最近进行MongoDB开发,虽然需求比较简单,但是涉及较多的细节使用。加之不够熟悉 就使用了各种方法达到目标。
## 1.简介
MongoDB是一个基于分布式文件存储的数据库,一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。支持比较丰富和复杂的数据类型。
MongoDB已经在多个站点部署,其主要场景如下:
1)网站实时数据处理。它非常适合实时的插入、更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
2)缓存。由于性能很高,它适合作为信息基础设施的缓存层。在系统重启之后,由它搭建的持久化缓存层可以避免下层的数据源过载。
3)高伸缩性的场景。非常适合由数十或数百台服务器组成的数据库,它的路线图中已经包含对MapReduce引擎的内置支持。
不适用的场景如下:
1)要求高度事务性的系统。
2)传统的商业智能应用。
3)复杂的跨文档(表)级联查询。
## 2.使用
### 连接和认证——方式一( MongoClient )
使用mongoclient的方式。MongoClient是线程安全的,可以在多程程环境中共享同一个MongoClient。通常来说,一个应用程序中,只需要生成一个全局的MongoClient实例,然后在程序的其他地方使用这个实例即可。
直接连接:
MongoClient mongoClient = new MongoClient(“localhost”, 27017); // 获取链接
MongoDatabase database = mongoClient.getDatabase(“mydb”); // 获取数据库
认证与连接:
MongoClientOptions.Builder builder = MongoClientOptions.builder(); //可以通过builder做各种详细配置 MongoClientOptions myOptions = builder.build();
ArrayList<ServerAddress> serverAddressList = new ArrayList();
ServerAddress record = new ServerAddress(“localhost”, 27017); //IP、端口
serverAddressList.add(record); //用户名、默认库名、密码
MongoCredential credential = MongoCredential.createCredential(“账号”, “默认库名”, “密码”.toCharArray());
MongoClient mongoClient = new MongoClient(serverAddressList, credential, myOptions);
### 连接和认证——方式二( MongoClientURI)
直接使用MongoClientURI完成MongoDB的认证,它代表了一个URI对象。MongoClientURI的构造函数接受一个String类型的字符串,这个字符串的格式如下:
String sURI = String.format(
“mongodb://%s:%s@%s:%d/%s”, ”用户名“, ”密码“, ”localhost“, 27017, ”数据库”);
MongoClientURI uri = new MongoClientURI(sURI);
MongoClient mongoClient = new MongoClient(uri);
DB db = mongoClient.getDB(“数据库”);
MongoClientOptions.Builder mongoBuilder = new MongoClientOptions.Builder(); mongoBuilder.maxWaitTime(1000*60*3);
mongoBuilder.connectTimeout(60*1000*3); //与数据库建立连接的timeout设置为1分钟 mongoBuilder.minConnectionsPerHost(1);
MongoClientURI mongoClientURI = new MongoClientURI(“mongodb://root:root@localhost:27017/数据库”,mongoBuilder);
SimpleMongoDbFactory mongoDbFactory = new SimpleMongoDbFactory(mongoClientURI); MongoTemplate mongoTemplate = new MongoTemplate(mongoDbFactory);
### 连接和认证——方式三( MongoTemplate)
public MongoClient mongoClient() {
MongoCredential credential = MongoCredential.createCredential(“用户”, “数据库”, “password”);
return MongoClients.create(
MongoClientSettings.builder()
.applyToClusterSettings(builder ->
builder.applyConnectionString(new ConnectionString(serverList)))
.credential(credential)
.applicationName(“应用”)
.readConcern(ReadConcern.MAJORITY)
.readPreference(ReadPreference.primaryPreferred())
.writeConcern(WriteConcern.MAJORITY)
.applyToConnectionPoolSettings(builder -> {
builder
.maxWaitTime(1, TimeUnit.SECONDS)
.maxSize(10);
})
.applyToSocketSettings(builder -> builder
.connectTimeout(5, TimeUnit.SECONDS)
.readTimeout(5, TimeUnit.SECONDS))
.build());
}
public MongoTemplate mongoTemplate() {
return new MongoTemplate(mongoClient(), “数据库”);
}
### CRUD——方式一
基于注解的方式:
1.实体上使用 @Document(collection = ”UserDO”)
2.继承MongoRepository,简单的增删改查无需实现,可直接使用
@Repository
public interface UserExtRepository extends MongoRepository<UserDO, String> {
List<UserDO> findById(String id);
}
xxRepository.insert(UserDO);
xxRepository. findBy(”11”);
Repositry接口
基础的 Repository提供了最基本的数据访问功能,其几个子接口则扩展了一些功能。它们的继承关系如下:
**Repository**:仅仅是一个标识,表明任何继承它的均为仓库接口类
**CrudRepository**:继承Repository,实现了一组CRUD相关的方法
**PagingAndSortingRepository**:继承CrudRepository,实现了一组分页排序相关的方法
**JpaRepository**:继承PagingAndSortingRepository,实现一组JPA规范相关的方法
自定义的XxxxRepository需要继承 JpaRepository,这样的XxxxRepository接口就具备了通用的数据访问控制层的能力。
**JpaSpecificationExecutor**:不属于Repository体系,实现一组JPACriteria查询相关的方法
### CRUD——方式二
增:
MongoCollection<Document> collection = mongo.getDb(“database”).getCollection(“CollectionName”);
Document document = Document.parse(JSONObject.toJSONString(userDO));
collection.insertOne(document);
collection.insertMany(document);
删:
MongoCollection<Document> collection = mongo.getDb(database).getCollection(“collection”);
BasicDBObject queryObject = new BasicDBObject(”id“,”1111“);
collection.deleteOne(queryObject);
collection.deleteMany(queryObject);
改:
MongoCollection<Document> collection = mongo.getDb(“database”).getCollection(“collection”);
BasicDBObject queryObject = new BasicDBObject(“id”,“1111”);
BasicDBObject updateNewOneSql = new BasicDBObject(“$set”, new BasicDBObject(“name”, “tom”));
collection.updateOne(queryObject, updateNewOneSql);
collection. updateMany();
collection. findOneAndUpdate();
查:
MongoCollection<Document> collection = mongo.getDb(database).getCollection(“collection”);
BasicDBObject queryObject = new BasicDBObject(”id“,”1111“);
FindIterable<Document> documents = collection.find(queryObject);
other:
collection.aggregate();//聚合索引
collection.countDocuments();//统计
collection.createIndex(); collection. dropIndex(); //增加删除索引
collection.createIndexs(); collection. dropIndexs(); //批量增加删除索引
collection.replaceOne();//替换文档
collection.distinct();//返回具有指定字段不同值的文档(去除指定字段的重复数据)
collection.bulkWrite();//批量写入
collection.dataSize();//返回集合大小
collection.drop(); //删除集合
聚合查询:
BasicDBObject query= new BasicDBObject();
BasicDBObject[] array = { new BasicDBObject(“time”, new BasicDBObject(“$gte”, “2018-09-12”)),new BasicDBObject(“time”, new BasicDBObject(“$lte”,”2018-12-25″))};
query.append(“$and”, array);
BasicDBObject match = new BasicDBObject(“$match”, query); // match(相当于 WHERE 或者 HAVING )
BasicDBObject group = new BasicDBObject(“$group”, new BasicDBObject(“_id”, “$subject”) //group(相当于 GROUP BY)
.append(“count”, new BasicDBObject(“$sum”, 1)));
BasicDBObject sort = new BasicDBObject(“$sort”, new BasicDBObject(“count”, -1));//1:正序,-1倒序
BasicDBObject limit = new BasicDBObject(“$limit”, pageSize); //limt(只要前多少条数据,分页时使用)
BasicDBObject skip = new BasicDBObject(“$skip”, xx); //skip(跳过前面多少条数据,分页时使用)
List<DBObject> queryList = new ArrayList<>(); //queryList集合里的顺序不能乱,否则会报错。
queryList .add(match);
queryList .add(group);
queryList .add(sort);
queryList .add(skip);
queryList .add(limit);
AggregateIterable<Document> iterable = mongoClient.mongoClient.getDatabase(dbName).getCollection(gatherName).aggregate(queryList );
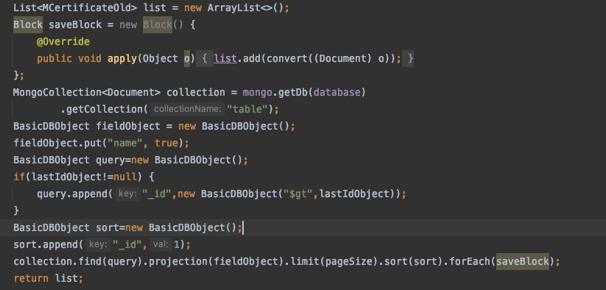
### CRUD——分页查询
方式一:使用limit和skip进行分页find().skip((pageNum-1)*pageSize).sort().limit(pageSize)
方式二:通过原生的方法实现条件查询、分页和排序
方式三:通过实现Pageable接口等方式做自定义实现
find(索引).projection(查询字段).sort().limit()
本文作者:琉璃@涂鸦智能安全团队
漏洞悬赏计划:涂鸦智能安全响应中心(https://src.tuya.com)欢迎白帽子来探索。
招聘内推计划:涵盖安全开发、安全测试、代码审计、安全合规等所有方面的岗位,简历投递[email protected],请注明来源。
来源:freebuf.com 2021-04-08 17:53:59 by: 是你的小凉凉呀



















请登录后发表评论
注册