01 神经网络压缩技术概要
深度学习在计算机视觉以及自然语言处理等领域达到了一个前所未有的高度,但是深度学习模型往往极度复杂,并伴随着高额的存储空间与计算资源消耗,这使得深度学习模型很难落实到各个硬件平台。例如VGG16卷积神经网络,其参数数量有1亿3千多万,模型占用500多MB的存储空间,需要进行300多亿次的浮点运算才能完成一次图像识别任务。
经研究表明,在神经网络模型中存在大量的冗余神经元与权重,参与主要计算并对最终结果产生影响的权重只占总数的5-10%。这也给神经网络压缩提供了理论基础。若能够找到有效的压缩手段,深度神经网络便可更广泛的部署在移动设备等轻量级设备上。
在服务端,也可以提供更好的性能。举个实际的例子,我们用剪枝+知识蒸馏的方案,将维阵漏洞检测的模型的推理速度提高了9倍,即使仅仅基于CPU,也可以实现快速推理,这样服务端的硬件成本也可以降下来。
压缩模型通常分为:1)对训练好的大型网络进行剪枝或对其权重进行量化。2)使用一定的方法构建更加轻型紧凑的网络。
其中,神经网络剪枝首先会从大型网络中筛选出不重要的神经元以及权重,之后将它们从网络中删除,在此同时尽可能的保留网络的性能。
剪枝技术按照细粒度的不同可分为结构性剪枝以及非结构性剪枝:
结构性剪枝剪除的基本单元为神经元(卷积中为filter),由于是对神经元直接进行剪枝,结构性剪枝后的模型能够在现有硬件条件下实现明显的推理加速以及存储优势。但其缺点是剪枝的颗粒度较大,往往会对压缩后模型的精度产生较大的影响。
非结构剪枝剪除的基本单元为单个权重,其经过剪枝后的模型精度损失更小,但最终会产生稀疏的权重矩阵,需要下层硬件以及计算库有良好的支持才能实现推理加速与存储优势。![图片[1]-神经网络剪枝 – 作者:极光无限SZ-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/image.3001.net/images/20201218/1608288592_5fdc8950cd496e0094acc.png) ▲神经网络剪枝示意图
▲神经网络剪枝示意图
剪枝算法可分为one-shot(一次性剪枝)以及iteration(迭代剪枝):
one-shot法首先对预先训练好的模型中神经元或权重进行重要性评估,之后剪除掉无关紧要的神经元或权重(可通过设置阈值等方法实现),再对剪枝后的模型进行微调。
而迭代剪枝可看作多次重复进行的one-shot法:在微调之后判断是否可以继续剪枝,如果可以继续进行,则再次启动one-shot法。迭代剪枝法获得的压缩模型更加紧凑,尺寸更小,但其训练成本远大于比one-shot法。
02 稀疏动量剪枝
稀疏动量剪枝法[1]是一种新颖的剪枝方法,不同于传统剪枝方法需要训练好的模型,稀疏动量剪枝法可以从头直接对稀疏网络进行训练。稀疏网络要求尽可能有效的使用神经网络中的每一个权重。目标是在给定网络稀疏度的情况下选择最有效的连接方式(最有效的权重)。
稀疏动量算法首先确定网络的剪枝比例,将此剪枝比例作为网络的稀疏度,之后对密集网络中每一层应用此稀疏度构建起初始的稀疏网络。随后对该稀疏网络进行训练。
很明显,初始构造的稀疏网络不是最优的结构,需要算法来确定哪些链接应该被移除,哪些已被移除的链接应该被重新添加进网络中。每次训练过程可概括为”先剪枝,后生长”。可使用动量方法来确定权重的重要程度,并以此来指导当前训练阶段中在保持网络稀疏度的同时,应该删除哪些权重,应该使哪些权重重新生长来达到更好的优化目标。
动量优化是一种对连续梯度取平均值以更好的估计局部最小值方向的方法:在随机梯度下降中对最近的梯度方向以及过往梯度方向进行加权来确定梯度更新方向。权重的动量可用来估计该权重一致减少了多少训练误差。在剪枝阶段中对每层中权重的动量进行排名,剪除50%最不重要的权重。在生长阶段中:通过将稀疏网络中每一层中所有权重的平均动量大小当作该层的重要度,可以对网络中所有层的重要程度进行排名:之后网络中每一层会根据其重要程度比例来确定要恢复的权重个数。![图片[2]-神经网络剪枝 – 作者:极光无限SZ-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/image.3001.net/images/20201218/1608288630_5fdc89762094c66b1fd84.png) ▲稀疏动量算法示意图
▲稀疏动量算法示意图
稀疏动量算法提供了一种从头训练稀疏网络的方法。实验结果表明,在小型数据集如MNIST,cifar10上可以通过使用稀疏程度高达80%的网络来匹配密集网络的性能。在中型数据集ImageNet上稀疏度为80%的网络也可达到74.9的精度。
03 基于科学控制的剪枝
剪枝方法的重点在于评估神经网络节点对于网络整体的重要程度,在尽量不影响网络性能的条件下删除那些重要程度低的节点,通常的评估算法是将节点与损失函数建立联系,与损失函数关联度高的节点被赋予更高的重要程度,但是因为输入数据不同可能导致网络内部存在大量节点相互耦合,导致一些本身不重要的节点却与损失函数关联密切。使得剪枝后的模型对数据敏感,模型变得不稳定。
论文[2]中通过建立科学控制的方法来减少剪枝过程中潜在无关因素的干扰。
整体算法流程如下:首先根据真实图片构建被称为knockoff的伪特征,该伪特征具有如下性质:1)交换真实特征以及伪特征上相应位置的元素不会影响它们的联合分布。2)伪特征应具备标签无关特性。因此,伪特征真实特征之间的唯一区别在于是否与标签相关。![图片[3]-神经网络剪枝 – 作者:极光无限SZ-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/image.3001.net/images/20201218/1608288652_5fdc898c77d7d22697c75.png) ▲伪数据及伪特征的定义
▲伪数据及伪特征的定义
通过比较真实特征以及伪特征在网络中的表现,可以最大程度上减少无关因素的干扰,并迫使剪枝过程更加关注于特征与预测之间的联系,从而得出更加可靠的方法来确定滤波器的重要性。
其算法具体过程为:
首先生成伪数据和网络中每一层的伪特征,论文通过推理证明了当网络的输入数据是伪数据时,网络中每一层产生的特征都是相应真实特征的伪特征。对于预训练好的网络,可以得到输入伪数据和真实数据后网络每一层的伪特征和输出特征。通过对它们进行线性加权后重新作为相应网络层的输入,之后根据真实标签只训练加权系数。
然后可以通过每层中训练好的加权系数来判断相应特征的重要程度。由于伪特征不含有标签信息,因而其加权系数应该小于真实特征的加权系数,可根据伪特征与真实特征之间的加权系数之比来对特征的重要程度进行排名。
最后进行相应的剪枝,此过程最大化的排出了数据中不相关的潜在因子的影响。![图片[4]-神经网络剪枝 – 作者:极光无限SZ-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/image.3001.net/images/20201218/1608288669_5fdc899dbdc3dc6f29988.png) ▲使用科学控制的剪枝算法示意图
▲使用科学控制的剪枝算法示意图
在ImageNet上的实验表明了这种不相干潜在因素的剪枝方法的有效性,相比于现有的SOTA剪枝方法GAL[3]和PFP[4],使用该方法后得到剪枝模型无论是网络精度还是模型大小都有很大的优势。![图片[5]-神经网络剪枝 – 作者:极光无限SZ-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/image.3001.net/images/20201218/1608288684_5fdc89ac93d01ff664160.png) ▲实验结果对比,SCOP为科学控制下的剪枝算法
▲实验结果对比,SCOP为科学控制下的剪枝算法
04 神经网络剪枝的理论研究
对神经网络剪枝的理论研究同样重要。早先研究认为剪枝技术都需要一个已训练好的网络作为剪枝对象,通过测量权重或神经元对模型精度的影响来寻找要被剪除的目标。而从头训练一个稀疏化的网络往往非常困难,且这种剪枝后的模型性能往往不尽如人意。
之前的先验都认为剪枝技术在压缩模型的同时不可避免的带来了模型精度的损失,但在论文[5]中提出了一个假设:任何密集,随机初始化的前馈网络都包含至少一个子网络,如果只对该子网络进行隔离训练,可以在相似的迭代次数中达到与原始密集网络相当甚至更高的测试精度,且子网络的学习速度更快,泛化性能更强。这种子网络被称为中奖彩票。此外,作者还发现,对于中奖彩票子网络,需要使用密集网络的初始化参数进行隔离训练才可达到上述结果。这揭示了稀疏架构和初始化组合的重要性,这些组合特别擅长学习。如果能够将中奖彩票从原始网络中尽可能早的剥离出来,便可直接训练这种稀疏结构,可大大缩短训练与推理时间,且降低存储空间,又不损失模型性能。同时,中奖彩票假设提高了我们对神经网络理论的认知:即稀疏结构的重要性。
参考文献:
[1] Dettmers, Tim, and Luke Zettlemoyer. “Sparse networks from scratch: Faster training without losing performance.” arXiv preprint arXiv:1907.04840 (2019).
[2] Tang, Yehui, et al. “SCOP: Scientific Control for Reliable Neural Network Pruning.” Advances in Neural Information Processing Systems 33 (2020).
[3] Shaohui Lin, Rongrong Ji, Chenqian Yan, Baochang Zhang, Liujuan Cao, Qixiang Ye, Feiyue Huang, and David Doermann. Towards optimal structured cnn pruning via generative adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2790–2799, 2019.[4] Lucas Liebenwein, Cenk Baykal, Harry Lang, Dan Feldman, and Daniela Rus. Provable filter pruning for efficient neural networks. In International Conference on Learning Representations, 2020.
[5] Frankle, Jonathan, and Michael Carbin. “The lottery ticket hypothesis: Finding sparse, trainable neural networks.” arXiv preprint arXiv:1803.03635 (2018).
来源:freebuf.com 2020-12-21 10:10:21 by: 极光无限SZ












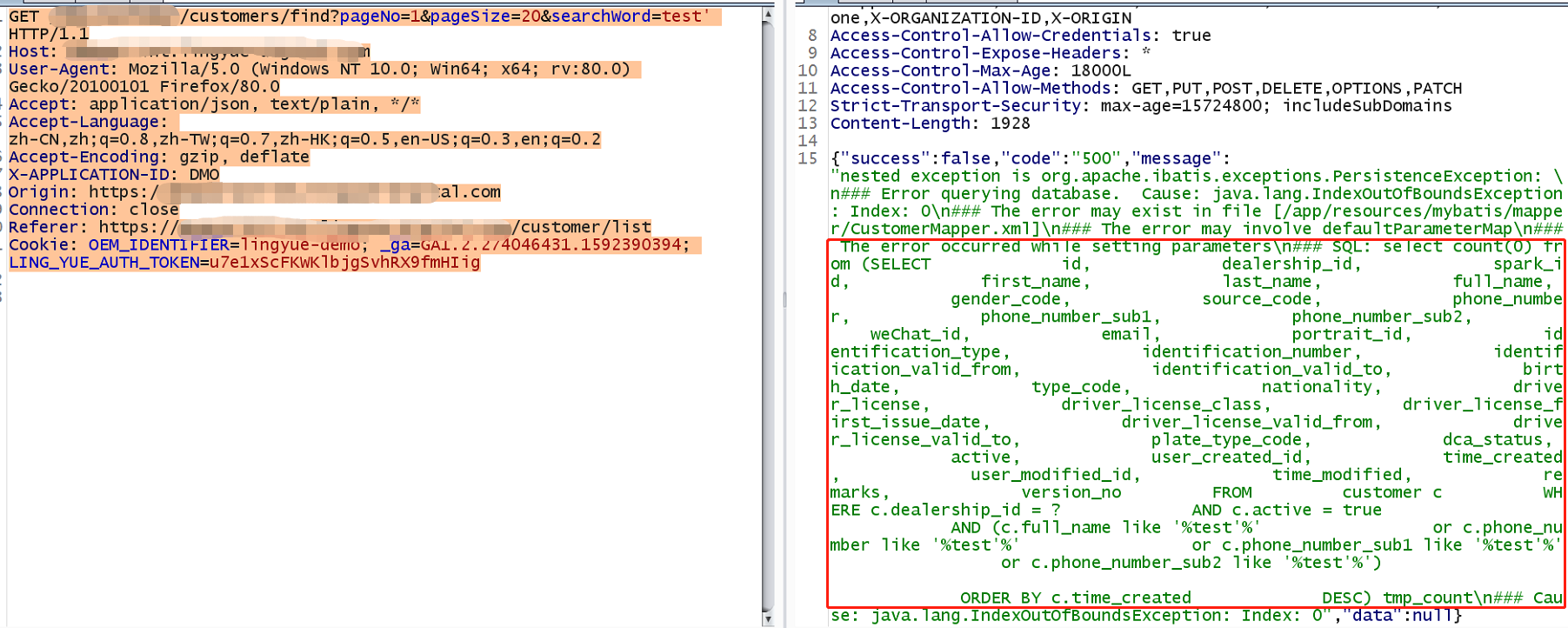







请登录后发表评论
注册