摘要:本文介绍了一种简单高效的漏洞挖掘方法,即fuzzing。旨在帮助读者深入了解fuzzing测试方法,虽简单高效。但实则也蕴藏玄机。
Fuzzing是指通过构造测试输入,对软件进行大量测试来发现软件中的漏洞的一种模糊测试方法。在CTF中,fuzzing可能不常用,但在现实的漏洞挖掘中,fuzzing因其简单高效的优势,成为非常主流的漏洞挖掘方法。
这里给大家介绍两个漏洞挖掘领域特别厉害的大牛,看看他们如何评价以及使用fuzzing这种方法。
一位是Charlie Miller,他是第一个成功攻击iPhone, G1 Phone的人,是2018-2011年蝉联4届的Pwn2Own的冠军,他提出模糊测试只需要5行python代码,并且运行这5行代码,一定可以找到一些你想要的东西。

5lines of python

另一位大牛是Laurent Gaffié,他在SMB协议上出了很多成绩,比如在3秒之内就在打好补丁的MS07-063上找到了一个bug,CVE-2009-3103,CVE-2009-3676, CVE-2010-0270,CVE-2010-0016,CVE-2010-0017,CVE-2010-0470, CVE-2010-0476,CVE-2010-0477,CVE-2010-2550,CVE-2011-1869等都是他发现的漏洞。并且他将自己的模糊测试的方法称为“Home Made Fuzzer”,从这个名称上就可以看出,fuzzing的代码就是真的很简单。
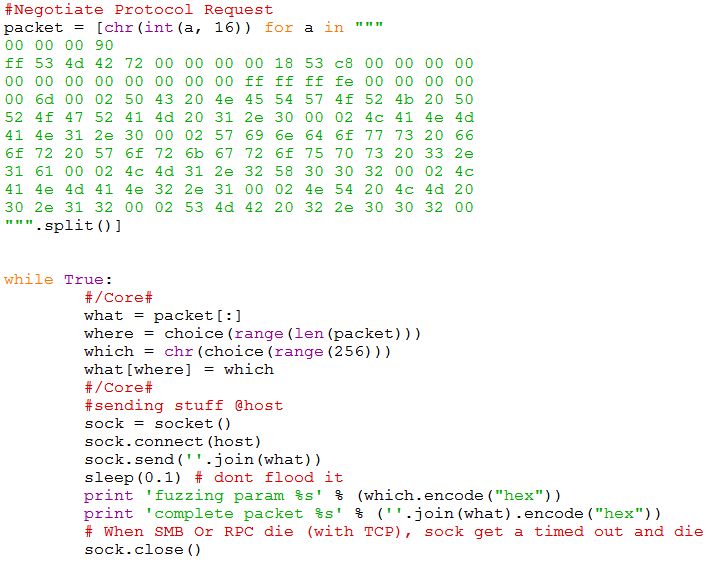
HomeMade Fuzzer
Charlie Miller和Laurent Gaffié向我们证实了:真的可以通过简单的几行代码就可以进行漏洞挖掘,幸运的话,甚至还可以拿到0 day漏洞,好像没有什么技术含量的样子。
但真的是这样吗?Fuzzing是没有技术含量的漏洞挖掘技术吗?漏洞发现真的靠运气吗?如果真的靠运气,那么为什么运气好的总是像Charlie Miller和Laurent Gaffié这样的人呢?
其实不然,在简单的几行代码背后,要完成一项模糊测试,是需要进行大量的工作的。为什么这么说呢?接下来,我将通过对fuzzing的详细介绍来做解释。Fuzzing基本的实现方案如下所示:
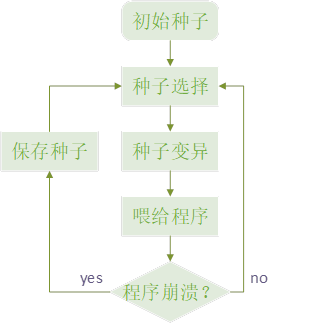
Fuzzing基本的实现方案
1. 需要大量的测试用例
进行模糊测试的首要条件就是需要大量的测试用例(即种子输入),例如Charlie Miller对Reader 9.2.0进行的fuzzing测试,他首先从网上的1515个文件变异得到3036000个测试用例进行测试,最后得到crash。在对Preview这个软件做测试时,用了大概2790000个测试用例进行测试才得以拿到crash。这些数字跟我们的直观感受就是我们需要获得大量的测试用例,才能保证模糊测试过程中拿到程序的crash。
2. 对测试用例做过滤
实际情况中,并不是说拿很多的测试用例就可以去测试软件就可以拿到漏洞,即fuzzing测试并不是简单的关于生成测试用例去做测试的故事,而是一个关于怎么对测试用例做过滤的故事。并不是说得到几十万量级的测试用例之后,就可以拿到漏洞了,而实际上,这几十万个测试用例都是精品,用这些精品进行测试才得以发现的漏洞,那么怎么把这些精品过滤出来,这才是关键,也是我们在进行fuzzing测试过程中需要做的第二件重要的准备工作。
比如Charlie Miller在测试PDF的时候,他把网上所有能够下载到的80000个PDF文档都下载下来,然后找到一个最小的子集,这个子集的代码覆盖率和全集的代码覆盖率是一样的,这个最小的子集也就是软件测试中的最初始的集合—1515个文件,在这个最初始的集合上再去做fuzz,这就是一个筛选的过程,我们可以用代码覆盖率作为衡量标准,当然也可以选择其他合适的标准来完成这一筛选过程。
3. 要用正确的方法
Laurent Gaffié说过,他在研究SMB协议的远程调用接口的时候,最先做了很多工作,结果都失败了,直到他将策略改变成了用单字节的网络数据包,才有了大量的产量。所以fuzzing是要讲方法的,要想清楚可能出问题的是什么地方,你要用什么样的方法去把这个东西找出来,关于方法,每年都有很多的论文,大家可以去看。
Charlie Miller也说,很多关于fuzzing的报告都是讲述如何成功,但是现实中的fuzzing大部分都是讲关于失败的。可见在现实中做fuzz测试的时候,你会遇到很多挫折。所以找到正确的方法非常重要!CharlieMiller和Laurent Gaffié给出的代码虽然看起来很不起眼,但一旦找到了正确的方法,得到的结果往往很令人惊喜。
4. 观念问题:要用90%的时间阅读文档
还有一个问题,就是做fuzzing的人,并不是简单的写几行代码,对着软件一通测试就会出来结果。在做fuzzing之前,会有很多的时间是花在阅读文档上的。
对于复杂的程序,我们要去分析这个程序的功能是什么,它可能出问题的地方在什么位置,会有大量的几乎90%的时间是花在这上面的,这是Charlie Miller和Laurent Gaffié的一个评估。
那么现在最厉害的一个fuzzing的工具是什么呢?
AFL,它是目前最受欢迎的一个工具,是一个导向型的fuzzing工具。 Fuzzing通常由盲fuzzing(blind fuzzing)和导向性fuzzing(guided fuzzing)两种。blind fuzzing生成测试数据的时候不考虑数据的质量,通过大量测试数据来概率性地触发漏洞。Guided fuzzing则关注测试数据的质量,期望生成更有效的测试数据来触发漏洞的概率。比如,通过测试覆盖率来衡量测试输入的质量,希望生成有更高测试覆盖率的数据,从而提升触发漏洞的概率。
AFL这个工具出来的一个起因就是AFL的开发者认为盲fuzzing的效率是比较低的;第二个原因就是Charlie Miller和Laurent Gaffié所做的样本筛选的方法是有效果的;还有第三个原因就是符号执行,符号执行在理论是非常不错的,但在实际中经常受到可行性、性能等方面的限制。于是在这样一个背景下,AFL出现了。
AFL有两个关键词:指令插桩和边覆盖。首先AFL是基于插桩的,能够辅助程序分析;其次AFL是基于边覆盖的,是对Charlie Miller等人基于块覆盖用样本筛选的一个改进和提升。
下一篇文章中,我们会围绕AFL展开介绍,会讲到块覆盖与边覆盖的区别,AFL如何使用较低的开销实现的边覆盖以及边覆盖带来的好处,AFL的工作原理等问题。简单预告一下,AFL用了3行代码做了边覆盖,如果做块覆盖,正常来说是两行代码。
*本文作者:DigApis,转载请注明来自FreeBuf.COM
来源:freebuf.com 2019-01-14 09:00:13 by: DigApis