0x00 为什么
自从小弟上次发布了《自己动手打造Github代码泄露监控工具》一文后,承蒙各位客官老爷捧场,阅读量已经好几十万了,Github也受到了一些大佬的关注。本着精益求精的黑客精神(其实是上次的工具版本存在许多不足),经过一段时间的运行后,确实工具存在一定精确性的问题,故有此文章。
0x01 怎么改进
改进主要从以下几个方面入手:
1.搜索排序方式变更
上篇文章通过Github搜索排序Best Match来爬去前面6页来查找泄露信息,优点在于:可以匹配到最符合关键词的项目,比如匹配域名为baidu.com的相关代码。然后在最匹配的关键词中寻找payload,如password,username等;缺点较为明显:主关键词单一,虽然可以加入多个主关键词,但是匹配结果却不能收录最新的记录或代码。最为严重的问题是最新泄露的符合关键词的敏感信息可能无法获取到。
2.搜索方式变更
单一的域名关键词搜索内容有限,Github呈现的结果也非常多。另外Github的内部搜索算法的影响也会让搜索结果不尽人意。举个栗子,搜索baidu.com, Github呈现如下图:
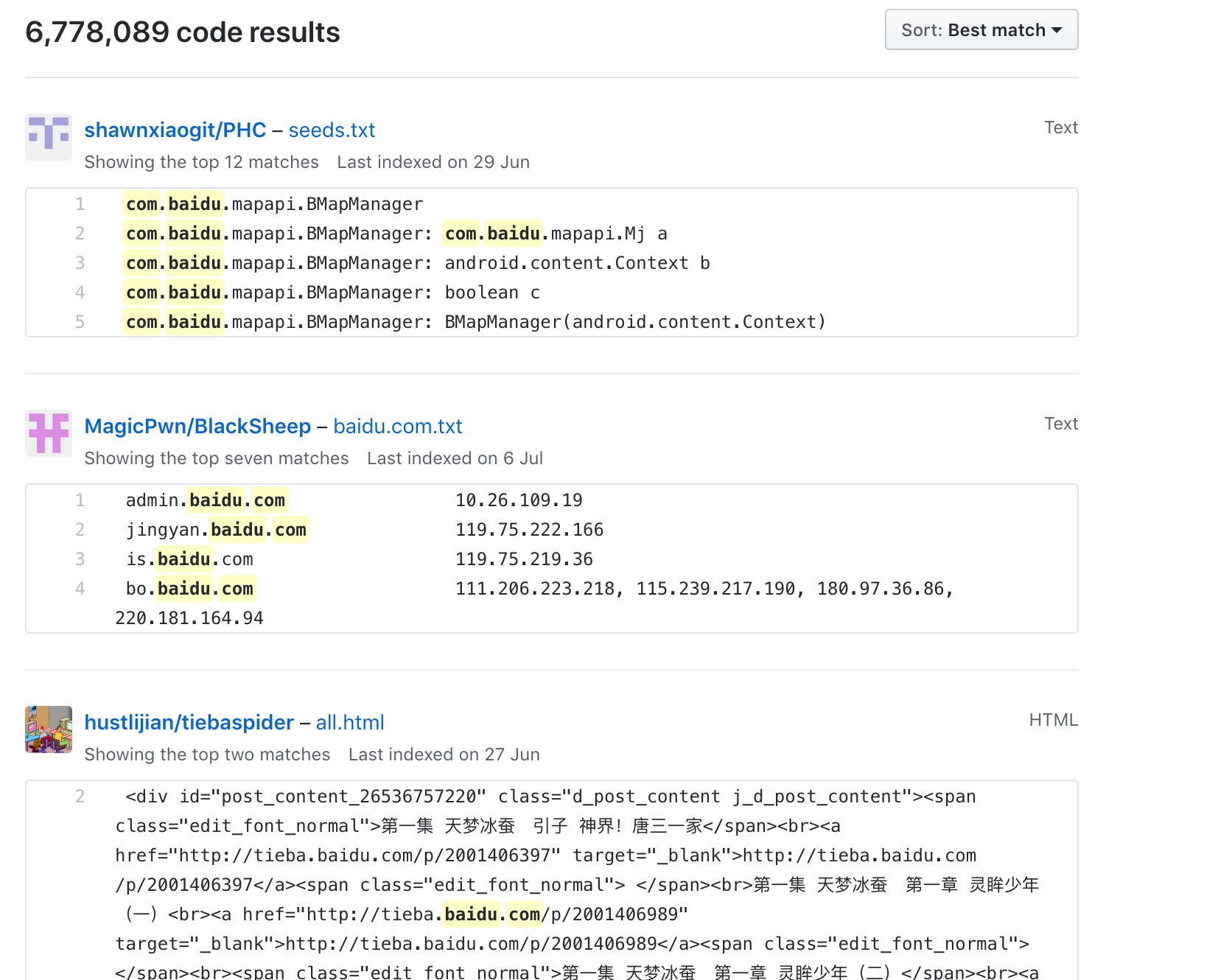 看图可知,最匹配的代码结果其实可能没有包含我们想要的诸如password, username, database等敏感信息。有兴趣的童鞋可以自行搜索。细心的童鞋可能看到收录的时间五花八门,有6月29的,7月6号的等等。现在是11月了啊,这结果根本不是最新的,不准确性和非及时性的问题体现出来了。即便是搜索到几十页,上百页,也可能没有包含我们关注的信息泄露代码,所以必须改进。
看图可知,最匹配的代码结果其实可能没有包含我们想要的诸如password, username, database等敏感信息。有兴趣的童鞋可以自行搜索。细心的童鞋可能看到收录的时间五花八门,有6月29的,7月6号的等等。现在是11月了啊,这结果根本不是最新的,不准确性和非及时性的问题体现出来了。即便是搜索到几十页,上百页,也可能没有包含我们关注的信息泄露代码,所以必须改进。
3.存储方式和呈现效果变更
此前Github仓库的链接爬去后都通过excel来存储,Python处理这种IO还算性能不差。不过用excel来存储信息确实略显陈旧,新版本则采用sqlite来存储url和代码,这是存储方式的变更。另外在呈现效果虽然还是通过邮件来呈现,但是加入了代码部分的展现,关键词高亮显示,方便监控者阅读。具体效果如下:
 接下来我们将针对提出的改进要点来修改监控工具~_~
接下来我们将针对提出的改进要点来修改监控工具~_~
0x02 具体改进方法
1.搜索排序方式改进
这个要点的变更,其实变更代码比较少,只是变更搜索代码的url即可:
https://github.com/search?o=desc&p=2&q=baidu.com&s=indexed&type=Code通过变更排序方式,把最新收录的排在前面,这样就可以得到最新的代码收录信息。
对比先前版本url:
https://github.com/search?o=desc&q=baidu.com&s=&type=Code2.搜索方式改进
搜索方式由单一关键词更改为关键词组合,例如,公司域名为:“example.com, 需要查找的敏感关键词为:password,那么我们组合为:“example.com + password” 进行搜索。新的改进版本不仅会收录可能存在代码泄露仓库的url,同时也会收录简要代码部分。然后在后续加入到邮件报警和数据库的代码中进行example 和 password进行匹配,如果两个关键词都存在,则再比对数据库中的基线里面是否存在对应代码的url,如果存在则不加入基线中,反之,加入到基线中。我来看代码部分:
def hunter(gUser , gPass, keywords):#根据关键词获取想要查询的内容
global codes
global tUrls
try:
#代码搜索
s = login_github(gUser,gPass)
print('登陆成功,正在检索泄露信息.......')
sleep(1)
codes = []
tUrls = []
#新加入2条正则匹配,第一条匹配搜索出来的代码部分;第二条则进行高亮显示关键词
pattern_code = re.compile( r'<div class="file-box blob-wrapper">(.*?)</div> ', re.S)
pattern_sub = re.compile( r'<em>', re.S)
for keyword in keywords:
for page in tqdm(range(1, 7)):
#更改搜索排序方式的url,收录可能存在泄漏的url还是使用xpath解析
search_code = 'https://github.com/search?o=desc&p=' + str(page) + '&q=' + keyword +'&s=indexed&type=Code'
resp = s.get(search_code)
results_code = resp.text
dom_tree_code = etree.HTML(results_code)
#获取存在信息泄露的链接地址
Urls = dom_tree_code.xpath( '//div[@class="flex-auto min-width-0 col-10"]/a[2]/@href')
for url in Urls:
url = 'https://github.com' + url
tUrls.append(url)
#获取代码部分,先获得整个包含泄露代码的最上层DIV对象,再把对象进行字符化,便于使用正则进行匹配泄露代码部分的div
results = dom_tree_code.xpath( '//div[@class="code-list-item col-12 py-4 code-list-item-public "]')
for div in results:
result = etree.tostring(div, pretty_print=True, method= "html")
code = str(result, encoding='utf-8')
#如果存在<div class="file-box blob-wrapper">此标签则匹配泄露的关键代码部分,不存在则为空。
if '<div class="file-box blob-wrapper">' in code:
data = pattern_code.findall(code)
codes.append(pattern_sub.sub( '<em style="color:red">', data[0]))
else:
codes.append(' ')
return tUrls, codes
except Exception as e:
#如发生错误,则写入文件并且打印出来
error_Record(str(e), traceback. format_exc())
print(e)
正如代码中的注释所讲,获取泄露地址的url还是采用xpath的解析。然而在泄露的代码部分,使用的是正则。
为什么使用正则,第一,为了把包含泄露代码的table获取下来以便发送邮件(发送邮件时只需要简单加入css样式即可);第二,这样避免利用xpath去解析table下的行,这样做稍显麻烦。
其实在考虑这部分逻辑的时候遇到一个坑,那就是有些可能存在泄漏的仓库,有url,却没有代码部分,没有代码部分就不会存在'<div class=”file-box blob-wrapper”>’ 这个div,这样获取的url和代码就不能一一对应,会发现url和代码错位了,根本就不准确。所以要先获取 ‘<div class=”file-box blob-wrapper”>‘ 的父div即'<div class=”code-list-item col-12 py-4 code-list-item-public “>’,然后判断是否存在代码部分,如果不存在则泄露代码的列表当前位置为空或空格,存在则搜索代码泄露部分加入到列表中。这样避免了有url没有code的问题。
 同时,在加入泄露代码的列表时,通过正则匹配进行css的替换把获取的table标签中的<em>标签替换为<em sytle=”color:red”>。这样以后发送的邮件正文中关键词则被标红。
同时,在加入泄露代码的列表时,通过正则匹配进行css的替换把获取的table标签中的<em>标签替换为<em sytle=”color:red”>。这样以后发送的邮件正文中关键词则被标红。
最后在异常处理部分加入了出现异常就写入文件,并且把trackback一并写入文件,以后排查错误时可以更准确方便。
3.存储方式和呈现方式改进
存储方式变更为数据库存储采用sqlite3,简单易用,小型存储需求可以满足。创建了Baseline表,包含url和code两个字段。如图所示:

此数据库主要用于对比去重,基线建立,如数据库中不存在泄露的url则加入其中,然后通过邮件发预警。反之则不发送邮件预警。代码如下:
def insert_DB(url , code):
try:
conn = sqlite3.connect( 'hunter.db')
cursor = conn.cursor()
cursor.execute('CREATE TABLE IF NOT EXISTS Baseline (url varchar(1000) primary key, code varchar(10000))' )
cursor.execute('INSERT OR REPLACE INTO Baseline (url, code) values (?,?)' , (url, code))
cursor.close
conn.commit()
conn.close()
except Exception as e:
print("数据库操作失败!\n ")
error_Record(str(e), traceback. format_exc())
print(e)
def compare_DB_Url(url ):
try:
con = sqlite3.connect( 'hunter.db')
cur = con.cursor()
cur.execute('SELECT url from Baseline where url = ?' , (url,))
results = cur.fetchall()
cur.close()
con.commit()
con.close()
return results
except Exception as e:
error_Record(str(e), traceback. format_exc())
print(e)
呈现方式还是采用邮件预警,邮件格式采用html方便插入table并且设置css。邮件发送代码如下:
def send_mail(host , username, password, sender , receivers, message):
def _format_addr( s):
name,addr = parseaddr(s)
return formataddr(( Header(name,'utf-8').encode(),addr))
msg = MIMEText(message, 'html', 'utf-8')
subject = 'Github信息泄露监控通知'
msg['Subject'] = Header(subject, 'utf-8') .encode()
msg['From'] = _format_addr('Github信息泄露监控<%s>' % sender)
msg['To'] = ','.join(receivers)
try:
smtp_obj = smtplib.SMTP(host, 25)
smtp_obj.login(username, password)
smtp_obj.sendmail(sender, receivers, msg.as_string ())
print('邮件发送成功!')
smtp_obj.close()
except Exception as err:
error_Record(str(err), traceback. format_exc())
print(err)
0x03 预警逻辑和基线建立
预警逻辑和基线建立代码都放在了主函数中,读取配置文件与之前Github信息泄露监控工具无异。而在关键词和payload读取时则进行了改动,搜索关键词由原来的单一,变为组合型关键词,即keyword + payload。搜索代码中存在的关键词和payload又将两者拆分,这样就保证了监控者关注的关键词和payload 100%存在于Github新收录的条目中,关键代码如下:
if __name__ == '__main__' :
config = configparser.ConfigParser()
config.read('info.ini')
g_User = config['Github' ]['user']
g_Pass = config['Github' ]['password']
host = config['EMAIL' ]['host']
m_User = config['EMAIL' ]['user']
m_Pass = config['EMAIL' ]['password']
m_sender = config['SENDER' ]['sender']
receivers = []
for k in config ['RECEIVER']:
receivers.append(config['RECEIVER'][k])
keywords = []
#组合关键词,keyword + payload,两者之间加入“+”号,符合Github搜索语法
for keyword in config ['KEYWORD']:
for payload in config ['PAYLOADS']:
keywords.append(config['KEYWORD'][keyword] + '+' + config[ 'PAYLOADS'][payload])
message = 'Dear all<br><br>未发现任何新增敏感信息!'
tUrls, codes= hunter(g_User, g_Pass, keywords)
target_codes = []
#第一次运行会查找是否存在数据文件,如果不存在则新建,存在则进行新增条目查找
if os.path.exists( 'hunter.db'):
print("存在数据库文件,进行新增数据查找......")
#拆分关键词,在泄露的代码中查找关键词和payload.如果两者都存在则进行下一步数据库查找
for keyword in keywords:
payload = keyword.split( '+')
for i in range(0, len(tUrls)) :
if (payload[0 ] in codes[i ]) and (payload[1 ] in codes[i ]):
#如果数据库中返回的值为空,则说明该条目在数据库中不存在,那么添加到target_codes里面用户发送邮件,并且添加到数据库中
if not compare_DB_Url(tUrls[i]):
target_codes.append('<br><br><br>' + '链接:' + tUrls[i] + '<br><br>')
target_codes.append('简要代码如下:<br><div style="border:1px solid #bfd1eb;background:#f3faff">' + codes[i] + '</div>' )
insert_DB(tUrls[i], codes[i])
else:
print("未发现数据库文件,创建并建立基线......")
for keyword in keywords:
payload = keyword.split( '+')
for i in range(0, len(tUrls)) :
#关键词和payload同时存在则加入到target_codes,并写入数据库
if (payload[0 ] in codes[i ]) and (payload[1 ] in codes[i ]):
target_codes.append('<br><br><br>' + '链接:' + tUrls[i] + '<br><br>')
target_codes.append('简要代码如下:<br><div style="border:1px solid #bfd1eb;background:#f3faff">' + codes[i] + '</div>' )
insert_DB(tUrls[i], codes[i])
#当target_codes有数据时,则进行邮件预警
if target_codes:
warning = ''. join(target_codes)
result = 'Dear all<br><br>发现信息泄露! ' + '一共发现{}条'.format (int(len(target_codes)/ 2)) + warning
send_mail(host, m_User, m_Pass, m_sender, receivers, result)
else:
send_mail(host, m_User, m_Pass, m_sender, receivers, message)
首先进行数据库文件查找,如果是首次运行,那么会在程序目录下生成一个db文件,名称为hunter。然后进行keyword和payload查找,当keyword和payload都存在于爬下来的泄露代码中,那么则加入到target_codes中用于邮件预警,最后进行数据库写入操作创建基线;如果数据库存在则说明基线存在,那么则进行新增数据查找。同理,当keyword和payload存在泄漏代码中,并且还必须满足获取的泄露地址url不存在于数据库Baseline表中则加入到target_codes,最后写入表中。在加入target_codes时还写入了换行符,css样式等,具体可参考上面代码。程序最后发送预警邮件,如target_codes有数据,那么进行预警。如果不存在数据则进行通知。
0x04 效果呈现
具体效果如下图所示:

图中被抹去的是关键词,keyword和payload都以红色显示。根据自己需求进行修改即可。
0x05 总结
所谓人无完人,程序也是一样,只有通过不断改进,才能达到近乎完美得到自己想要的效果。我觉得最重要的是改进的过程,在这个过程会遇到各种问题,各种难题,我们要做的是去一个个克服,不能半途而废。只有这样才能不断的提升自己,提高自己的各项技能水平。安全之路还长,吾将上下而求索!谢谢各位客官老爷耐心读完!最新完整代码还是那个地址:
自己动手打造系列下期预告:自己动手打造自动化安全扫描平台
*本文作者:ztencmcp,转载请注明来自FreeBuf.COM
来源:freebuf.com 2018-11-22 11:30:40 by: ztencmcp




















请登录后发表评论
注册