一 背景
人工智能经过了60多年的发展,其能力和影响力已经和当年不可同日而语。在人工智能的众多子领域之中,目前应用最广的无疑是机器学习。在大数据和大算力的催化下,机器学习在图像、语音、自然语言等领域绽放了丰硕的成果。这些成果就像向一池清水中投掷的石子,激起的涟漪渐渐地波及现实世界中的其它领域。
信息安全的一个重要的子领域是恶意代码检测。虽然恶意代码大部分是二进制格式,但是源代码格式也占有相当的比例,尤其是那些用脚本语言编写的恶意代码。
本文只是简要叙述一下机器学习在源代码分析上的一些应用,举出的应用实例并不全部是恶意源代码分析的实例。在掌握了源代码分析的方法后,只要有恶意源代码的样本,实施相关的分析必定是水到渠成。以下章节分述不同内容,在“前智能”中叙述一些使用传统的编程手段进行源代码分析的实例,在“特征提取”中叙述机器学习的“初级阶段”——主观特征提取的方法,在“向量化”中叙述几个最早在自然语言处理中提出方法,最后在模型中叙述专门针对源代码分析的模型。
二 前智能
在没有人工智能的情况下,如果要检验源代码是否有恶意行为,该怎么实现呢?
一种常见的方法是使用正则表达式匹配。程序员分析源代码,找出规律,写出类似下面的这些规则:
‘(array_map[\s\n]{0,20}\(.{1,5}(eval|assert|ass\\x65rt).{1,20}\$_(GET|POST|REQUEST).{0,15})’
‘(call_user_func[\s\n]{0,25}\(.{0,25}\$_(GET|POST|REQUEST).{0,15})’
‘(\$_(GET|POST|REQUEST)\[.{0,15}\]\s{0,10}\(\s{0,10}\$_(GET|POST|REQUEST).{0,15})’
‘((\$(_(GET|POST|REQUEST|SESSION|SERVER)(\[[\'”]{0,1})\w{1,12}([\'”]{0,1}\])|\w{1,10}))[\s\n]{0,20}\([\s\n]{0,20}(@{0,1}\$(_(GET|POST|REQUEST|SESSION|SERVER)(\[[\'”]{0,1})\w{1,12}([\'”]{0,1}\])|\w{1,10}))[\s\n]{0,5}\))’
‘\s{0,10}=\s{0,10}[{@]{0,2}(\$_(GET|POST|REQUEST)|file_get_contents|str_replace|[“\’]a[“\’]\.[“\’]s[“\’]\.|[“\’]e[“\’]\.[“\’]v[“\’]\.|[“\’]ass[“\’]\.).{0,10}’
……
然后对待检程序实施正则匹配,如果有规则被匹配上了,就认为源代码中存在恶意代码。
另一种不那么常见的方法是使用信息熵[1]。信息熵是用来表示数据中信息量多少的一个概念。熵是热力学中的一个概念,信息论的奠基人香农借用了这个概念创造出了信息熵,其计算公式为:
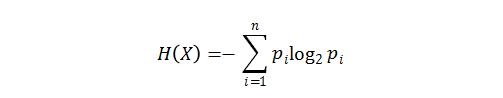
其中,信源符号X有n种取值,每个取值对应的概率为:P1…Pi…Pn。NeoPI[1]是一种利用信息熵检测Webshell的方法,它基于如下假设,恶意代码大都被编码过,编码后的内容和编码前的内容在信息熵上差别很大。
再列举一种用于检测文件相似性的方法——模糊哈希[2]。模糊哈希算法又叫基于内容分割的分片分片哈希算法(context triggered piecewise hashing, CTPH),主要用于文件的相似性比较。
模糊哈希的主要原理是,使用一个弱哈希计算文件局部内容,在特定条件下对文件进行分片,然后使用一个强哈希对文件每片计算哈希值,取这些值的一部分并连接起来,与分片条件一起构成一个模糊哈希结果。使用一个字符串相似性对比算法判断两个模糊哈希值的相似度有多少,从而判断两个文件的相似程度。
上面提到的几种方法实际上都是基于子节流的。在这些方法下,源代码就是一堆子节,没有词的概念,没有语法结构,更没有语义。这个特点限制了上述方法不能做一些“智能”的事情,比如给出一段代码“预测”以下这段代码是干什么的。这个特点也有好处,简单直接,运算速度快,编程实现也相对容易。
三 特征提取
运用机器学习解决问题的第一步就是特征提取,只不过有些特征提取是在不知不觉中进行的,有些则是需要人工参与。前者被称为“客观”特征提取,后者是“主观”特征提取。本节介绍“主观”特征提取,后续章节介绍“客观”特征提取。
举一个例子,在[3]中为了检测PHP语言的Webshell,使用了下面这些特征:
| 文档特征 | 基本特征 | 高级特征 |
|---|---|---|
| 1. 单词数量2. 不同单词的数量3. 行数4. 平均每行单词数量5. 空字符和空格的数量6. 最大单词长度 | 1. 注释数量2. 字符操作函数数量3. 执行类函数(eval、exec、shell_exec、system)调用次数4. 系统函数调用数量5. 脚本区块数6. 函数参数的最大长度7. 加解密函数调用数量 | 1. 文件操作数量2. ftp操作数量3. 数据库操作数量4. ActiveX控件调用数量 |
“主观”特征提取需要领域知识专家的参与,在选取属性时,主观随意性比较大。不同的专家选取的特征一般不会完全相同,选取的过程很难标准化。这种做法的好处是其可解释性较好,特征数量一般也不会太多,这导致特征提取后的向量维数不大,利于计算。
不管怎么说,“主观”特征提取让程序员开始了解和使用机器学习这个强大的工具。虽然这种使用工具的方法还有些死板,不能灵活变化,就像“剪刀手爱德华”的剪刀,用来剪草得心应手,拥抱女朋友就失之笨拙了。
 理想的情况是像电影《阿丽塔:战斗天使》中的机器狗,召之即来,挥之即去,自主工作。
理想的情况是像电影《阿丽塔:战斗天使》中的机器狗,召之即来,挥之即去,自主工作。

四 向量化
本节介绍“客观”特征提取。这种方法的特点是使用预先定义的模型或程序对输入进行运算,运算的结果是一定维度的向量。所以这种方法又被称作向量化。实际上,使用这种方法在很多情况下是观察不到特征的,特征在模型里“自产自销”了,使用者只能看到模型的输入和输出。下面列出几种自然语言处理领域的向量化方法。
a.N-Grams
前些天,在一个与机器翻译相关的研讨会上,一位做企业的嘉宾感慨:“为什么深度学习在自然语言处理上用得这么晚,总要借鉴别的领域的成果呢?”此话一出口立刻招来了在座的一位大学教授的批驳:“不是啊,N-Grams就是首先应用在NLP,然后才在语音和图像上用的呀。”由此可见N-Grams[4]的经典地位。
假设一段文本序列:
S = w1, w2, …, wT
1、w2、……、wT是文本序列S中的词。这段文本的出现概率为:
![]()
上面这个概率公式没有什么实际意义,因为运算成本太高了。N-Grams对其进行简化,取近似值。N-Grams认为第n个单词的出现只和前n-1个单词有关,公式简化为:
![]()
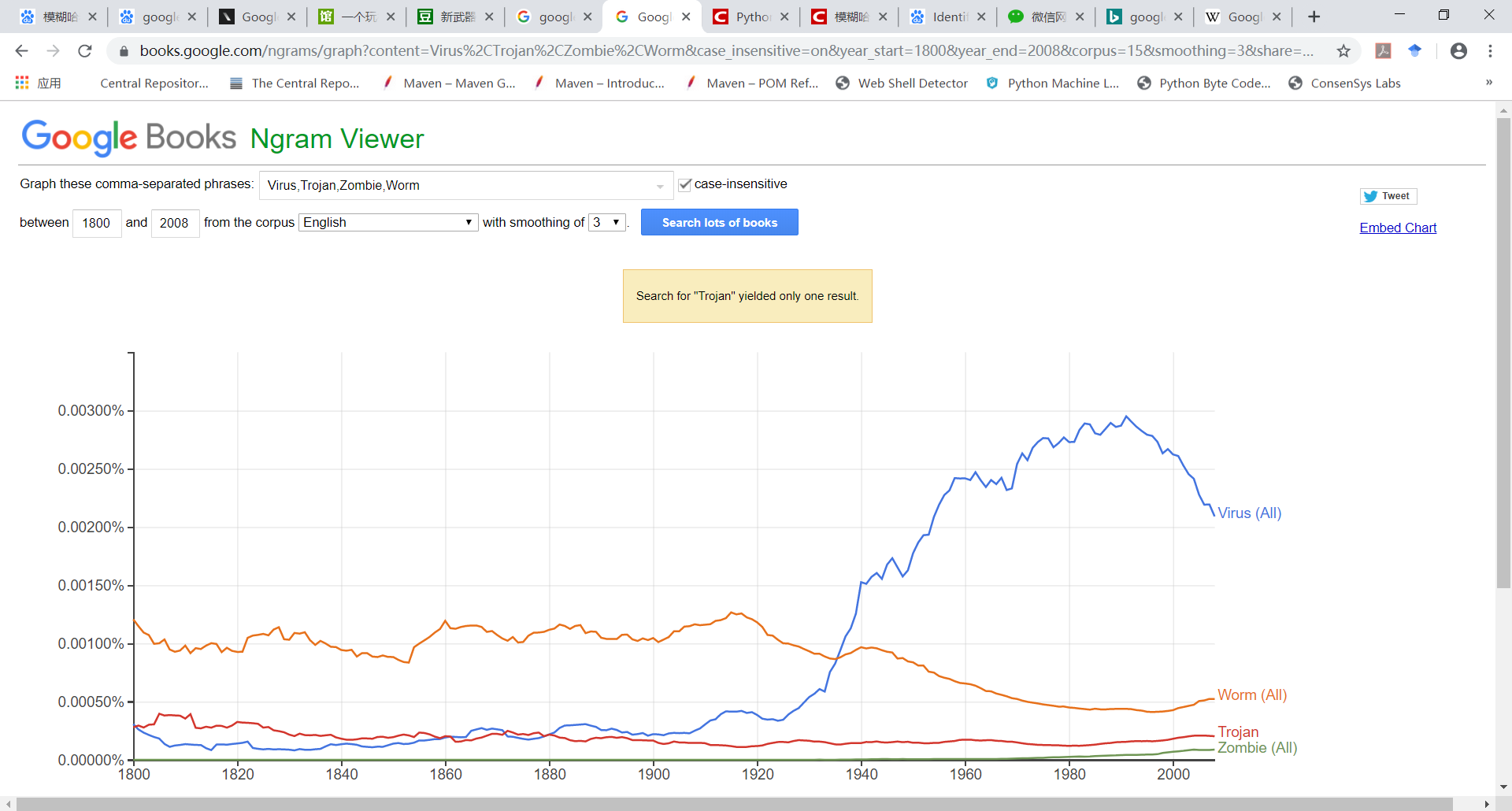
下面看一个N-Grams的使用实例。2004 年,Google 启动宏大的Google Books工程,宣布与美国纽约公共图书馆、哈佛大学图书馆、斯坦福大学图书馆、牛津大学图书馆等多家大型图书馆合作,将馆藏的纸质书籍扫描后存储在数据库之中。Google Books打造了人类最大最全的图书库,实现了公共资源的最大化利用。2010年底,Google向公众发布了基于Google Books的Google Ngram Viewer。通过Google Ngram Viewer可以查询不同词和词组在历年图书中的出现频率。在Google Ngram Viewer上随意试验了“Virus”、“Worm”、“Trojan”、“Zombie”这几个词,其词频显示“Virus”的使用频率在1970年以后有大幅度增长,过了2000年,其使用频率呈现线性下降趋势。这种变化应该和生物学上的病毒没什么关系。可惜,Google Ngram Viewer背后的Google Books数据截止到2009年,所以像“Advanced Persistent Threat”是查不到的。
b.CRF
Conditional Random Field[5]简称CRF,中文翻译为条件随机场。CRF涉及统计学知识,理解起来有些难度。下面简述CRF所涉及的概念。
1. 图:图是由结点和边组成的**,结点和边分别记作v和e,结点和边的**分别记作V和E,图记作G=(V,E)。
2. 随机场:随机场就是指一组随机变量的**,这些随机变量之间存在依赖关系。
3. 马尔科夫独立性假设:马尔科夫独立性假设是指,对于一个节点,在给定它所连接的所有节点的前提下,它和外界是独立的。也就是说和它没有连接的节点对它不会有影响。
4. 马尔科夫随机场:随机场+马尔科夫独立性假说=马尔科夫随机场。马尔科夫随机场就是遵循着马尔科夫独立性假说的随机场。
5. 全局马尔科夫性:设结点**A,B是在无向图G中被结点**C分开的结点**,
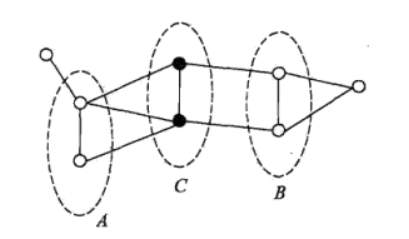 结点**A,B,C对应的随机变量组分别是YA,YB,YC,全局马尔科夫性指的是在给定随机变量YC的条件下随机变量YA和YB是条件独立的!用公式表示就是:
结点**A,B,C对应的随机变量组分别是YA,YB,YC,全局马尔科夫性指的是在给定随机变量YC的条件下随机变量YA和YB是条件独立的!用公式表示就是:
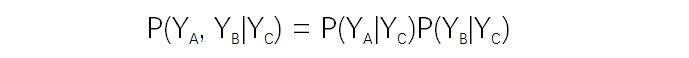
6. 概率无向图模型:设有联合概率分布P(Y),由无向图G=(V,E)表示。在图G中,结点表示随机变量,边表示随机变量之间的依赖关系,如果联合概率分布P(Y)满足全局马尔科夫性,那么就称此联合概率分布为概率无向图模型或者马尔科夫随机场!
有了以上的铺垫,马尔科夫随机场就等价于概率无向图。这样就将对随机变量的处理转换为对图的处理!之所以将马尔科夫随机场转换为概率无向图主要是因为概率无向图可以进一步分解。下面是涉及图的几个概念:
7. 团和最大团: 无向图G中任何两个结点均有边连接的结点子集称之为团!若C是无向图G中的一个团,并且不能再加进任何一个G的结点使其成为一个更大的团,则称此C为最大团!
举个例子:
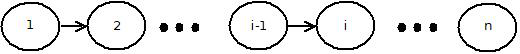
n为句子的长度。句子中第i个词的词性概率只与第i-1个词的词性概率相关。
下面定义若干个词性标注序列,比如“名词,动词,名词,介词,名词”是一种标注序列,“名词,动词,动词,介词,名词”是另一种标注序列。再定义若干标注特征函数,标注特征函数决定相邻两个词的词性标注评分。用i表示词的位置,li表示第i个单词,li-1表示第i-1个单词。举两个例子,f3和f4是词性标注函数:
当li-1是介词,li是名词时,f3 = 1,其他情况f3=0。
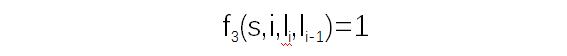 当li-1和li都是介词,f4=1,其他情况f4=0。
当li-1和li都是介词,f4=1,其他情况f4=0。
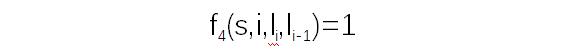 需要说明一点,这些标注特征函数是由样本训练而得出的。此外,还有权重值,这个权重在下面的公式中标记为λj,它也是经由训练而确定的。一个标注序列在一组词性标注函数下的分数为:
需要说明一点,这些标注特征函数是由样本训练而得出的。此外,还有权重值,这个权重在下面的公式中标记为λj,它也是经由训练而确定的。一个标注序列在一组词性标注函数下的分数为:![]()
l表示一个标注序列,s表示一个句子,λj表示一个标注函数的权重,fj表示一个标注函数,i表示词的位置,li表示第i个单词,li-1表示第i-1个单词。
下面计算各个标注序列的概率:
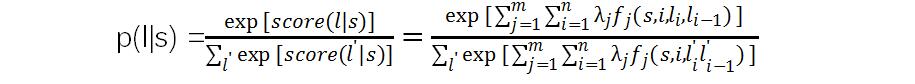
取概率最大的标注序列作为对这个句子的标注序列即可。
c. word2vec
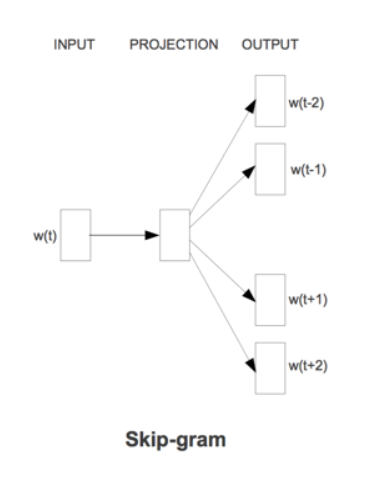
word2vec是2013年Google开源的一款用于词向量计算的工具。此工具具有开创性,为后续许多研究铺平了道路。word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练,而且该工具的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。关于word2vec有两个误区,很多人以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。此外,word2vec并不是一个模型,它包括用于计算word vector的CBoW模型和Skip-gram模型[6][7]。
首先看一下CBoW(Continuous Bag-of-Words Model)模型:
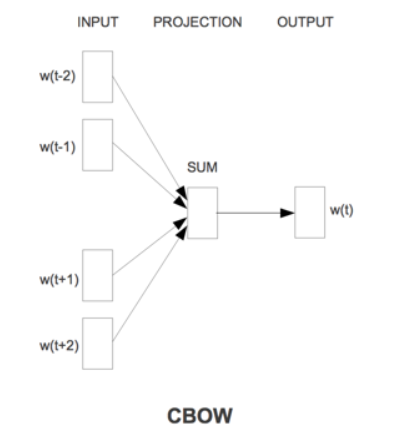 CBoW模型是输入词的上文和下文,预测被上文和下文环绕的词。Skip-gram模型与之相反,输入词,输出上下文。
CBoW模型是输入词的上文和下文,预测被上文和下文环绕的词。Skip-gram模型与之相反,输入词,输出上下文。
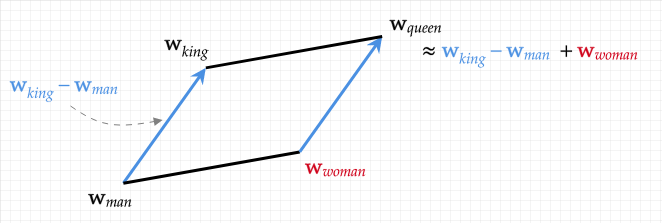
word2vec生成的向量可以很好的度量词与词之间的关系。著名的例子是:
queen = king – man + woman
五 模型
程序语言与自然语言有很多共同点,所以针对程序语言进行分析可以直接使用自然语言处理中用到的成熟模型。但是相比于自然语言,程序语言有两个特点,一个是其具有结构性,另一个是它没有二义性。如果能针对程序语言的特点对程序进行某些预处理,那无疑会提高处理的效果和效率。
文献[8]给出了一种利用N-Grams检测PHP Webshell的方法。其原理是先利用PHP VLD工具对PHP代码进行编译,得到OP CODE序列,然后使用N-Grams统计不同OP CODE排列的出现频率,将这些频率数据组成向量输入到机器学习分类器。
文献[9]给出了一个利用CRF为程序中的变量重新命名的方法。
 对上面这段JavaScript程序进行分析,得到未知元素的**和已知元素的**:
对上面这段JavaScript程序进行分析,得到未知元素的**和已知元素的**:
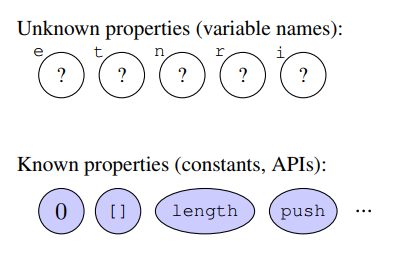
程序中的变量是e、t、n、r、i,它们被视为未知属性,常量和函数名是0、11、length、push,它们被视为已知属性。下面就要从已知推定出未知的值。先从程序推导出依赖关系图。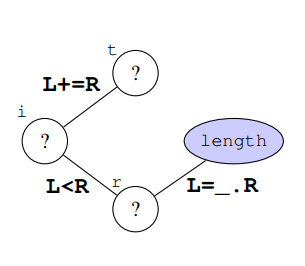
再依靠以前训练而得出的分值表,确定出图c中“?”部分的值,从而为程序的变量重新命名。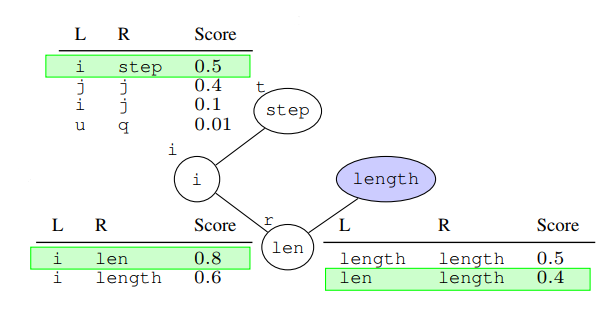
最后的修正过的程序为:
随着研究的深入,也有些研究者不再满足于移植自然语言处理领域的成熟方法,比如文献[10]提供了一种全新的处理方法。这种方法利用了编译器所生成的抽象语法树。编译工作一般会分为很多阶段,机器学习应用于源代码处理的比较常见的做法是利用编译的一种中间结果——抽象语法树(Abstract Syntax Tree, AST)。下面是一个AST的例子,上半部分是一段Java代码,下半部分是编译代码生成的AST:
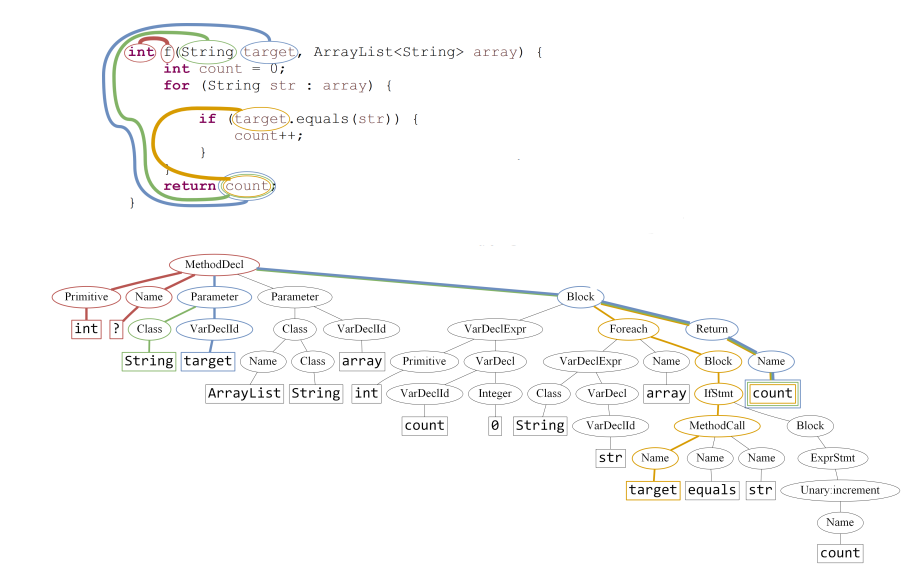
AST的叶结点和叶结点之间存在路径。比如针对“target.equals(str)”,其子树是:
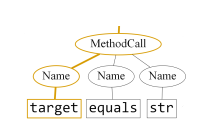
产生的全部路径为(target, (Name↑MethodCall↓Name), str)(target, (Name↑MethodCall↓Name), equals)(equals, (Name↑MethodCall↓Name), str)(str, (Name↑MethodCall↓Name), target)(equals, (Name↑MethodCall↓Name), target)(str, (Name↑MethodCall↓Name), equals)路径由3部分组成,第一部分和第三部分是叶节点,第二部分是非叶节点和“方向”组成的串,↑表示向上,↓表示向下。下面对path进行编码:
![]()
其中value是指叶节点,path是指中间节点组成的子路径。它们的编码分别为:

d是一个经验参数。|X|是所有叶节点(终端符号)值的数量,|P|是中间节点路径的数量。这样,对一条全路径进行编码后而得到的向量的维数就是3d。将这个表示全路径的3d维的向量输入到下面这个神经网络中,其输出是对代码用途的预测:
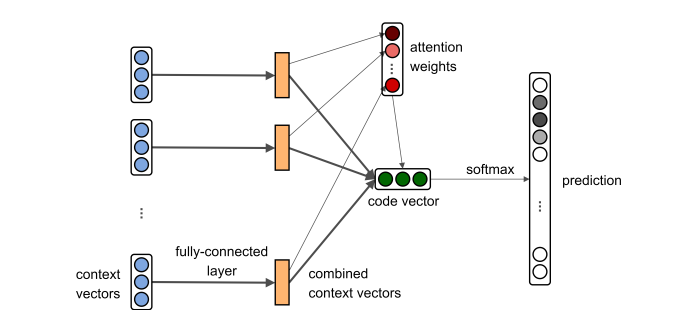 这个神经网络模型还是比较简单的。首先是一个全连接层,全连接层的作用抽象成下面这个数学公式:
这个神经网络模型还是比较简单的。首先是一个全连接层,全连接层的作用抽象成下面这个数学公式:
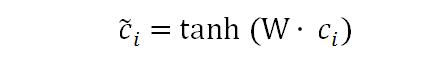
其中W∈Rd×3d,č被称为组合上下文向量(Combined Context Vectors)。全连接层的作用就是将3d维的上下文向量(context vectors)降维成d维的组合上下文向量(Combined Context Vectors)。
组合上下文向量可以导出两个向量,第一个是注意力(attention)向量。产生方法是先初始化注意力向量为随机值,然后逐渐调优。通过注意力向量,可以计算出不同输入的权重。假设n个组合上下文向量{č1,č2,…,čn},每个向量的注意力权重(attention weight)ɑi的计算公式为:
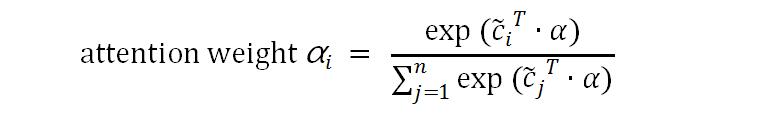 组合上下文导出第二个向量是聚合代码向量(aggregated code vector)v,v∈Rd。假设输入的源代码产生了n个全路径,这n个全路径产生了n个组合上下文{č1,č2,…,čn}。由这n个组合上下文生成聚合代码的公式为:
组合上下文导出第二个向量是聚合代码向量(aggregated code vector)v,v∈Rd。假设输入的源代码产生了n个全路径,这n个全路径产生了n个组合上下文{č1,č2,…,čn}。由这n个组合上下文生成聚合代码的公式为: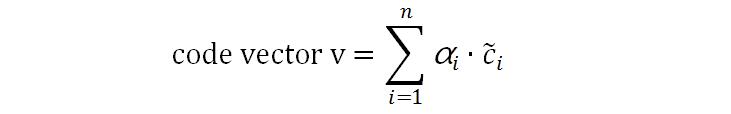 最后,进行预测。假设标签矩阵tags_vocab∈R|Y|×d,预测代码归为哪个标签的方法是:
最后,进行预测。假设标签矩阵tags_vocab∈R|Y|×d,预测代码归为哪个标签的方法是:
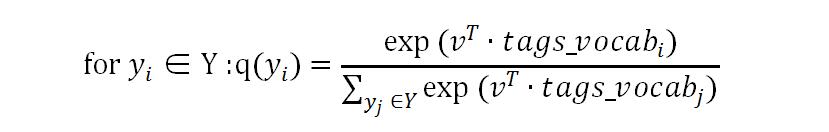 取概率数值q最大的标签作为这段代码的标签即可。
取概率数值q最大的标签作为这段代码的标签即可。
六 总结
计算机自1946年诞生以来,在短短70多年的时间里,一批批程序员累计创造了难以计数的程序。如何对这些程序进行有效管理?如何快速找出程序的错误,如何定位程序的安全问题,如何度量程序与程序之间的相似性,如何确定程序的用途……这是一个大题目。在这个大领域中已经有了许多解决方案,也必将产生更多的解决方案。程序分为两种形态:源程序和目标代码。本文只简述了对源程序实施分析的一些方法。回顾上面章节提到的方法,有一个有趣的发现,那就是对源程序的分析方式其实取决于该如何看待源程序。如果源程序被看作一堆字节的“流”,那么可用的方法就包括正则匹配、信息熵、和模糊哈希;如果源程序被看作一堆词的排列,那么可用的工具就包括N-Grams、CRF和word2vec;如果源程序被看作是满足语法架构的词的排列,那么开发者就可以在抽象语法树的基础上使用N-Grams、CRF、word2vec、以及特定的浅层神经网络模型。从字节到词,再从词到抽象语法树,对源程序的分析越来越接近程序语言的本质,与此同时,处理方法也逐渐复杂。当使用正则匹配时,开发者可以开发出一个通吃所有程序语言的万能工具,因为所有程序首先都是字节流。但是,开发者可能需要时常更新匹配规则。当使用基于抽象语法树的机器学习技术时,开发者可能只要定期用新的样本去训练他的模型就可以了,模型可以自己去寻找规则。但是在享受高准确率和工具的自适应性的同时,开发者要面对另一个现实:程序语言有很多种,他/她要为每种想要支持的程序语言开发一个前端编译器。程序语言有两个不同于自然语言的特点,一个是内在的结构性,这体现为程序语言严格的语法;另一个是无歧义性,这体现为程序语言的语义。业界已有基于语义的实施源程序分析的实现。这种实现比基于语法的实现还要复杂。本文没有把这方面的研究成果包括进来。应用机器学习的第一步是将问题转化为特征向量。本文首先介绍的是特征提取的“初级阶段”——“主观”特征提取。这种提取方法依赖开发人员的知识和经验,其所提取的特征可以是字节级别的,可以是词法级别的,可以是语法级别的,甚至可以是语义级别的。然后本文介绍了几种自然语言处理处理领域的经典方法,这些方法都是词法级别上的向量化方法:N-Grams、CRF、和word2vec。最后,本文介绍了如何在语法级别上进行向量化,这就引入了抽象语法树,以及对抽象语法树的处理:路径(path)和注意力(attention)。本文在向量化之后的学习模型上的介绍并不多,只在最后介绍了一个颇具独创性的浅层全连接网络。
参考资料
[1]. https://github.com/Neohapsis/NeoPI
[2]. Kornblum J . Identifying almost identical files using context triggered piecewise hashing[J]. Digital Investigation, 2006, 3(supp-S):91-97.
[3]. 胡建康[1], 徐震[1], 马多贺[1], et al. 基于决策树的Webshell检测方法研究[J]. 网络新媒体技术, 2012, 1(6):15-19.
[4]. A statistical interpretation of term specificity and its application in retrieval. S Jones,2004
[5]. Lafferty J, Mccallum A, Pereira F C N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[J]. Proceedings of Icml, 2001, 3(2):282-289.
[6]. Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013a. Efficient Estimation of Word Representations in Vector Space. CoRR abs/1301.3781 (2013).
[7]. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013b. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS’13). Curran Associates Inc., USA, 3111–3119.
[8]. 胥小波, 聂小明. 基于多层感知器神经网络的WebShell检测方法[J]. 通信技术, 2018, 51(4): 895-900.
[9]. Raychev V , Vechev M , Krause A . Predicting program properties from “big code”.[C]// Acm Sigplan-sigact Symposium on Principles of Programming Languages. ACM, 2015.
[10]. Alon U , Zilberstein M , Levy O , et al. code2vec: Learning Distributed Representations of Code[J]. 2018.

来源:freebuf.com 2019-09-30 18:11:03 by: 东巽科技2046Lab























请登录后发表评论
注册