摘要:个人信息因其自身携带隐私特性,与每个个体息息相关。个人信息保护不当,影响公众权益、企业利益以及社会秩序。在互联网、大数据、5G万物互联的时代,个人信息被广泛收集和使用,必须妥善解决个人信息保护问题,才能保障整个数据产业健康发展。而现有的个人信息保护方法或技术,不足以应对新形势下的保护诉求。基于数据运营安全的个人信息保护,针对当前个人信息保护的新形势和新诉求,提出结合人工智能,通过数据运营安全对结构化、半结构化、非结构化的个人信息流动的保护,涵盖从生产到运维,从采集,传输,存储,处理,分析,共享,销毁全生命周期保护,深入数据运营中内嵌防护,同时与业务解耦,达到保护个人信息安全的目标。
关键词:个人信息保护;个人信息流动;数据运营安全;人工智能;内嵌防护
引言
信息技术的高度发展与普及,为我们的日常工作、生活带来极大的便利。个人信息作为标识一个人的主要属性,在各业务场景下需要将身份zheng、电话等提供给他人(含企业,政府等组织)。一旦他人对个人信息监管疏漏或使用不当,个人信息没有有效保护,一方面会对个人的财产、人身安全造成侵害,一方面责任方也会受到声誉、经济的双重重创。据IBM Security发布的《2020年数据泄露成本报告》,对全球 500多个组织数据泄露事件的深入分析发现,有 80% 的事件导致了客户个人身份信息的泄露。针对个人信息保护问题,本文提出了结合人工智能,通过数据运营安全保护个人信息的方法。
一、个人信息保护面临的挑战
在纸质办公时代,个人信息的保护一般通过签署保密协议等承诺方式进行保护,个人信息的保护诉求相对比较弱化。在互联网、大数据、5G互联时期,一方面,个人信息被急速的收集、汇聚;另一方面,企业为了从个人信息数据中挖掘商业价值,扩大个人信息的使用、共享,个人信息流动频率上升。与此同时,越来越多的行业、企业、个人意识到个人信息中蕴含的价值,这也引导更多的注意力集中在个人信息的收集上。不法分子从中嗅到了商机,使用各种非法手段窃取个人信息进行倒卖。其中,不乏企业内部人员借助工作便利直接进行信息倒卖博取经济利益,内部威胁在个人信息侵害中占比很大。个人信息保护不当导致个人财产受损乃至造成生命危险,个人信息保护形势极其严峻。
个人数据规模持续快速增长,这些数据蕴含着巨大的价值。而数据价值要释放出来,就需要打破当前个人信息的孤岛式数据服务提供方式,加速开放和共享。这就需要首先解决个人信息的安全问题。面对多维度的个人信息,不同行业不同需求的个人信息使用,各企业对个人信息相关的业务线条复杂化,以及随着技术发展所带来的个人信息保护的新挑战,个人信息保护迫在眉睫。从国家、企业到个人,也对个人信息保护愈加重视。
二、个人信息保护立法的合规要求
在我国,立法部门、执法部门以及社会产业等各界正在持续致力于推动个人信息保护的发展与落实。近年来《网络安全法》、《数据安全法(草案)》陆续出台,《个人信息保护法(草案)》在2020年 10月公布。与此同时,针对金融、电信、互联网等各行业自身行业特征,国家及行业相关部门制定了相应的个人信息保护指南,如《金融数据安全数据安全分级指南》,《个人金融信息保护技术规范》,《电信和互联网用户个人信息保护规定》等。在国外,相应的法律法规也在陆续制定,例如2018年欧盟正式实施GDRP。GDPR虽然由欧盟颁布实施,根据内部条文的约束定义,管辖范围可以延及全球。2018 -2020年,GDPR开出的罚单总计上亿美元,包括谷歌,Facebook,万豪,英国航空等多家巨头企业都因个人信息违规而收到大额罚单。
个人信息维度多样,在《个人信息保护法(草案)》中对个人信息的保护,涵盖了个人信息的收集、处理和利用。各行业对个人信息分类分级保护,提出了具体要求。纵观国家及各行业的法律法规可以看到,对个人信息分类分级,从收集、传输、存储、使用、共享、销毁全生命周期的保护,是个人信息保护的关键。
三、现有保护技术的优势和劣势
对个人信息的保护,现有的保护方式主要包括传统安全、数据库安全、数据防泄漏(DLP)、终端加密以及UEBA。各种保护方式的特点如下:
第一,传统安全(防火墙/下一代防火墙):主要抵御外部攻击,下一代防火墙带有一定的数据安全检测和管控的能力,不能对内部的数据流动做出响应和保护。
第二,数据库安全:解决结构化数据的安全问题如运维,审计,加密,脱敏等。单一的对结构化数据进行保护,不能对非结构化数据以及非结构化数据流动过程进行保护。
第三,数据防泄漏(DLP):以边界保护为主,重在对外发的个人信息进行安全监控或保护。不能保障个人信息在内部不同终端间,不同服务器、业务系统之间的流动安全。
第四,终端加密:以终端保护为主,对落地到终端的数据加密,重在非结构化数据的静态存储保护。结构化数据如个人信息等无法保护,不能在数据流动过程中平衡安全与业务。
第五,UEBA:能够发现并保护内部数据异常使用和安全威胁,但对数据从生产到运维,从前端到后端的整个生命周期中的流动安全没有保障。
针对个人信息保护的关键技术研究,主要包括K-匿名化、差分隐私、零知识证明ZKP、同态加密、安全多方计算、联邦学习等。1)K-匿名化:匿名化程度不足,隐私信息容易被破解;获得越高的匿名化,就要选择越复杂的匿名化算法。2)差分隐私:差分隐私对数据添加噪音以获得隐私信息的保护,需要在结果中加入大量随机化,这会导致数据的可用性急剧下降。3)零知识证明ZKP:生成零知识证明需要大量的算力,意味着较高的硬件资源投入,对数据使用效率的也有影响,对企业日常业务的个人信息进行保护存在一定难度。4)同态加密:计算开销较大,在同态加密体制的设计与优化方面,仍需要继续研究。5)安全多方计算:可获取数据使用价值,却不泄露原始数据内,但需要交互较多,通信的开销比较大。提高计算协议的效率,扩充本技术的应用场景,还在研究中。6)联邦学习:算法通信次数多,需要从效率上提升;从安全性来讲,需要防止从模型参数推演出原始数据;同时技术本身的鲁棒性有待继续研究。
综上所述,现有的个人信息保护方式,存在以下问题:1)重在保护结构化数据,在处理非结构化数据方面存在空缺。2)主要解决数据在单个域内的安全,没有对不同域之间的数据流动进行保护。而数据只有流动起来,才能得到价值最大化。尤其是在大数据时代,数据孤岛被打破,企业业务线条复杂化,个人信息既可能在特定的业务服务流程中使用,也可能在不同的业务之间流动使用。在数据流动中保护个人信息,是个人信息保护的重点。3)集中解决数据单个时期的安全问题,比如数据静态存储安全,或者监控数据检索、查询;保护了前端数据的存储、使用安全,但对前后端整个运维过程缺乏监管。
新兴的关键保护技术在解决某一类业务问题,某些特定应用场景的保护,有一定优势,但总体上在业务中的应用还不够成熟,有待进一步研究。现有个人信息保护方式,不足以应对当前个人信息的保护需要。本文针对当前个人信息保护的新形势,提出结合AI,通过数据运营安全对结构化、半结构化、非结构化的个人信息流动的保护,涵盖从生产到运维,从采集,传输,存储,处理,分析,共享,销毁全生命周期保护,深入业务执行内嵌防护,同时与业务解耦,达到保护个人信息安全的目标。
四、下一代技术方案实现
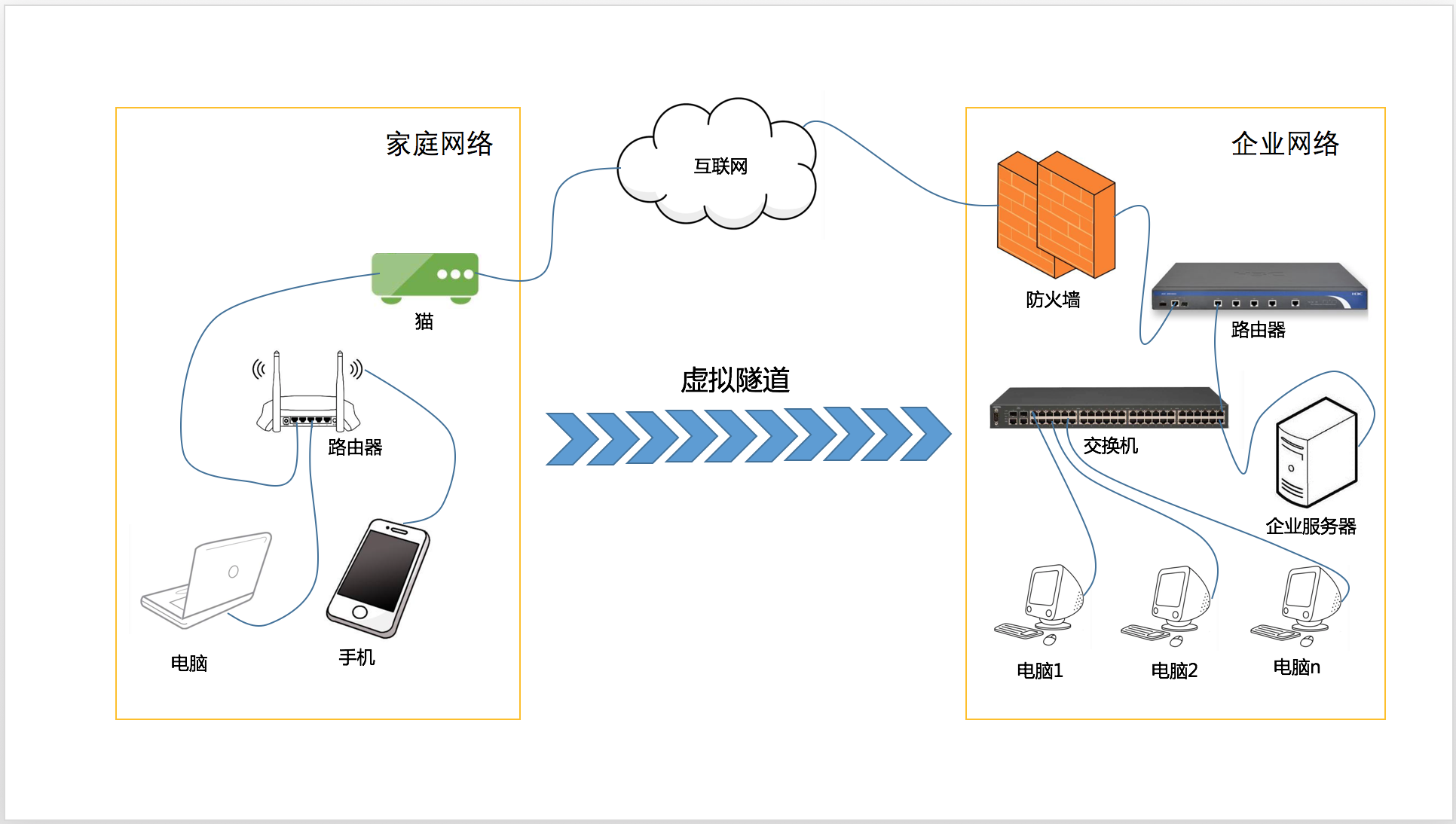
数据运营安全的个人信息保护,如图1所示,让个人信息保护满足合规性要求,在数据使用过程中追溯个人信息的流动,对数据的全生命周期进行保护,主要包括以下核心: 1)跨业务跨域的遥测数据采集分析; 2)全类型AI个人信息梳理; 3)暗数据与明数据的AI分类梳理标注; 4)个人信息影子及非感知数据的追溯;5)数据链的全运营周期追溯;6)分布式AI数据安全风险分析。7)零信任数据安全; 8)自动化编排安全响应;9)多源数据统一安全机制;如图2所示。
 图1 基于数据运营安全的个人信息保护
图1 基于数据运营安全的个人信息保护
![图片[2]-基于数据运营安全的个人信息保护 – 作者:数安行datasecops-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/image.3001.net/images/20210226/1614340311_6038e0d71983e2147bca8.png)
图2 数据运营安全的个人信息保护核心
4.1、跨业务跨域的遥测数据采集分析
探针遥测内嵌入业务单元中,对终端、数据库、业务服务器以及公有云、私有云或混合云,包括Docker,数据仓库,数据湖等个人信息进行跨业务跨域的采集分析,为全域的个人信息保护建立基础。探针遥测到各个域内,同时将抓手探入到业务内部,分析个人信息数据。
4.2、全类型AI个人信息梳理
对各种类型的个人信息进行深度识别,从个人信息本体特征、行业特性、合规性等角度,结合机器学习对个人信息进行梳理,主要包括:1)用户的姓名、电话、身份ID等基础属性,以及与业务紧密关联的个人信息,比如在电信运营中的通话数据、位置数据等等;金融行业中的账户信息、财产信息、借贷信息等。2)信息以结构化、半结构化、非结构化等多形态方式,或在数据库中存储,或转为文档方式流转,或在内部业务流转过程中进一步进行格式转换、数据的解析等等。3)新网络形态、新技术的应用,所衍生出的新数据类型、数据生产方式、数据处理方式。
4.3、暗数据与明数据的AI分类梳理标注
基于AI和不同行业的个人信息特征,选取分类标准和算法,对暗数据、明数据方式存在的个人信息自动完成分类梳理标注。1)跨业务跨域的个人信息,大量的暗数据沉淀积累。暗数据蛰伏不动,一方面不能挖掘数据的价值,另一方面也会存在安全隐患,管理者无法了解,也不敢贸然使用。对暗数据的AI分类梳理标注,发现数据价值,规范数据的进一步使用;2)极大量级的明数据持续使用和增长。明数据处于活跃期,在使用和增长过程中持续变动。通过明数据的AI分分类梳理标注,从链条上将各类信息梳理清晰。
4.4、个人信息影子及非感知数据的追溯
个人信息的存在方式,除了直观可见的完整的个人信息记录,还包括个人信息的痕迹、碎片化的数据,即个人信息影子,以及看似已删除的数据、驻留内存但感知不到的数据。个人信息的使用痕迹,或者碎片化的个人信息,这些单独的点滴信息不足以给个人信息构成威胁,但多条点滴信息汇聚在一起,就比较容易获得个人信息的完整画像,这时候就会给个人信息带来威胁。同时,已删除的数据,驻留在内存的数据,对一般用户来讲感知不到,但是通过一定的技术手段也是很容易恢复出原始的完整个人信息。通过对个人信息影子和非感知数据的追溯,挖掘隐式数据的踪迹,保护个人信息生命周期安全。
4.5、数据链的全运营周期追溯
对现有的数据流转路径以及新兴的数据流进行追溯管理,建立个人信息与主体的映射关系;个人信息在流动中的原文流转、变形流转的血缘关系;记录个人信息的版本、状态、位置以及轨迹,形成个人信息数据流全生命周期的流动画像,对个人信息的流转、扩散进行全视角的风险态势感知和合规性管控,从数据流的链路中保护个人信息,如图3所示。追溯个人信息在企业中流动,主要包括三个方面:1)广泛的流动。这和企业业务线条复杂化有关。既有一些个人信息集中式在特定业务系统中处理分析,也有一些个人信息随着不同部门、不同业务需求在网络中向不同的业务系统流动。通过对广域分布的个人信息流动进行追溯管理,感知个人信息的风险态势。2)基于生命周期的数据链的个人信息流动。个人信息从生产到运维,从产生、收集、存储、使用、共享到销毁,在数据链的每个节点上,抓取个人信息的轨迹。个人信息在不同的业务流程中使用,在不同的业务服务器之间流转,以及不同域之间的流动,本方案以数据与业务的运营周期为牵引,追溯个人信息,保护全数据链的流动安全。3)新技术下个人信息多流转路径追溯。为了挖掘数据价值,企业自身在进一步寻求打破内部业务壁垒的方式;同时,随着大数据时代、5G时代的数据开放共享,网络环境趋于开放,数据流也愈来愈多,追溯各流转路径,突破传统的数据边界,保障数据的可控性。
![图片[3]-基于数据运营安全的个人信息保护 – 作者:数安行datasecops-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/image.3001.net/images/20210226/1614342391_6038e8f7bc837d81e32f0.png)
图3 个人信息全链路周期追溯
4.6、分布式AI数据安全风险分析
个人信息数据涉及隐私,在保护模式上不适合对所有个人信息进行集中式的收集和分析,而从企业管理角度,需要获取个人数据特征,并基于数据特征做进一步保护。在不获取原始个人隐私数据的前提下,通过分布式机器学习对分散于各处的个人信息特征进行智能识别、风险分析,进而形成组织级的个人信息风险保护特征与应对机制。
4.7、零信任数据安全
个人信息的保护,从用户、终端、网络、个人信息数据四个方面建立起零信任数据安全域,保护个人信息的访问、传输、存储和使用。由零信任用户、零信任终端控制访问个人信息的安全认证,防止非法用户或终端接触个人信息;个人信息数据在终端之间、终端与服务器之间传输时,由零信任网络保护个人信息;个人信息存储在终端中以及在终端中使用时,零信任终端以及对个人信息本体的零信任防护,构建安全域空间,保护数据安全。
4.8、自动化编排安全响应
分布于各业务、各域的个人信息,以及在数据运营过程中流动的个人信息,如果保护力度不当,会造成新的难题。比如,保护力度弱,达不到安全要求,则个人信息安全无法保障。保护力度过强,可能影响业务的持续性,导致本来正常流转的业务被中断。由此,通过数据运营全周期的特征追踪与数据分析,对个人信息进行数据分布采集、流动追溯,感知个人信息的风险态势,基于机器学习,对各类事件和风险进行分析和分诊,结合用户使用场景、安全基线以及风险活动,从响应时间到响应力度,形成适合数据运营业务安全的按需保护的响应机制。
4.9、多源数据统一安全机制
个人信息是多源化的存储、使用、流转,同类或同级的个人信息保护在不同源中获得一致的保护,达到保护个人信息的目标。同类或同级的个人信息,如果在一部分域内按高强度保护,在一部分域内按弱强度保护,可能让原本需要高度保护的个人信息,通过不同域的传输流转后进入弱保护状态,这就等同于百密一疏,导致保护效力被大大缩减。本方案在安全保护机制方面,对同类或同级的个人信息的保护力度统一,通过对多源个人信息构建适合业务流程与个人信息安全的统一安全机制。
五、结论
个人信息因其自身携带隐私特性,与每个个体息息相关。个人信息保护不当,影响公众利益、企业利益以及社会秩序。国家、政府、学术、企业社会各界对个人信息保护极度重视,从立法、执法、研究、产业化多个角度落实个人信息保护。基于数据运营安全的个人信息保护方案,遵循个人信息保护的合规性要求,结合AI,内嵌至数据运营全周期中对个人信息进行保护,是当前阶段适应个人信息保护新诉求的方案。个人信息保护随着时代的发展,保护诉求也会发生新的变化。本文所涉及的仍在研究中的个人信息保护关键技术,在技术难点取得突破进展的同时也将推广到更多的个人信息保护领域。除此之外,机密计算作为可信执行环境+数据隔离的高度安全技术,在未来的发展中将有助于个人信息的保护。
作者:王文宇,北京数安行科技有限公司,CEO,高级工程师,主要研究方向为网络空间安全,数据安全,系统工程。
参考文献:
[1] 中华人民共和国第十二届全国人民代表大会常务委员会.中华人民共和国网络安全法[Z].2017.
[2] 中华人民共和国第十三届全国人民代表大会常务委员会.中华人民共和国数据安全法(草案)[Z].2020.
[3] 中华人民共和国第十三届全国人民代表大会常务委员会. 中华人民共和国个人信息保护法(草案)[Z].2020
[4] 中国人民银行.金融数据安全/数据安全分级指南(JR/T 0197-2020)[Z].2020.
[5] 中国人民银行.个人金融信息保护技术规范[Z].2020.
[6] 中华人民共和国工业和信息化部.电信和互联网用户个人信息保护规定[Z].2013.
[7] Latanya Sweeney, k-anonymity: a Model for Privacy[J].International Journal on Uncertainty, Fuzziness and Knowledge based Systems, 2002,10(5):557-570.
[8] Cynthia Dwork. Differential Privacy[C]. Proceeding of the 33rd International Colloquium on Automata, Languages, and Programming – Volume Part II. Berlin: Springer-Verlag, 2006:1-12.
[9] Shafi Goldwasser, Silvio Micali,and Charles Rackoff. The Knowledge Complexity of Interactive Proof Systems[J]. SIAM Journal on Computing, 1989, 18(1):186-208
[10] Ronald L. Rivest, Len Adleman, and Michael L. Dertouzos. On Data Banks and Privacy Homomorphisms[M]. Foundations of Secure Computation, Academia Press, 1978
[11] Yao A C. Protocols for Secure Computation[A]. Proceedings of the 27th Annual IEEE Symposium on Foundations of Computer Science[C].1986: 162-167.
[12] Yao A C. How to Generate and Exchange Secrets[A]. Proceedings of the 23th Annual IEEE Symposium on Foundations of Computer Science[C].1982:160-164
[13] Brendan McMahan, et al. Communication-Efficient Learning of Deep Networks from Decentralized Data[DB/OL].https://arxiv.org/abs/1602.05629.2017.
[14] Keith Bonawitz, Hubert Eichner, Wolfgang Grieskamp, et al. Towards Federated Learning at Scale: System Design [DB/OL]. https://arxiv.org/ abs/1902.01046.2019.
来源:freebuf.com 2021-02-26 20:31:25 by: 数安行datasecops





















请登录后发表评论
注册