一、正则表达式和状态机
(1)增长的正则表达式
正则表达式描述了一种字符串匹配模式,可以用来检查一个串是否含有某种子串。随着网络建设的推进和发展,网络攻击的多样化和复杂性随之增长,防御规则随之增加,而防御规则离不开正则表达式,在引擎语义和功能覆盖不全面的情况下想要做到全面防御,灵活的匹配效果使得正则表达式成为最佳选择。正则匹配一般过程如下图:
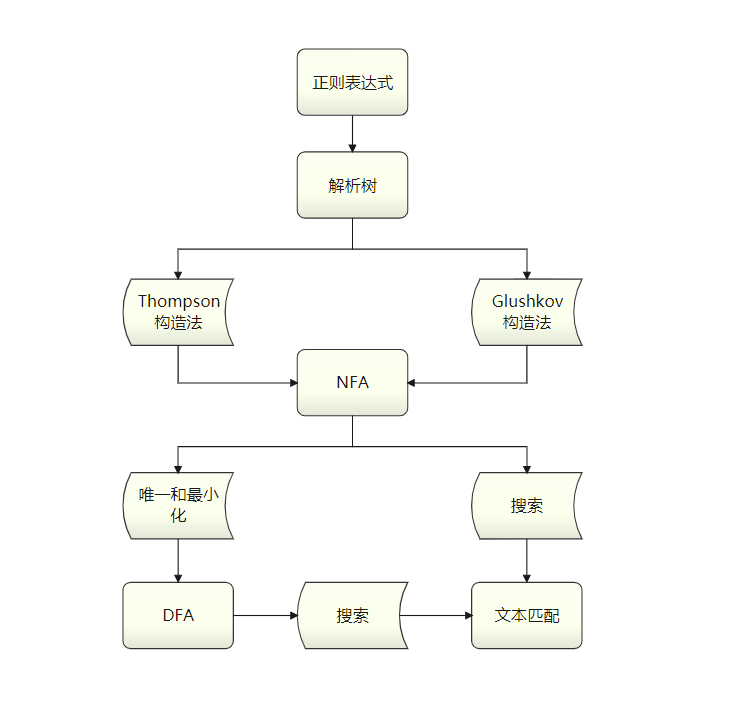
图1
(2)NFA和DFA
NFA:非确定有限状态自动机或非确定有限自动机(NFA)是对每个状态和输入符号对可以有多个可能的下一个状态的有限状态自动机。
DFA:确定有限状态自动机或确定有限自动机(英语:deterministic finite automaton, DFA)是一个能实现状态转移的自动机。它的下一个可能状态是唯一确定的,区别于NFA。
DFA是由:
-
一个非空有限的状态集合
-
一个输入字母表(非空有限的字符集合)
-
一个转移函数
-
一个开始状态
-
一个接受状态的集合
所组成的5元组。
(3)状态图举例
-
举例构造NFA:
对于一个给定的DFA,存在唯一一个对应的有向图,有向图的每个结点对应一个状态,每条有向边对应一种转移。
我们举个例子:attack(p|o|c)*poc
它的NFA状态图如下:
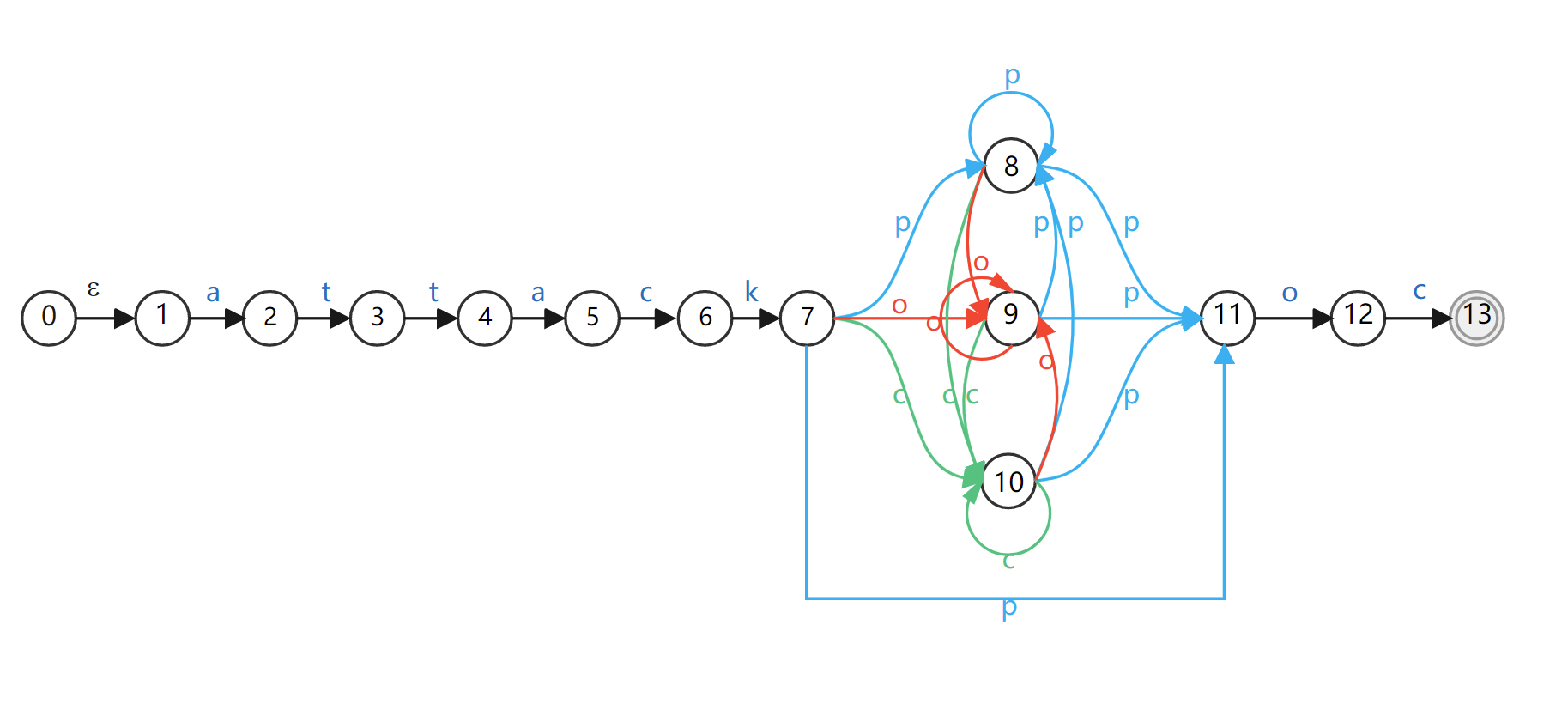
图2 正则”attack(p|o|c)*poc”的NFA状态图 -
构造DFA:
将例子attack(p|o|c)*poc通过子集构造法转化为DFA:
-
生成状态表:
根据图2 生成状态表:
|
状态子集 |
a |
t |
c |
k |
p |
o |
|
→○{0,1} |
{2} |
|||||
|
○{2} |
{3} |
|||||
|
○{3} |
{4} |
|||||
|
○{4} |
{5} |
|||||
|
○{5} |
{6} |
|||||
|
○{6} |
{7} |
|||||
|
○{7} |
{10} |
{8,11} |
{9} |
|||
|
○{9} |
{10} |
{8,11} |
{9} |
|||
|
○{10} |
{10} |
{8,11} |
{9} |
|||
|
○{8,11} |
{10} |
{8,11} |
{9,12} |
|||
|
○{9,12} |
{10,13} |
{8,11} |
{9} |
|||
|
◎{10,13} |
{10} |
{8,11} |
{9} |
表一
-
重新编号
用状态编号替代表中的状态集,得到新的状态表格:
→○0:{0,1}
○1:{2}
○2:{3}
○3:{4}
○4:{5}
○5:{6}
○6:{7}
○7:{9}
○8:{10}
○9:{8,11}
○10:{9,12}
◎11:{10,13}
|
状态编号 |
a |
t |
c |
k |
p |
o |
|
→○0 |
1 |
|||||
|
○1 |
2 |
|||||
|
○2 |
3 |
|||||
|
○3 |
4 |
|||||
|
○4 |
5 |
|||||
|
○5 |
6 |
|||||
|
○6 |
8 |
9 |
7 |
|||
|
○7 |
8 |
9 |
7 |
|||
|
○8 |
8 |
9 |
7 |
|||
|
○9 |
8 |
9 |
10 |
|||
|
○10 |
11 |
9 |
7 |
|||
|
◎11 |
8 |
9 |
7 |
表二
-
画DFA
根据唯一性,画出DFA:(结束状态的NFA到DFA必须是结束状态)
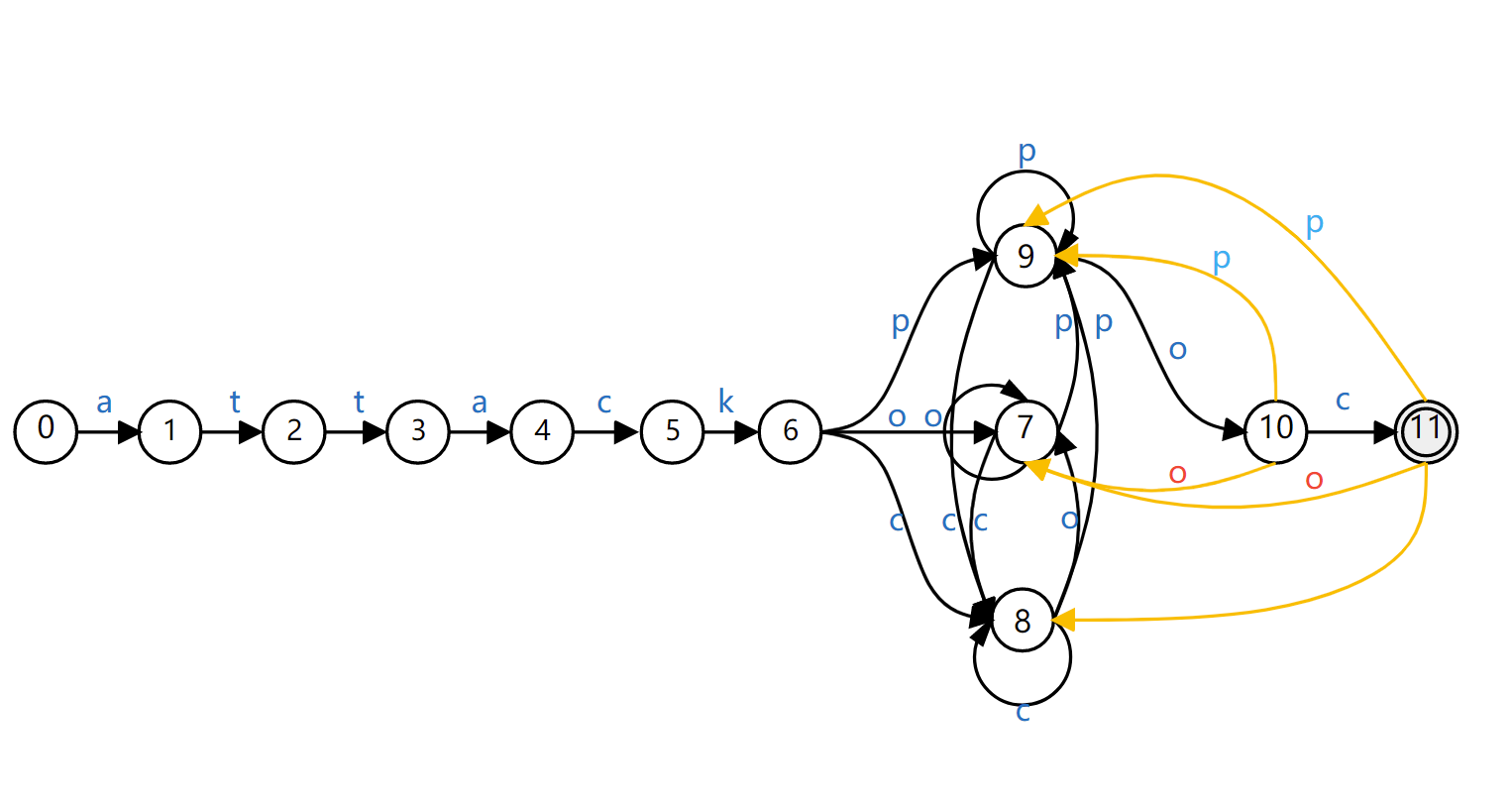
图3 正则”attack(p|o|c)*poc”的dfa状态图
attack(p|o|c)*poc 生成的NFA状态图到attack(p|o|c)*poc 的DFA状态图构造完成,我们得到的DFA与图2的NFA等价。
二、状态膨胀和举例说明
(1)状态膨胀
对于 DFA,由于每个状态对一个给定的输入字符只有一个跳转边,在匹配过程中的任意时刻 DFA 的活跃状态只有一个。这带来了确定化的 O(1) 的访存带宽需求。[1]但是 NFA 到 DFA 的转换过程会引入状态膨胀,甚至是状态爆炸。如果一个 NFA 有 n 个状态,则对应的 DFA状态数在最坏的情况下可能有 2n。例如,Snort 中用于探测 IMAP 认证溢出攻击的特征 “AUTH\s[ˆ\n]{100}” 对应的 DFA 状态数超过 1013。[1]同时编译多条正则表达式时,这个问题会变得更加复杂。几十条正则表达式的空间开销可以达到 50 GB。[1]下表总结了在最坏情况下 NFA 和 DFA 在空间开销和匹配时间复杂度上的对比:
| m条长度为n的正则式分开编译成m个自动机 | m条长度为n的正则式分开编译成一个自动机 | |||
| 匹配时间复杂度 | 空间复杂度 | 匹配时间复杂度 | 空间复杂度 | |
| NFA |
O(mn²) |
O(mn) | O(mn²) | O(mn) |
| DFA | O(m) | O(m2n) | O(1) |
O(2mn) |
表三
(2)以Snort规则为例来看状态膨胀
-
NFA示例:
我们使用两条Snort规则来看一下联合编译之后dfa状态的增长:
pcre:"/\x2Fpost\.php3?[^\r\n]*?root=[^\r\n\x26]*?union[^\r\n\x26]*select/";pcre:"/\x2Fpost\.php3?[^\r\n]*?parent=[^\r\n\x26]*?union[^\r\n\x26]*select/";
[^\r\n]*会产生254*254条状态边,会产生6万+的状态,我们看一下[^\r\n]*简化为[a-z0-9=&]*,[^\r\n\x26]*简化成[a-z0-9\’\”\;]*
pcre:"/\x2Fpost\.php3?[a-z0-9=&]*?root=[a-z0-9\'\"\;]*?union[a-z0-9\'\"\;]*select/";生成的NFA状态图:

图4
-
简化NFA
很多算法对此进行了简化,比如这里将[^\r\n]的254个字符压缩成一个符号集-符号集压缩:
pcre:"/\x2Fpost\.php3?[^\r\n]*?root=[^\r\n\x26]*?union[^\r\n\x26]*select/";简化后NFA状态图:
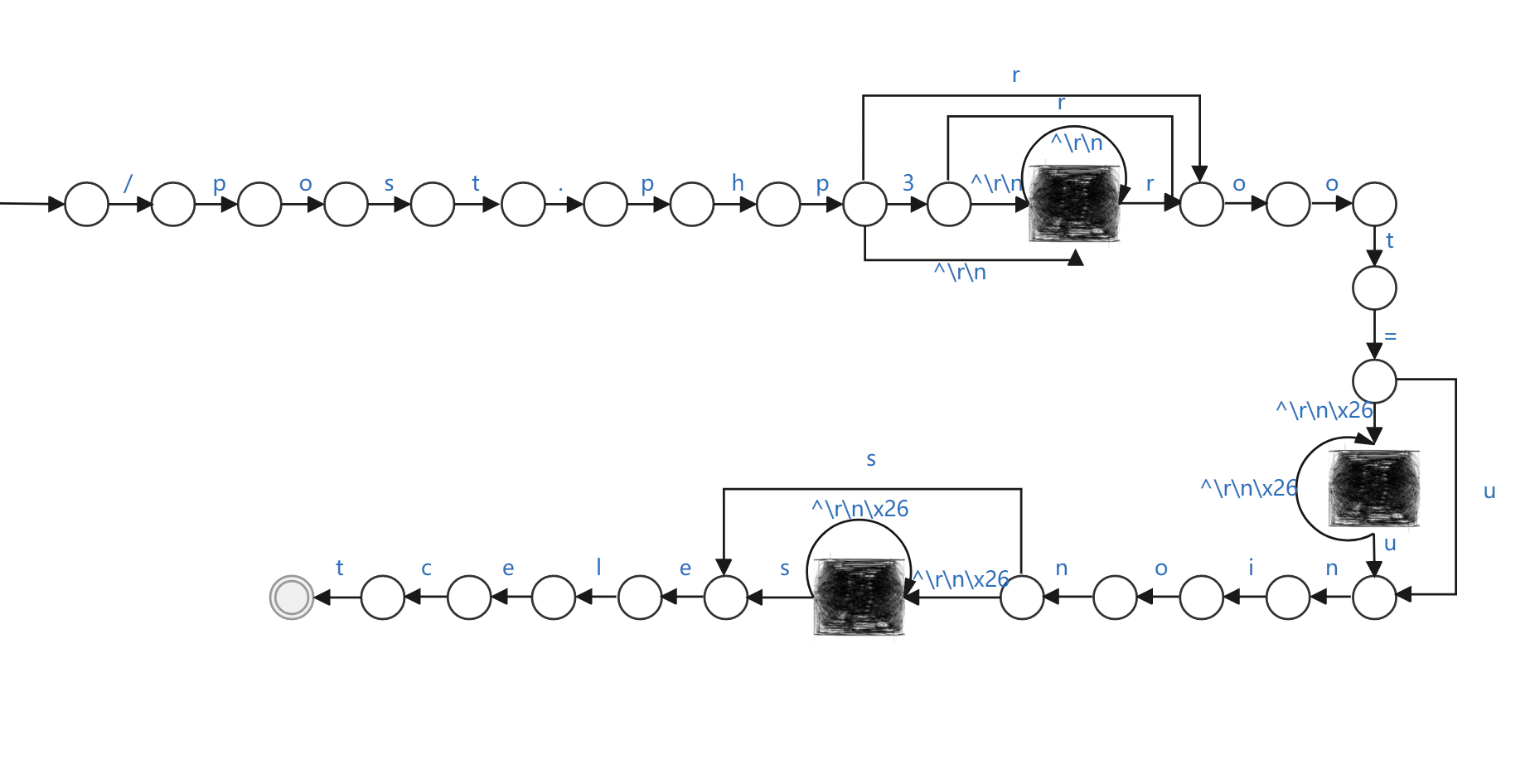
图5
-
生成DFA:
pcre:"/\x2Fpost\.php3?[^\r\n]*?root=[^\r\n\x26]*?union[^\r\n\x26]*select/";pcre:"/\x2Fpost\.php3?[^\r\n]*?parent=[^\r\n\x26]*?union[^\r\n\x26]*select/";
两条正规式单独生成DFA状态图:
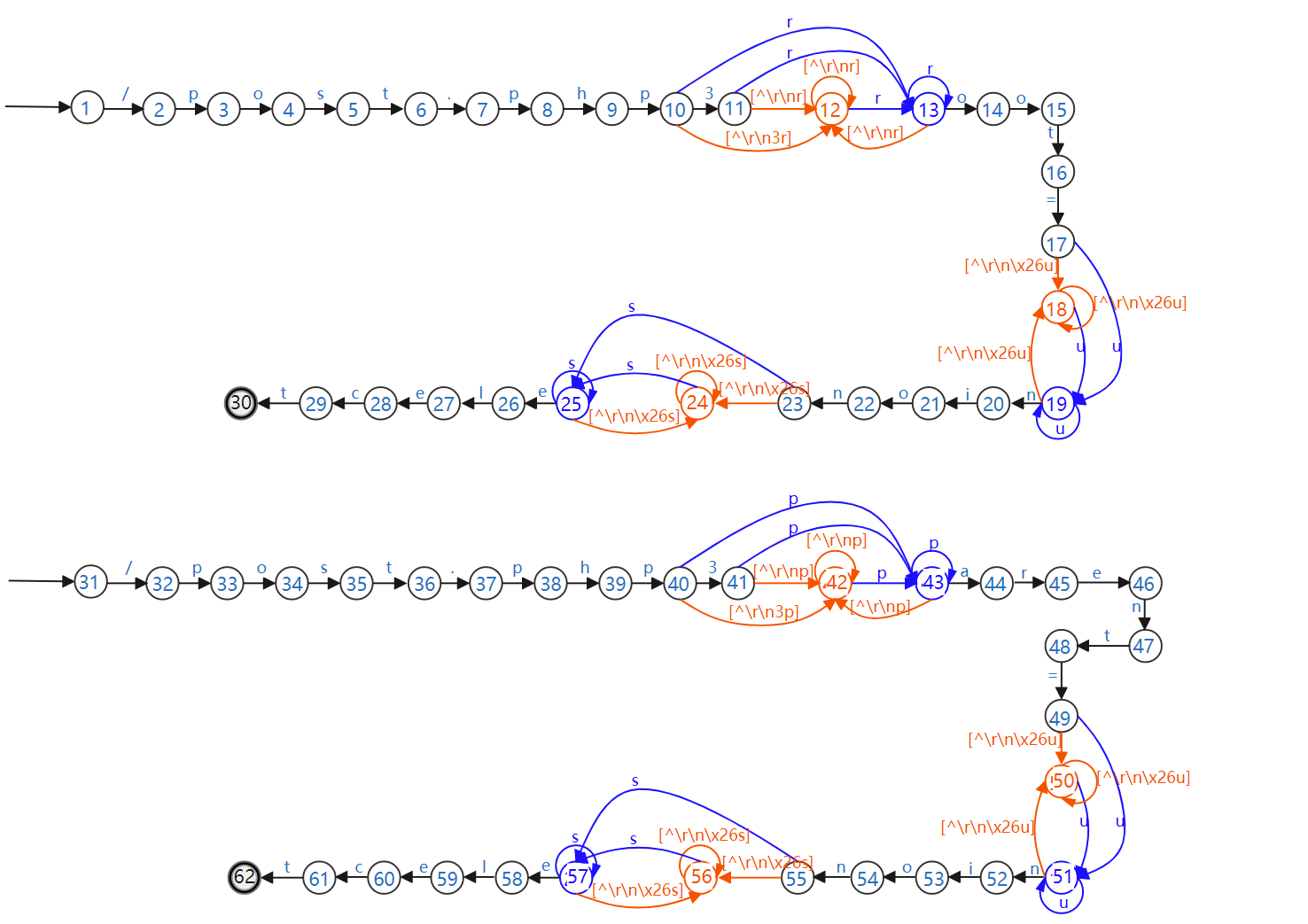
图6
-
联合产生的状态集和符号表:
根据以上DFA单独编译图,可以得到联合编译后的符号-状态集对的表格,我们可以看到DFA状态也就是DFA图中结点数的膨胀性增长:
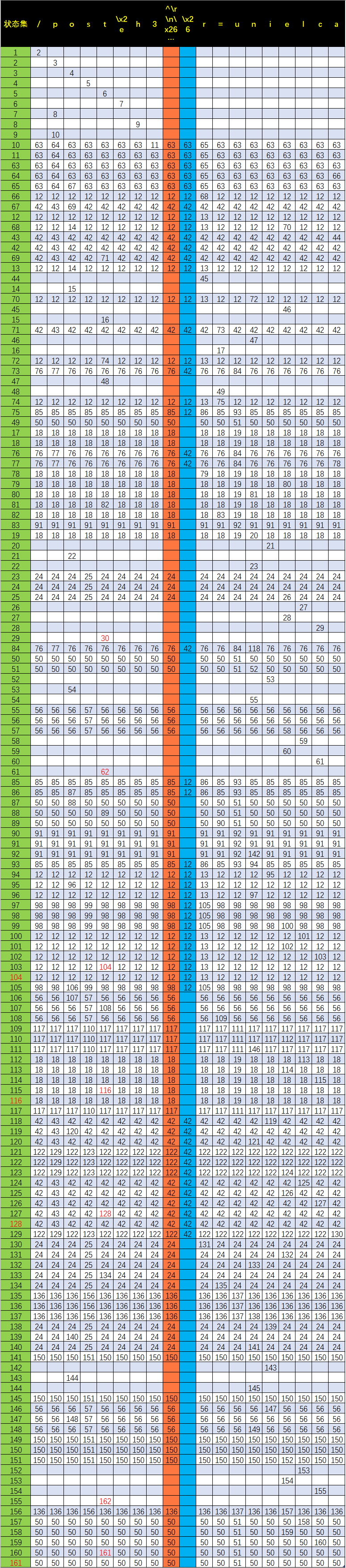
图7
-
联合编译DFA图:
如果将它们联合编译,根据图7的表生成的DFA如图,其中橙色结点是一类[]*表达式产生结点(DFA状态),黑色节点是单个字符产生结点(DFA状态),没有源的箭头指向起始位置,黑色绿实心结点(DFA状态)代表结束状态:
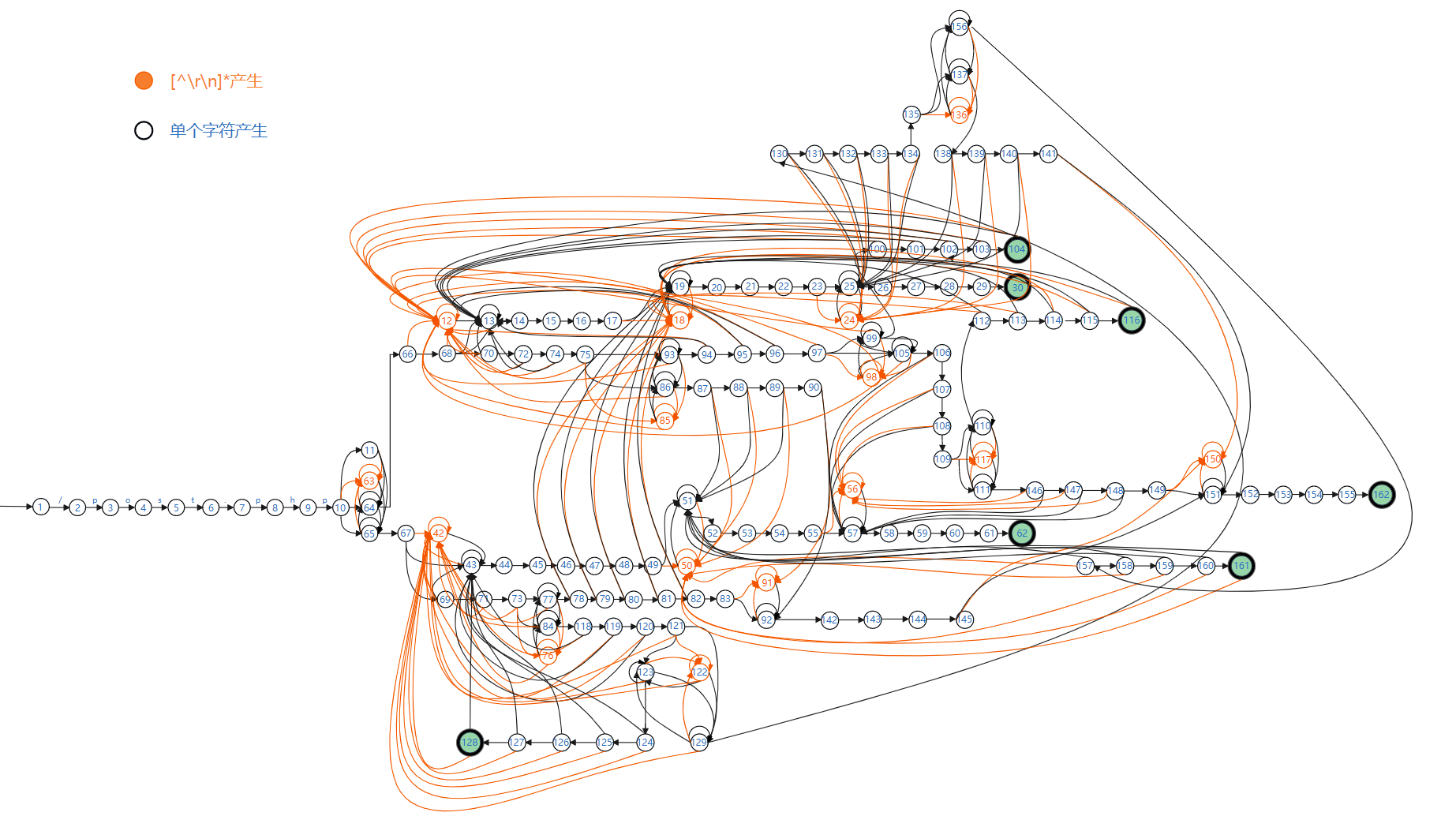
图8(此图略了符号和符号集)
DFA本身所占空间由DFA状态数和转移函数个数决定,图6和图8可以对比出当两个正则表达式联合编译产生的边数(转移函数)和结点数(DFA状态)的增长,其中橙色结点是表达式中[^\r\n]*和[^\r\n\x26]*所产生的DFA状态,可以直观的看到此类[]*表达式带来的状态增长和内存开销是膨胀性的。
三、如何兼顾性能
(1)书写正则表达式需要注意什么?
-
避免*和+;
-
^首锚:
下表示例了首锚^和.*开头带来的不同的空间复杂度:
规则特征 规则 空间复杂度 以首锚开始,n为限定长度,且字符集与规则前缀重叠 ^p+[a-z]{n}t O(n²)
以.*开始,n为限定长度,且字符集与规则前缀重叠 .*po[a-z]{n}t O(2n )
表四[1]
-
确定性:
{m,n}offset尽可能确定;
[XYZ]字符集尽可能确定,[\x20\x09]优于\s,[a-zA-Z]优于\w,减少字符集和前缀的重叠;
-
提取特征串特殊化:
有效区别于背景流;有效区别于其他规则;
-
pcre条目数越少越好;
-
少用或禁用贪婪模式
-
根据情况适当使用懒惰模式
-
减少分支选择
-
减少捕获嵌套
-
消灭性能极差规则;
(2)、其他软件和硬件技术
软件:fingerprint特征匹配技术;DFA、NFA混合技术,例如:Hybrid-FA;自动机压缩;可扩展自动机如:Offset-FA;
硬件:FPGA,GPU,TCAM
引:
[1] 徐成成,深度报文检测中的正则表达式匹配技术研究,June 14, 2018
转自奇安信网络平台安全团队微信公众号:天御云;作者: bricklayerz;
原文链接:
——————————————————————————————————————
转载声明:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
************有志于协议分析和攻防对抗的同学,欢迎砸简历到[email protected]************
来源:freebuf.com 2021-06-17 10:43:57 by: rockl




















请登录后发表评论
注册