设备指纹是用来标识手机或者浏览器的唯一 ID。基于这个 ID,我们能够精确定位一个设备,将使用该设备的全部数据进行关联。结合更加多样化的数据,黑产设备的识别准确性也将大幅提升。
设备指纹从何而来?一般而言,我们先在设备上集成一个 SDK,通过 SDK 采集设备多个维度的数据,选择其中一些能够唯一标识一台设备的数据,再利用一定算法生成设备指纹。
为了保证设备指纹的准确性,我们会选取唯一性和稳定性较高的字段来生成,并且要尽可能防止这些字段被恶意篡改而导致设备指纹发生变化。
01 如何判断设备指纹是否优质?
衡量设备指纹优劣的最重要指标是唯一性和稳定性。
唯一性:不同设备生成的设备指纹一定不会重复。这一指标帮助我们确认设备使用者身份的唯一性。如果设备指纹的唯一性不足,则可能导致不同设备的设备指纹发生碰撞,在一些风控策略较严格的场景下,可能会导致正常用户被误判。
稳定性:设备系统升级或少量数据变更时,设备指纹不会发生变化。如果设备指纹的稳定性不佳,则同一个设备的设备指纹一直变化,对黑产的识别效果会减弱。
02 如何生成设备指纹?
设备指纹生成算法是指根据采集的数据,利用一定的算法计算出一个值来标识该设备。其基本原理可根据概率论来解释。
2.1 单个字段条件概率分析
所谓设备指纹的唯一性,就是在已知某个设备数据的情况下,计算这个设备属于某个 Sid 的条件概率:
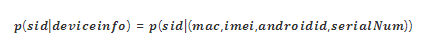
实际上,这里概率很难精确统计出来,但是可以根据大数据统计分析进行估算。当对总量1000w的数据进行统计时:
以 idfv 聚合统计为例,发现每个 idfv 都指向一个不同的设备,即知道 idfv 后,就能唯一确定是哪台设备。换而言之,idfv 的唯一性很高,其区分度等于100%,其条件概率如下:
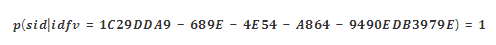
以 ip 为例,220.170.50.207这个 ip 指向208个不同的设备,即知道 ip 之后,还是有可能不能完全确定是哪个设备,但是范围已经从1千万缩小到208个,其区分度相对较低,其条件概率如下:
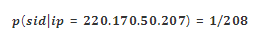
2.2 多个字段组合的条件概率分布
上文直观地描述了多个字段的唯一性会增强,下面将解释如何计算唯一性。假设多个字段变量独立分布,那么:
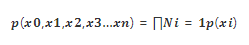
如果我们选择 M 个随机变量,每个变量的取值有 N 个,那么:
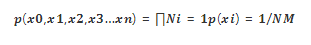
假设 M=10, N=10,那么唯一性就非常大:
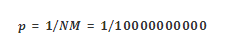
根据这个概率值,我们可以计算碰撞的概率。在允许的碰撞概率之中,如果多个联合字段的概率小于这个值,就认为是符合唯一性要求,将两个设备关联上。
2.3 多个字段组合的设备指纹唯一性
从设备上采集的字段中,有的字段的唯一性高,有些字段的唯一性低。根据上述原理,我们可以通过联合多个低唯一性字段,从而得到一个高唯一性的组合字段。
假设对设备指纹的唯一性要求是碰撞概率小于1/100000000000,而 ip,手机型号,系统版本,存储空间等字段的碰撞概率均为1/10000,那么这几个字段的联合起来的概率值可能就超过要求的碰撞概率,即这些字段组合起来即可当做一种设备指纹的生成算法。当然这里只是一种近似的算法,实际中用到的组合条件和权重复杂很多。

2.4 组合字段选择
上文从条件概率角度介绍了“唯一性”的含义。如果一个字段中每个取值的概率不一样,加上特征数量较多,则很难人工选取适合的分类组合。决策树的作用就是通过训练迭代的方式,找到最佳的分类特征及其分界点,使得总体的条件概率最大化。可以使用熵衡量分类的误差(本质上就是条件概率最大化):
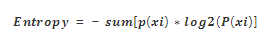
还是以上面的例子说明,p(sid|idfv)=1,这时候信息熵为0,表示”确定性很强”。P(sid|ip = 220.170.50.207) = 1/208 ,这时候熵的计算公式,这个值比较大,说明“不确定”很强:
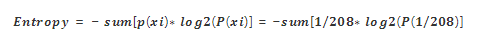
不同字段的条件概率可通过历史数据统计后得出,如下图所示:

因此,诸如 IDT、RF、GBDT 这类决策树的本质,就是通过已有的样本,选择最优的分类特征及其分界点,得到最优的分类树。
03 传统设备指纹存在哪些问题?
传统的设备指纹主要采用客户端生成的方案。随着黑产的对抗能力不断增强,设备指纹被破解的情况越来越频繁,主要是由于暴露在外的 SDK 有可能被人逆向破解,设备指纹的稳定性难以保证。
客户端生成的方案更难被破解,黑产对抗的成本也更高。每次被破解后都需要修改 SDK,升级版本,而 APP 版本升级成本很高,时效性低,在与黑产的对抗中处于不利局面。于是,我们开始转换思路,推出基于服务端计算设备指纹的方案。
04 服务端生成方案
在服务端生成方案中,指设备指纹通过服务端的算法计算得到,不再是在客户端进行计算。服务端设备指纹算法的主要过程如下:
4.1 算法过程
使用服务端计算设备指纹时,可不局限于单一的计算算法,可同时采用多种算法计算出不同的设备指纹,每种设备指纹的唯一性都已达到要求,稳定性各有高低。举个例子,设备指纹 A 在条件 A 下会发生变化,在条件B下不会变化。设备指纹 B 在条件 A 下不会发生变化,但在条件 B 下会发生变化。当我们综合2者之后,找回算法可以保证,不管是 A 发送变化,还是 B 发生变化,最终生成的设备指纹都可以保持不变。算法如下图所示:

假设有2种设备指纹生成算法 F1 和 F2,分别使用A和B字段进行计算,得到2个不同的设备指纹。该算法会综合两者结果,返回一个最终的设备指纹,用 Sid 进行表示。当我们使用同一个设备多次修改后字段 A 和 B 后,计算过程如下所示:
1)当该设备第一次访问时,假设 A=0,B=0,此时:
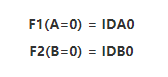
由于 IDA0 和 IDB0 此前都未出现过,所以将其当做新设备,随机生成一个设备指纹分配给它:SID0 ,并且记录 IDA0 属于 SID0 ,IDB0 也属于 SID0 ,即

2)当该设备第二次计算时,如果 A 和 B 没有变化,还是为0,那么计算出来的结果与第一次完全一样,仍未出现 IDA0 和 IDB0,但此时根据历史数据可知,IDA0 和 IDB0 对应的设备指纹为 SID0,所以返回的设备指纹是 SID0;
3)假设当设备发生变化时,比如 A 发生变化,此时A=1,B=0,计算如下:
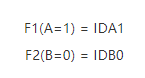
此时F1计算得到的设备指纹已发送变化,但 F2 计算的仍然不变,我们通过 IDB0 得到该设备的设备指纹仍为 SID0,并且将 IDA1 也加入到 SID0 库中,即

4)同理当 B 字段发送变化时,假设此时 A=1,B=1,计算过程如下:

此时 F2 计算得到的设备指纹已发送变化,但仍然可以通过 IDA1 查询到当前设备的设备指纹为 SID0,同时将 IDB1 也加入到 SID0 的库中,即
从上述过程可以看到,当设备信息 A、B 均发送变化的情况下,服务端通过历史数据可以进行回溯,从而确保最终生成的设备指纹保持不变。需要注意的是,上面只是简单的描述过程,实际情况下字段变化的情况往往更加复杂。
4.2 实际效果
从上述生成算法可知,相对客户端计算,服务端计算方案可以同时采用多种生成算法,利用历史数据回溯的方式进行找回,相较于单一生成算法,设备指纹的稳定性有较大提升,能保证在部分设备数据变化的情况下,生成的设备指纹保持不变。
另外,由于设备指纹通过服务端计算生成,不对客户端暴露,安全性有所提升。同时算法升级较为方便,只需要服务端更新算法即可,客户端无需升级版本,从而降低使用成本。
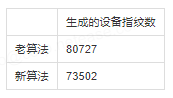
根据线上运行一段时间后的统计,通过新老算法生成的结果如下:找回比例达8.9%,设备指纹的稳定性提升明显。
05 总结
本文主要介绍了易盾在设备指纹对抗上的经验,在客户端 SDK 对抗的基础上,使用服务端生成方式,既保证生成算法的安全性,又利用大数据技术,对篡改的设备进行找回,进一步提高设备指纹的稳定性。
设备指纹作为黑产对抗的基础武器,也是对抗最为激烈的战场,保证设备指纹的唯一性和稳定性是关键的一环。易盾也会持续的进行优化迭代,不断提高设备指纹的效果。
来源:freebuf.com 2021-03-02 19:10:06 by: wangyiyunyidun






















请登录后发表评论
注册