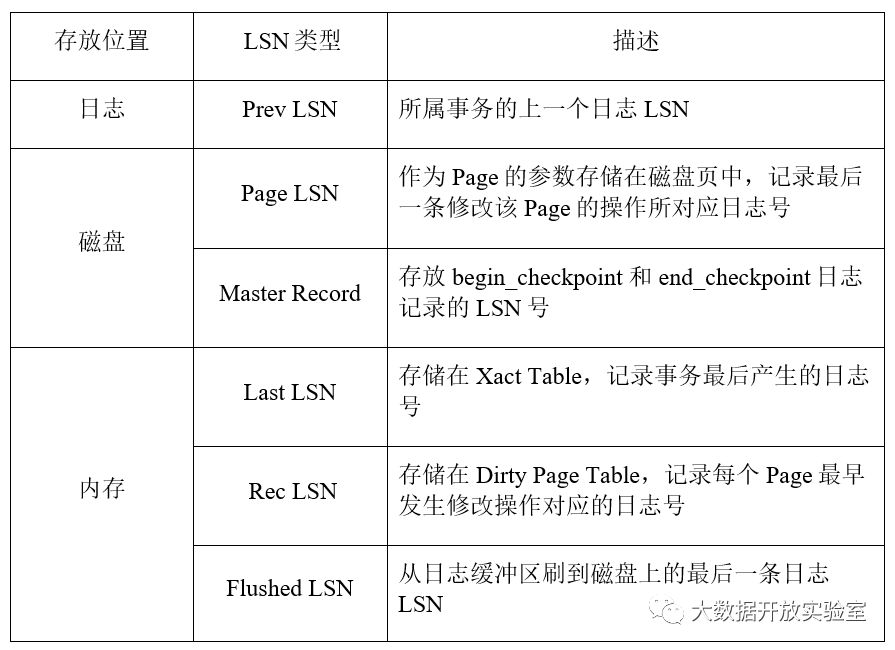
除了在日志中记录信息外,为保证恢复可以成功完成,数据库系统还需要用Master Record记录Checkpoint的LSN,保证在每次恢复时只需要从最近的Checkpoint开始即可。由于数据库系统在做Checkpoint时需要停机(不允许任何事务执行),这对于使用者很难接受,因此ARIES中的Checkpoint采用Fuzzy Checkpoint方式,即在进行Checkpoint时允许事务可以持续不断执行。Fuzzy Checkpoint会产生两个日志记录:Begin_Checkpoint和End_Checkpoint。Begin_Checkpoint负责记录开始Checkpoint的时间点,End_Checkpoint记录Xact Table和Dirty Page Table,而Checkpoint的LSN会写到磁盘的Master Record上进行持久存储。以上即恢复所需的全部数据结构,各类LSN的整理总结如下表所示。
数据库系统的事务恢复
简单事务恢复
对于简单事务恢复(系统没有出现故障,而是事务在执行过程中不再继续),此时需要进行回滚。回滚时,系统首先从Xact Table中找出最新的LSN进行undo,随后通过该日志记录的Prev LSN找到前序日志记录再继续undo,直到整个事务彻底回放到开始时的状态。和正常事务操作相似,undo时的数据实际上需要加锁,并在回滚前会记录补偿日志CLR。CLR会记录undo next的LSN号以指向下一条需要undo的LSN,在undo到Transaction Start的LSN时,记录Transaction Abort和Transaction End表明回滚结束。
出现故障的事务恢复
在前文我们提到,ARIES的故障恢复分为三个阶段,下面将详细介绍三个阶段的执行细节。
Analysis阶段
在Analysis阶段,系统从磁盘上的Master Record中获取最后一个Checkpoint日志记录,重构出Xact Table和Dirty Page Table,并从Begin_Checkpoint日志记录开始顺序处理后续的日志记录。在遇到一个事务的end日志时,将其从Xact Table中去除;如果遇到事务的commit日志,则更新Xact Table中对应事务的状态;如果遇到其它日志记录,判断该事务是否在Xact Table中,不在则将其加入Xact Table,并更新Xact Table中该事务的Last LSN为当前日志记录的LSN。此外,系统会判断日志记录中更新的数据Page是否在Dirty Page Table,如不在则将该数据Page加入到Dirty Page Table,并将其Rec LSN设为当前日志号。
Redo阶段
系统在Redo阶段首先找出Dirty Page Table中所有PageRec LSN中最小的,作为redo的起始位置,因为再往前的日志记录对应的数据修改都已落盘,不会出现在Dirty Page Table中。随后系统从redo的起始位置开始,按顺序对后续更新日志记录(包括CLR)执行redo操作(重放)。如果遇到操作更新的Page不在Dirty Page Table中,或Page在Dirty Page Table中但Rec LSN大于当前LSN,或磁盘上的Page LSN大于当前的LSN,则都表示该LSN对应记录已经落盘,可以直接跳过,不需要执行redo。在redo时,系统不需要再记录日志,因为redo只是实现整个内存状态的重构,如果在redo时又出现了系统故障,则按照原来操作重新进行一遍。
Undo阶段
Undo阶段目的是撤销在系统故障时未完成的事务,开始时会建立一个需要undo的日志集*合,把每个需要回滚的事务的最后一条日志号放入该集*合中,然后开始进行循环处理。首先系统从集*合里挑出最大的LSN即最后一条进行undo,如果这条日志是CLR补偿日志,且它的undo-next为空,那么说明事务已经完成undo,可以记录一条End日志表明事务结束;如果补偿日志的undo-next不等于空,说明还有下一条需要undo的日志,那么就将下一条日志的LSN放入集*合;如果是更新日志,就回滚该日志且记录一条CLR日志,然后把日志的Prev LSN加入集*合。系统会按照上述过程不断循环,直到整个undo集*合为空。
接下来通过例子梳理一下整个过程。系统首先做了Fuzzy Checkpoint,出现了两次更新:T1修改了P5,T2修改了P3。随后,T1 abort 取消,LSN40记录了补偿日志——回滚LSN10,随后T1 End。接下来其他事务继续进行:T3修改了P1,T2修改了P5。此时出现了Crash,该怎么做恢复呢?首先在Analysis过程,由Checkpoint开始向后扫描,发现T1已经End不需要redo,T2、T3没有end可以进行redo,因此Xact Table里仅有T2 、T3,Dirty Page Table包括P1、P3、P5。在分析完成后,进行redo重做过程恢复故障现场,随后在T2、T3进行undo每一条日志时记录CLR,直到undo到每个事务最初的一条。
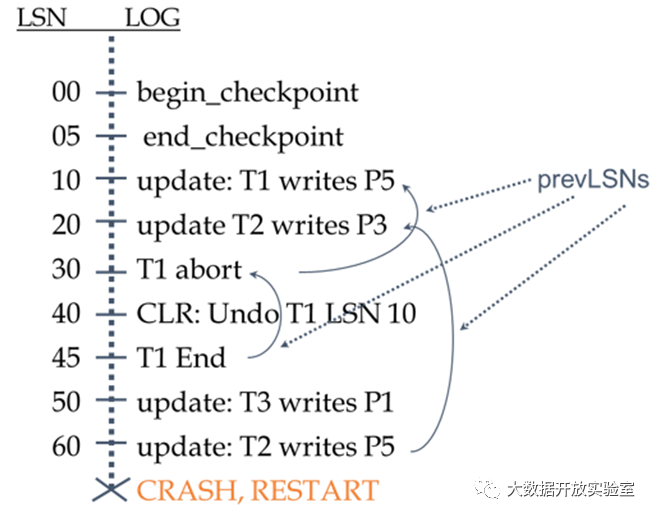
如果在恢复的过程中又出现了Crash(如下图所示),已经undo的两个操作由于记录了CLR,新redo会重做这两个CLR,而新undo过程不会再重新回滚。恢复系统会在原有基础上继续进行,直到所有的事务全部undo完成。

ARIES小结
ARIES是一个具有成熟设计,能够保证事务原子性和持久性的恢复系统,使用WAL和Steal + No Force缓冲区管理策略,且不影响系统正确性。ARIES中LSN是单调递增的日志记录唯一标识,通过链接方式把一个事务的所有日志串联在一起。Page LSN用来记录每个页面最后修改操作对应的日志号,系统通过Checkpoint减少Recovery的开销。整个恢复分为Analysis、Redo、Undo三个步骤,分析的目的是找出来哪些事务需要redo,哪些页面被修改过,修改是否已经落盘;随后通过redo恢复故障现场,利用undo将需要撤销的事务回滚。
本文小结
本文介绍了恢复系统Logging和Recovery的基本概念,并讨论了传统基于磁盘的数据库管理系统中恢复子系统ARIES的技术原理。下一篇文章会继续探索数据库的恢复子系统,讨论DBMS恢复中的Early Lock Release、Logical Undo,介绍两种数据库的恢复技术以及内存数据库的恢复方法。
参考文献:
1. C. Mohan, Don Haderle, Bruce Lindsay, Hamid Pirahesh, and Peter Schwarz. 1992. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking And Partial Rollbacks Using Write-Ahead Logging. ACM Trans. Database Syst. 17, 1 (March 1992), 94–162.
2. Antonopoulos, P., Byrne, P., Chen, W., Diaconu, C., Kodandaramaih, R. T., Kodavalla, H., … & Venkataramanappa, G. M. (2019). Constant time recovery in Azure SQL database. Proceedings of the VLDB Endowment, 12(12), 2143-2154.
3. Zheng, W., Tu, S., Kohler, E., & Liskov, B. (2014). Fast databases with fast durability and recovery through multicore parallelism. In 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14) (pp. 465-477).
4. Ren, K., Diamond, T., Abadi, D. J., & Thomson, A. (2016, June). Low-overhead asynchronous checkpointing in main-memory database systems. In Proceedings of the 2016 International Conference on Management of Data (pp. 1539-1551).
5. Kemper, A., & Neumann, T. (2011, April). HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In 2011 IEEE 27th International Conference on Data Engineering (pp. 195-206). IEEE.
注:文中的“*”仅为防敏感词,无具体含义。
——————————————————————————————————————————————
来源:freebuf.com 2020-11-27 11:36:20 by: 星环科技官方























请登录后发表评论
注册