AI模型的安全主要包括以下几个方面。
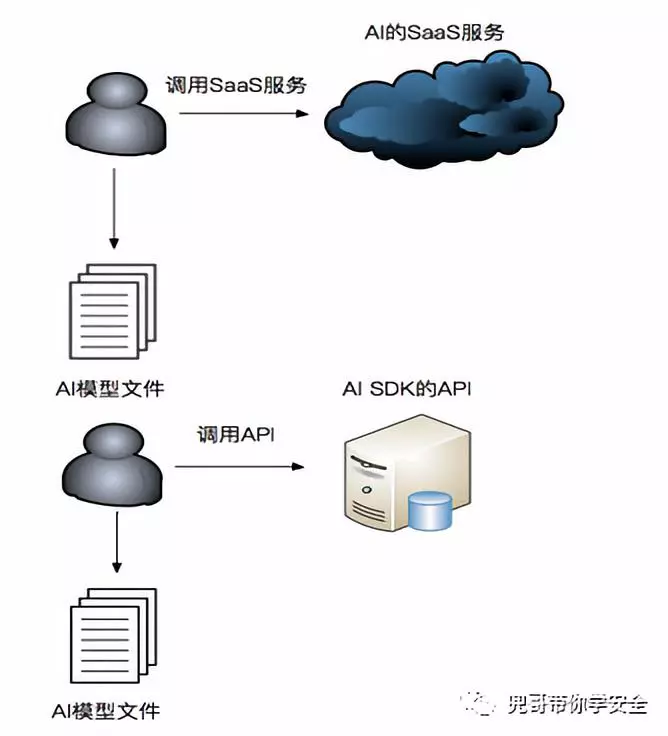
偷取模型
数据投毒
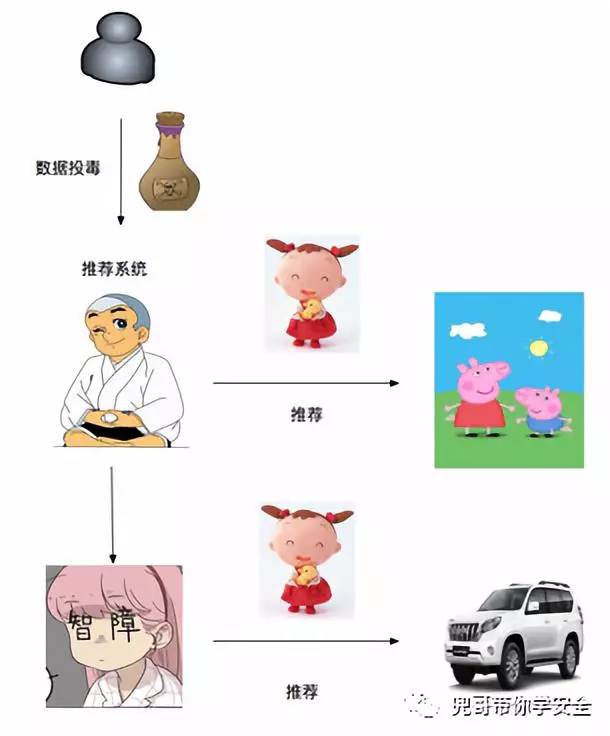
欺骗模型
其中欺骗模型又称为对抗样本的攻击成本更低,影响更直接,成为AI模型安全研究重点。
经典的对抗样本案例之一就是欺骗图像分类模型,在图像上增加肉眼难以识别的修改,就可以让模型搞不清是否带了耳环,把女人识别为男人。

另外一个经典的对抗样本案例就是欺骗物体识别,而且这个攻击是可以在物理世界上生效的,只要在Stop的牌子上贴上静心设计的贴纸,就可以让物理识别时效,无法捕捉到Stop的指示牌。

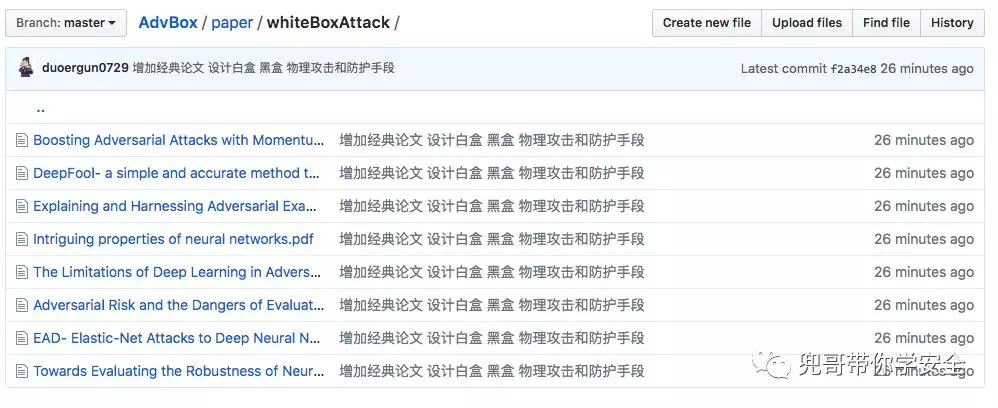
经典论文
对抗样本是不是很有趣?如果想深刻了解这些攻击原理,我们收集了这个领域的经典论文,并且在我们的github上传了白盒攻击的论文。后继我们还将继续在github上传黑盒攻击、物理攻击以及对应的防御方法的论文。我们的github地址为:
我们在github上开源了AdvBox,一个实现对抗样本白盒、黑盒算法的工具箱,如果想快速实践对抗样本的实验,可以clone我们项目,上面有详细案例,欢迎star和fork。
git clone https://github.com/baidu/AdvBox.git白盒攻击
黑盒攻击

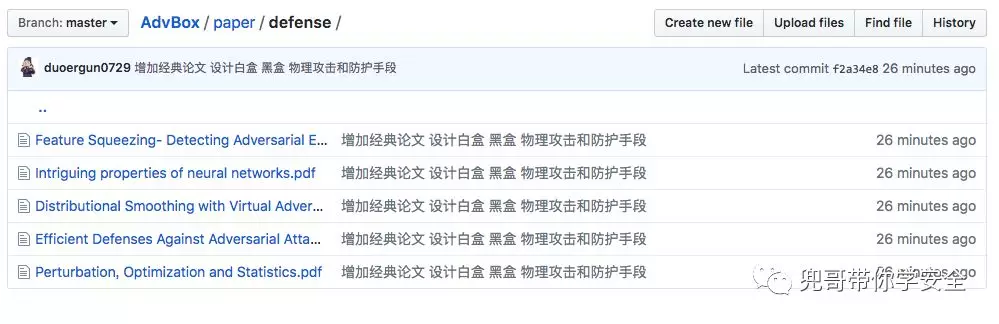
防御方法
来源:freebuf.com 2018-08-21 13:23:45 by: 兜哥
正文完