*本文原创作者:littt0,本文属FreeBuf原创奖励计划,未经许可禁止转载
0x00 pre
近日,由于工作需要(不饱和)想开发一款linux下运行的webshell检测的工具,于是想到了使用机器学习算法来实现这一需求,于是翻了兜哥的著作《web安全之深度学习实战》,经过一些日子的学习,对机器学习有了初步的理解(当然由于我们目的是使用,能够实现跑起来的代码就行,不需要深入理解),写下了一个demo(途中遇到许多的坑)。接下来分享实现的代码,我的demo放在:
0x01 准备样本
说到机器学习,肯定离不开样本啦。webshell检测需要我们提供白样本和黑样本,即正常文件和webshell。样本的话当然是上github上寻找,我们以php为例子,
黑样本:
https://github.com/tennc/webshell
https://github.com/JohnTroony/php-webshells
https://github.com/ysrc/webshell-sample
白样本:
https://github.com/WordPress/WordPress
https://github.com/phpmyadmin/phpmyadmin
https://github.com/typecho/typecho
https://github.com/bcit-ci/CodeIgniter
收集好样本就要开始写代码啦。
0x02 实现
所有代码基于python3 实现。同时通过
pip install sklearn安装好我们需要的机器学习库。就可以正式开始啦
step1: 特征提取
首先将一个php文件处理成一个字符串以便接下来的特征提取:
def load_file(file_path):
t = b''
with open(file_path, "rb") as f:
for line in f:
line = line.strip(b'\r\n')
t += line
return t
在遍历目录下所有的文件(可递归),将所有的文件字符串都加载到一个列表中去:
def load_files(path):
files_list = []
for r, d, files in os.walk(path):
for file in files:
if file.endswith('.php'): #过滤非php文件
file_path = r + '/' + file
print("Load {}".format(file_path))
t = load_file(file_path)
files_list.append(t)
return files_list
这样我们就可以通过一句话将收集到的webshell样本加载到列表中:
webshell_files = load_files(webshell_dir)再添加上白名单列表
wp_files = load_files(normal_dir)这时候就需要一个标记这些列表中的字符串是正常文件还是webshell的标志位
计算长度:
black_count = len(webshell_files)
white_count = len(wp_files)
用数组记录,黑样本标记为1,白样本标记为0:
y1 = [1]*black_count
y2 = [0]*white_count
将黑样本在前,白样本在后合成一个数组记为x
标记数组同样处理记为y
x = webshell_files + wp_files
y = y1 + y2
使用2-Gram提取词袋的模型:
cv = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",
token_pattern=r'\b\w+\b', min_df=1,
max_df=1.0, max_features=max_features)
x = cv.fit_transform(x).toarray()
再使用TF-IDF进行处理:
transformer = TfidfTransformer(smooth_idf=False)
x = transformer.fit_transform(x).toarray()
好了,我们已经对x的特征进行了提取并向量化啦
接下来就是调用print 咳咳, MLP算法对样本学习的过程了。
step2: MLP算法
clf = MLPClassifier(solver="lbfgs", alpha=1e-5, hidden_layer_sizes=(5, 2),
random_state=1)
实例化MLP算法,隐含层设计为2层,每次的节点数分别为5,2。
接着使用train_test_split随机划分样本为训练集和测试集:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=0)
clf.fit(x_train, y_train)
调用predict测试学习的结果如何:
print(np.mean(y_test==clf.predict(x_test)))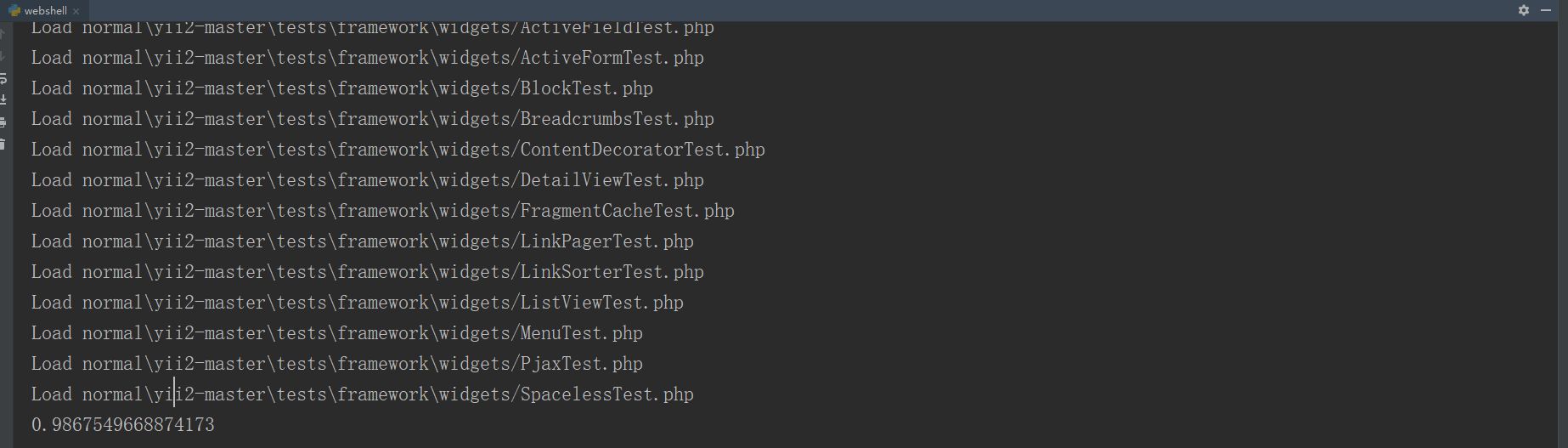
跑分还不错吗,有百分之九十八的准确率。
接下来就是喂这个学习成果别的样本的时候
step3: 编写检测函数
前面千辛万苦机器学习的成果,据说有98的准确率,但是机器最会骗人,实战中怎么样呢我们来试试:
def check(clf, cv, transformer, path):
all = 0
webshell = 0
not_webshell = 0
for r, d, files in os.walk(path):
for file in files:
file_path = r + '/' + file
t = load_file(file_path)
t_list = list()
t_list.append(t)
x = cv.transform(t_list).toarray()
x = transformer.transform(x).toarray()
y_pred = clf.predict(x)
all += 1
if y_pred[0] == 1:
print("{} is webshell".format(file_path))
webshell += 1
else:
not_webshell += 1
print("全部文件:{},webshell {} 未检出:{} 检出率:{}".format(all, webshell, not_webshell, webshell/all))
编写check函数, 我们需要将刚才的训练结果clf,cv, transformer,重新加载到新函数中。
然后编写遍历所有的文件 for r, d, files in os.walk(path),
将新的文件使用transform函数重新提取一下特征
x = cv.transform(t_list).toarray()
x = transformer.transform(x).toarray()
接下来就使用predict函数判断是不是webshell呢。
如果是的话我们就webshell +1
接下来我们看看结果如何:
我们使用github上的新样本300个php马
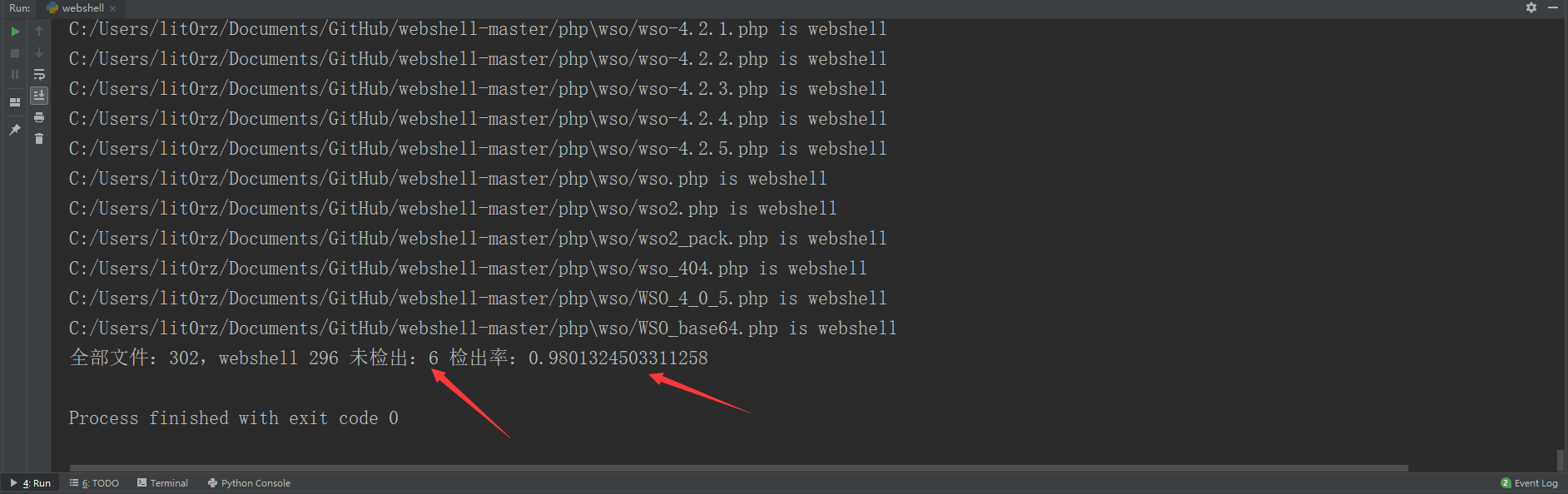
检出率正好是98。
我们检测一下正常文件试试:
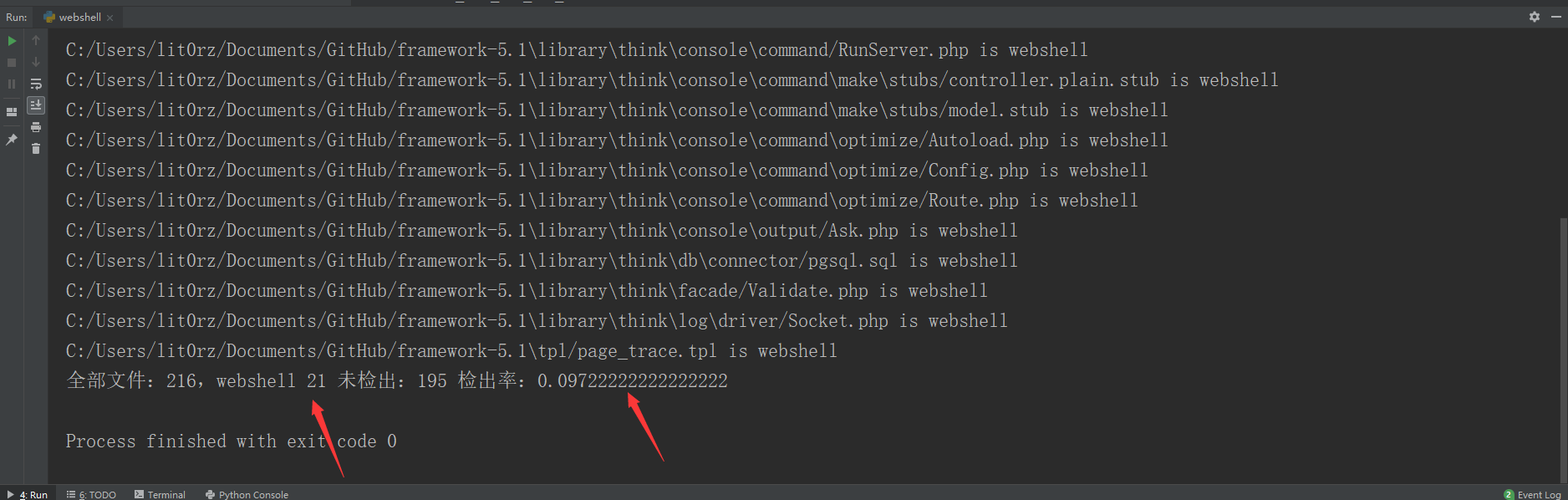
百分10的误报。
step4: 持久化
想要把上面的成果持久化就需要
from sklearn.externals import joblib或者
import pickle来实现,我们只介绍joblib的用法:
我们的代码有3个需要持久化的地方:
MLPClassifier对象
CountVectorizer对象
TfidfTransformer对象
于是简单的将他们dump下来:
joblib.dump(clf, "mlp.pkl")
joblib.dump(cv, "cv.pkl")
joblib.dump(transformer, "transformer.pkl")
好了,这样下次使用他们的时候就可以直接从硬盘加载而不需要重新训练,加载的方式同样简单:
像这样:
joblib.load("mlp.pkl")0x03 END
其他的语言也是一样,收集好样本经过算法的训练,将训练成果存储到本地就可以啦
所有的代码在https://github.com/zltningx/webshellgg
欢迎大家交流讨论,批评和指导
*本文原创作者:littt0,本文属FreeBuf原创奖励计划,未经许可禁止转载
来源:freebuf.com 2018-12-11 08:30:13 by: littt0























请登录后发表评论
注册