*本文中涉及到的相关漏洞已报送厂商并得到修复,本文仅限技术研究与讨论,严禁用于非法用途,否则产生的一切后果自行承担。
前言
Flask-Admin是一个功能齐全、简单易用的Flask扩展,让你可以为Flask应用程序增加管理界面。介绍完毕,首先去官方GitHub上看了下,翻了翻issue。发现了了一个蛮有趣的xss,因为url解析差异问题导致xss的案例,于是就动手分析一下。
refs #1503 fix reflected xss by lbhsot · Pull Request #1699 · flask-admin/flask-admin · GitHub
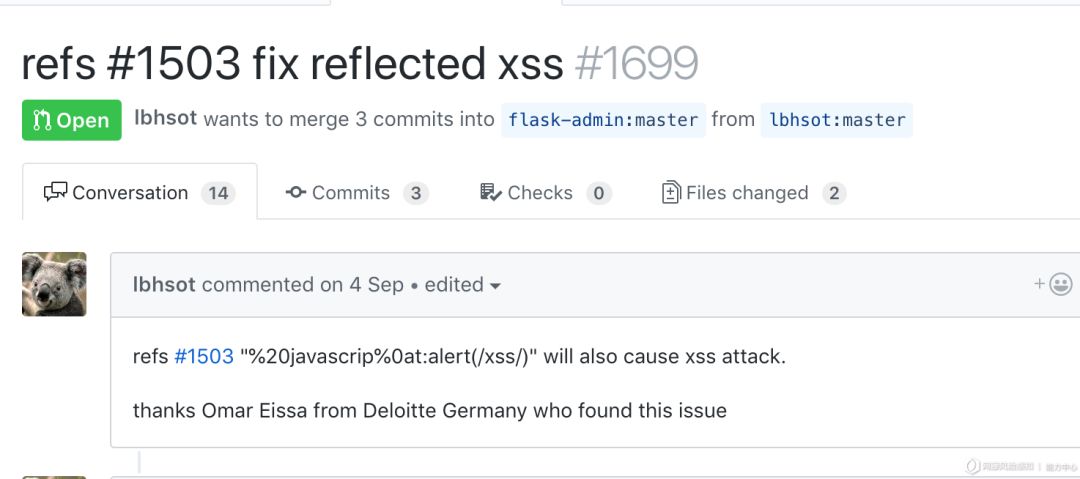
环境搭建
首先这个是对于issue#1503的反射xss的绕过,issue地址为 Reflected XSS · Issue #1503 · flask-admin/flask-admin · GitHub
后面开发人员在Merge pull request #1505 from pawl/issue_1503 · flask-admin/flask-admin@960f5e0 · GitHub 中对其issue#1503进行了修复。

搭建:

漏洞复现
Payload:
http://127.0.0.1:5000/admin/user/edit/?url=javascript%0a:alert(1)&id=1
这里直接用issue#1699中提供的的绕过Payload,此时URL中的url参数正常情况下将会别作为返回的url赋值给前端的List导航和Cancel按钮的href属性。

这是一个需要交互的XSS,点击Cancel按钮或者List导航即可触发触发,此时页面源码是这样的。

漏洞分析
观察一下payload URL, /admin为基础路由,/user为用户通过add_view定义的路由,重点的 /edit为flask-admin提供的exit操作路由。分析就从这里开始,搜索/edit,进入到flask-admin/base.py中查看/edit 路由。

其对应的temlpate为flask_admin/templates/bootstrap2/admin/model/edit.html,下面的模板代码对应的就是页面上的List导航的按钮,可以看到这里通过Jinja2获取了return_url。

return_url将会由get_redirect_target()获取,查看get_redirect_target()的代码,这里获取了request的URL参数,并且通过is_safe_url进行判断,判断字符串是否安全。

进入到is_safe_url中观察,开发对其修复针对的正是该函数。

结合issure#1503 中提供的Payload https://10.0.0.1/admin/user/edit/?url=%20javascript%3aalert(document.domain)&id=8,和官方对其进行的修复,就可以看出开发人员仅仅针对这单一payload进行了修复。

开发人员的第一层防护,首先target = target.strip() ,通过strip过滤了空字符,而strip函数过滤仅仅针对于字符串前后两端的空白字符。可以过滤%20javascript:alert(1),但对于 javascript%0a:alert(1)这种是无法进行过滤的。
然后是第二层防护对URL进行urlparse,然后判断scheme是否存在并且在白名单VALID_SCHEMES = [‘http’, ‘https’]中。
联想到之前看的一篇CVE-2017-7233分析,而其中针对于Django URL跳转的bypass正是通过urllib.parse.url.parse的解析错误问题。
这里写个demo测试一下

结果

可以看到在存在%0a的字符下urlparse对URL的解析出现了错误,这里scheme为空。对于形成原因,后面会具体分析一下。
所以这里通过javascript%0a:alert(1)即可绕过这第二层防护,因为这时候的scheme为空,将会跳到下一个步骤,
接着就是第三层防护了,通过判断host的netloc和ref_url的netloc是否相同,其实在绕过上一步之后这里就形同虚设了。因为在类似urljoin(base,target)时候,当target的netloc为空的情况下,其netloc就会被设定为base的netloc,所以这里的防护完全没用。

当判断url参数安全之后,get_redirect_target将会返回url参数的值,这里的返回结果为javascript\n:alert(1),结果将会返回给edit路由函edit_view中的return_url,还有需要注意的是,这里必须有id参数,否则将会直接跳转。

最后return_url通过render函数传递给了前端template。

前端结果就是这样子了,点击跳转,触发弹窗。

关于urlparse的思考
漏洞已经分析完了,成因是主要是因为urllib的urlparse函数的解析错误造成is_safe_url的绕过。从而导致xss,感觉这是一个非常有趣的案例。
对于urlparse解析错误的原因还是不明白,于是决定深入urllib.parse的源码分析一下。
这里写个demo进行分析:

结果
![]()
而在url = unquote(“javascript:alert(1)”)的情况下,结果的协议为正常的javascript。
![]()
着手分析,首先程序进入到urllib.parse.urljoin函数中,这里省略了大部分内容,留下一些我们用到的。urljoin的原理通过urlparse对参数base和url进行了分割,最后结果将结果通过urlunparse生成为URL返回

我们查看一下调用的两次urlparse函数,

第一次urlparse为对base参数http://baidu.com/的正常解析,这里直接给返回结果如下。

接着第二次对于url 参数’javascript\n:alert(1)’的解析,这里就是我们需要着重分析的地方了。执行了urlparse(url, bscheme, allow_fragments)函数,这里看到第二个参数url的scheme最开始被设置为了bscheme,也就是http。
我们跟进到urlparse函数中进行分析通过urlsplit(url, scheme, allow_fragments)函数对URL进行了分割。

跟进到urlsplit函数中,可以看到首先通过I = url.find(‘:’)返回:的位置,然后在接下将会对字符进行一系列判断,以下代码省略部分。

截取后的第一层判断,用于判断协议是否为http,因为我们输入的为javascript%0a:alert(1),所以这里直接跳过。将会继续执行下面的语句,判断:前面的字符是否在URL白名单内,在一番轮训之后检测到\n这个字符不在白名单内,就会break,这里划重点。

scheme_chars,协议允许字符串,这里的scheme遵守了RFC3986文档对与scheme为字母数字,加号,减号,点号的规定。

因为这里有个有趣的点,因为这里break之后,将不会执行下面的else语句,这里的else语句scheme, url = url[:i].lower(), rest,用于设置适用于将:前面的字符串设置为协议的。而这里中途被break,并不会执行。
正常思路下,在if判断为False的情况下,将会直接执行else语句的,然而并不是,(后面才知道原来for else是Python中的语法,这里的else对应的就是for,而不是if)这里用个demo验证下。

上面的demo输出结果为==1,也就说明for else语法中出现break的话,将会跳出判断,不执行下面的else语句。
回到urlsplit函数中,因为跳过了用于设定协议的else语句,所以此时schem依旧为空。接下来将会在对url进行一系列判断和处理,最后返回结果

最后返回的schem,等结果如下。

结果将会返回给回到urlparse中,urlparse在以元组的形式返回给urljoin。urljoin接下来将会检查scheme,我们的schem在开始就被设置为了http,然后会判断netloc是否为空,我们的netloc未设置所以为空,所以会被设置为bnetloc,即baidu.com。

接下来,将会通过urlunparse对scheme和netloc等参数进行拼接,urlunparse在调用urlunsplit函数进行处理。

urlspilit函数

最后urljoin生成的字符串也就为:

其urlparse对象如下,可以看到scheme和netloc都为正常的base url的scheme和netloc。可以知道urlparse问题出在urlsplit中的for循环判断字符是否在URL白名单的地方,在检测到\n,\r等不在白名单中的字符的情况下,将会break,导致后续的else未执行,协议未设置,也就为base url的协议,netloc也为base_url的netloc。如果正常输入javascript:alert(1)的话,其所有字符都在白名单内,不会break,最后的协议也就为正常的JavaScript了。
![]()
最后用一个Python脚本验证一下可用的Payload字符。

测试结果,可用的payload字符有%0a(\n)换行符,%0d(\r)回车符,%09(\t)制表符。

最后关于其它语言其它类库的URL解析差异问题,可以参考orange的SSRF演讲。
总结
回过头来,我们其实可以知道漏洞形成的整体原因了,urlparse解析问题是因为其中的urlsplit函数中的for循环判断字符是否在URL白名单的地方,在检测到\n,\r,\t等不在白名单中的字符的情况下,将会break,导致后续的else未执行,没有设置协议,而此时的协议又是为最开始bscheme的协议。netloc也为base的netloc。而在flask-admin中is_safe_url,仅仅判断了scheme和netloc这两个属性。导致javascript%0a:alert(1)被判断为安全的URL。在服务端中被解析为javascript\n:alert(1),并赋值给前端,还需要注意到的一个点是urlparse和我们测试的所用的谷歌浏览器对于[RFC 3986]文档的实现是存在差异的,根据RFC 3986 中对于scheme的描述,协议仅支持scheme = ALPHA *( ALPHA / DIGIT / “+” / “-” / “.” ),字母,数字,加号减号,点号等字符,从我们之前的分析中可知python中的urlparse库遵守了该规定,所以可以说urlparse的解析并不能算错误问题,因为它确实正确遵守RFC3986中对于URL的规定,协议中仅支持上述字符,而有些浏览器并没有严格遵守这个规定,支持换行和回车等操作符,因为这点也导致了在浏览器处理的时候javascript\n:alert(1)中被认定为合法的URL,导致Payload可执行。

参考
1.Django的两个url跳转漏洞分析:CVE-2017-7233&7234
2.A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages
3.RFC 3986 – Uniform Resource Identifier (URI): Generic Syntax
*本文作者:斗象能力中心TCC-tbag,转载请注明来自FreeBuf.COM
来源:freebuf.com 2019-01-15 09:00:43 by: 斗象智能安全平台
























请登录后发表评论
注册