一、概述
Webshell是攻击者使用的恶意脚本,其目的是升级和维护对已经受到攻击的WEB应用程序的持久访问。Webshell本身不能攻击或利用远程漏洞,因此它始终是攻击的第二步。
攻击者可以利用常见的漏洞,如SQL注入、远程文件包含(RFI)、FTP,甚至使用跨站点脚本(XSS)作为攻击的一部分,以上传恶意脚本。通用功能包括但不限于shell命令执行、代码执行、数据库枚举和文件管理。
为什么使用webshell ?
1.持续的远程访问
Webshell通常包含一个后门,允许攻击者远程访问,并能在任何时候控制服务器。这样攻击者省去了每次访问攻击服务器需要利用漏洞的时间。攻击者也可能选择自己修复漏洞,以确保没有其他人会利用该漏洞。这样,攻击者可以保持低调,避免与管理员进行任何交互。值得一提的是,一些流行的Webshell使用密码验证和其他技术来确保只有上传Webshell的攻击者才能访问它。这些技术包括将脚本锁定到特定的自定义HTTP头、特定的cookie值、特定的IP地址或这些技术的组合。
2.特权升级
除非服务器配置错误,否则webshell将在web服务器的用户权限下运行,该用户权限有限的。通过使用webshell,攻击者可以尝试通过利用系统上的本地漏洞来执行权限升级攻击,以假定根权限,在Linux和其他基于Unix的操作系统中,根权限是“超级用户”。通过访问根帐户,攻击者基本上可以在系统上做任何事情,包括安装软件、更改权限、添加和删除用户、窃取密码、读取电子邮件等等。
黑客在入侵一个网站后,通常会将asp或php后门文件与网站服务器web目录下正常的网页文件混在一起,然后就可以使用浏览器来访问asp或者php后门,得到一个命令执行环境,以达到控制网站服务器的目的。Webshell一般有三种检测方式:基于流量的方式、基于Agent模式、基于日志分析模式。本文重点研究基于流量的webshell检测。
整个流程,先是采集webshell数据,然后结合网络安全专家知识对webshell产生的流量和正常流量进行观察研究、统计分析,挖掘出较好的能区分两类流量的特征,然后选用二分类算法训练模型,然后评估算法性能做出参数调整等,最后将模型做工程化落地。文中会依次展开详细说明。
二、数据采集
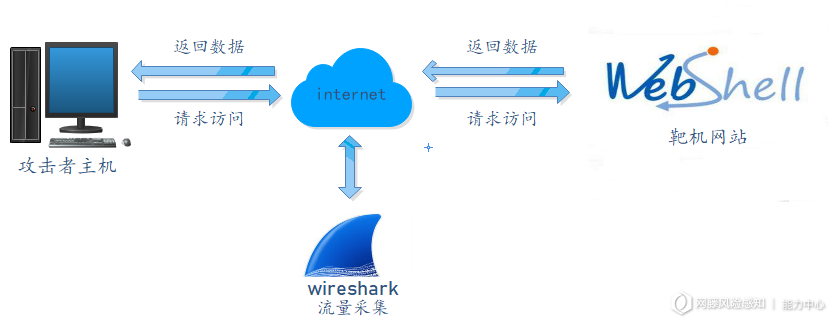
在真实的环境中webshell样本缺少,基本在数万条的http流量中,都难有一条webshell所产生的流量。因此对于机器学习来说,高质量、多数量的的样本将会是个挑战。为了解决这个样本难的棘手问题,我们特意模拟搭建了webshell入侵的环境,按照webshell的种类、攻击的行为写好自动化脚本,运行时产生大量webshell流量,使用网络嗅探工具(如Wireshark,Tcpdump等)收集了Webshell流量。 如图1基本展示了整个数据采集的流程。

( 图1)
2.1 构建数据类型
webshell大致可分为以下三大类:
●一句话
该webshell通过工具菜刀进行连接,可实现的功能包括对文件的增删修、数据库的CRUD、命令执行。
●大马
该webshell文件较大,包含的服务端代码多。功能强大,除了包含对文件的增删修、数据库的CRUD、命令执行。还包括提权,内网扫描、反弹shell等功能。
●小马
该webshell文件小,代码量小。包含的功能比较单一,实现的功能为一个或两个。主要为文件上传或服务端执行文件下载、命令执行等功能。
在构建数据采集类型时,根据常见的webshell类型并结合执行命令进行划分,如下所示:
是否需要登陆:
●direct:无需登陆,直接访问即可。可实现的功能较多;
●login:需要密码或账户进行登陆,又分为登陆前与登陆后(before/latter);
以是否需要登陆划分完后开始以用户行为进行划分即操作类型。
操作类型:
●cmd:命令执行;
●file:文件操作;
●sql:数据库操作。
2.2 搭建数据收集环境
流量采集搭建的整体环境如下图2所示:
(图2)
系统环境为Linux虚拟机,通过建立桥接模式与宿主服务器完成网络数据交互。各类webshell运行的环境如下:
●PHP:phpstudy
●JSP:jspstudy
●ASP:Ajiu AspWebServer+Mysql
本地主机采用Wireshark对webshell的网络流量进行收集和保存。
2.3 流量数据生成
●direct:
直接访问的webshell,采用脚本的方式对其进行批量访问,产生对webshell访问的流量数据。对文件的操作、命令执行、数据库操作的流量,采用手工录入。
●login:
登陆型webshell,采用脚本进行登陆,运行selenium模块实现模拟浏览器登陆webshell。解决因cookie验证机制而无法成功登陆webshell的问题。对文件的操作、命令执行、数据库操作的流量,采用手工录入。
●cmd:
该webshell的利用方式,采用脚本的方式实现。根据脚本,实现不同系统命令的执行,获取相应的结果。
●caidao:
菜刀型webshell的界面访问及登陆采取脚本的方式来批量实现。
2.4 流量数据分类
流量数据包命名规则为(webshell类型)_(操作),按照具体的类型和操作进行划分,分开收集。保证流量数据的类型统一。
2.5 流量收集
本地主机采用WireShark进行流量收集。
三、基于流量的webshell检测
3.1 特征工程
使用机器学习构建基于流量检测模型,重要步骤是对webshell流量进行特征挖掘分析。特征工程要结合webshell的特点和相关的专家知识去挖掘。先根据webshell的行为特点总结了以下几条webshell本身自带的特征。
(1)存在系统调用的命令执行函数,如eval、system、cmd_shell、assert等;
(2)存在系统调用的文件操作函数,如fopen、fwrite、readdir等;
(3)存在数据库操作函数,调用系统自身的存储过程来连接数据库操作;
(4)具备很深的自身隐藏性、可伪装性,可长期潜伏到web源码中;
(5)衍生变种多,可通过自定义加解密函数、利用xor、字符串反转、压缩、截断重组等方法来绕过检测;
(6)访问IP少,访问次数少,页面孤立,传统防火墙无法进行拦截,无系统操作日志;
(7)产生payload流量,在web日志中有记录产生。
流量检测是为了区分正常访问与webshell,因此也简单的陈列下webshell与正常业务的网页有何区别,如图3所示:
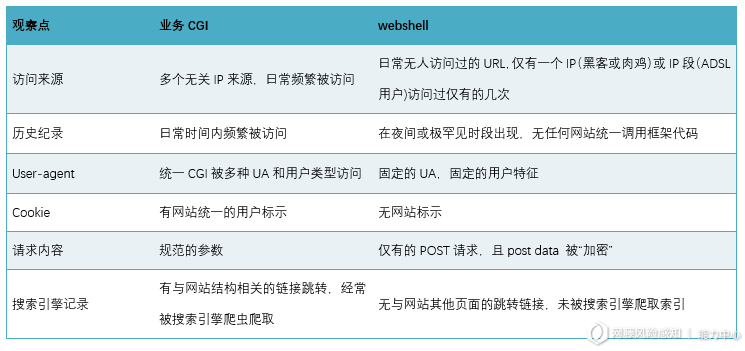
(图3)
3.1.1 特征挖掘
根据特征工程中,收集到的专家经验知识,和实际的历史数据统计分析后,下面开始我们的特征分析。(注:过多技术细节披露较为敏感,因此仅枚举部分特征进行阐述)
1.基于关键词的特征
对于webshell本身的行为分析 ,它带有对于系统调用、系统配置、数据库、文件的操作动作,它的行为方式决定了它的数据流量中多带参数具有一些明显的特征,另外再关键词匹配之前先对流量进行decode操作。查阅各类webshell操作方式,以及观察了所产生的数据流量进行统计分析后,共采集了部分关键词罗列如图4。经统计发现这些关键词在正负样本中出现的占比十分悬殊,因此作为特征是非常合适的。以下是正负样本中关键词出现次数的对比条形图(如图4),可以显示出分布差异。
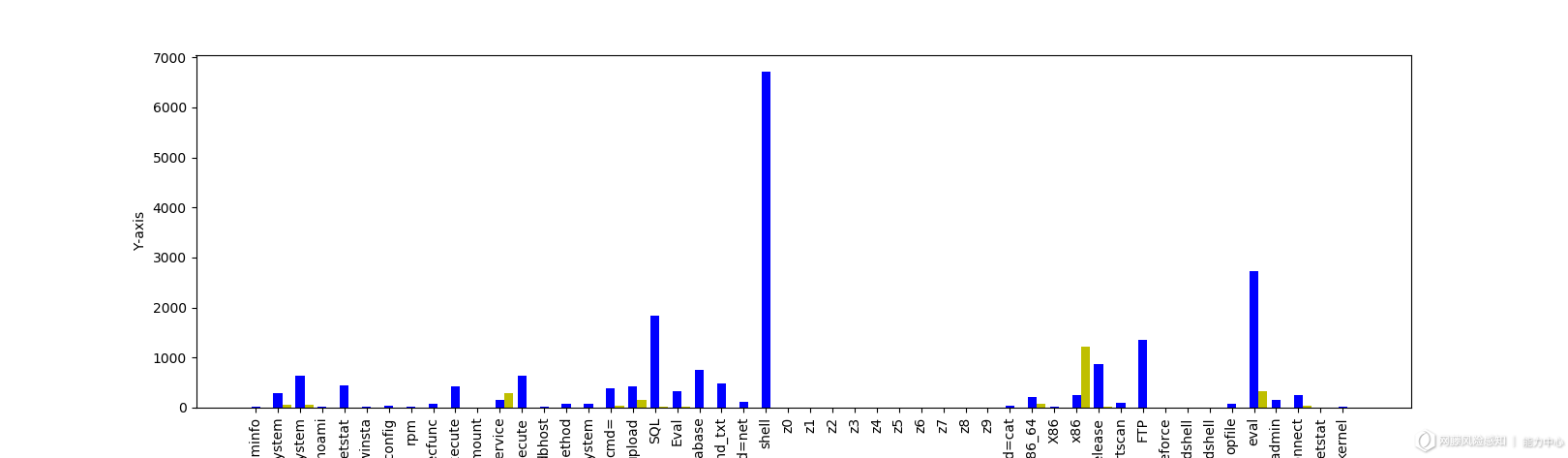
(图4)
2.流量中get/post参数个数
经观察发现,一般来说webshell get/post的参数个数比较少,可作为一个特征。
3.流量中get/post的信息熵
一般请求都会向服务器提交数据,webshell也不例外。但是,如果提交的数据经过加密或者编码处理了,其熵就会变大。对于正常的web业务系统来说,如果向某一URI提交数据的熵明显偏大于其他页面,那么该URI对应的源码文件就比较可疑了。而一般做了加密通信的webshell提交数据的熵值会偏大,所以就可以检测出来。例如如下对比:
正常页面:”pid=12673&aut=false&type=low”
Webshell: ”ac=ferf234cDV3T234jyrFR3yu4F3rtDW2R354”
4.基于cookie的特征提取
在正常的http访问中,因为http访问是无状态的协议,服务器也不会自动维护客户的上下文信息,于是采用session来保存上下文信息。session是存储在服务器端的,为了降低服务器存储的成本于是当有http请求时,服务器会返回一个cookie来记录sessionID并保存在浏览器本地,下一次访问时request中会携带cookie。cookie的内容主要包括:名字,值,过期时间,路径和域。路径与域一起构成cookie的作用范围。据观察分析,webShell所产生的cookie有的为空,有的虽然有键值对的结构但是基本数量非常少,且命名没有实际的含义。所以提取这一特征用来区分webShell和正常网站访问。
另外从cookie角度思考,可以发现webshell的键值对会比较混乱,不像正常流量中的那么有规律或是参数有实际可读含义的。如下选取了一条webshell的Cookie,可以发现键值对的值比较混乱。因此选取键值对的熵值作为特征。
Cookie:KCNLMSXUMLVECYYYBRTQ=DFCXBTJMTFLRLRAJHTQLDNOXSKXPZEIXJUFVNNTA
5.返回网页结构相似度值
黑客在进行webshell提权攻击的时候,通常是用已经有的webshell工具,比如拿大马进行直接使用或者稍作修改。因此很多返回的页面具有结构相似性,可以提取网页结构相似度这一特征进行比对。设计思路为,与已经采集的webshell产生的网页结构相似度进行对比,用返回网页结构相似度作为一个特征。
6.网页路径层数
黑客在成功入侵一个网站,植入webshell网页,通常需要这些后门软件具有隐蔽性,因此网页路径会比较深,网页藏匿的比较深,不易被正常浏览者发现。
7.访问时间段
webshell和正常业务相比,浏览的时间是有差异的,黑客通常会选择在正常流量稀少的时间进行访问。因此抽出时间特征作为一个维度。按照时间大类特征,可以展开几下几种小类特征, 一天中哪个时间段(hour_0-23) ,一周中星期几(week_monday…),一年中哪个星期,一年中哪个季度,工作日、周末。
8.有无referer
在流量中,如果网页没有跳转过来的上一页网页,那么referer参数将为空。一般的小马和一句话webshell鲜有跳转关系,大马登陆的首页也和上一页网页没有跳转关系,因此选此特征作为一种辅助判断。
3.1.2 特征提取
综上分析,共提取了关键词、网页路径结构层次数、cookie键值对数、返回网页结构相似度、POST/GET熵值、cookie键值对熵值等多个特征(注:过多技术细节披露较为敏感,因此仅枚举部分特征进行阐述)。并使用数据采集阶段生成的数据作为数据源,生成机器学习模型特征,之后将特征做归一化处理。其中正常流量60349条,webshell流量51070条。
3.2 模型构建及评估
选取了adboost、SVM、随机森林、逻辑回归四种算法进模型训练,其中正常流量60349条,webshell流量51070条。各模型训练效果对比如下图5所示。综合考量到最小化算法运行时间,和最大化可解释性,在多个算法检测效果相似情况下,选择随机森林作为实际产品化使用的模型算法。
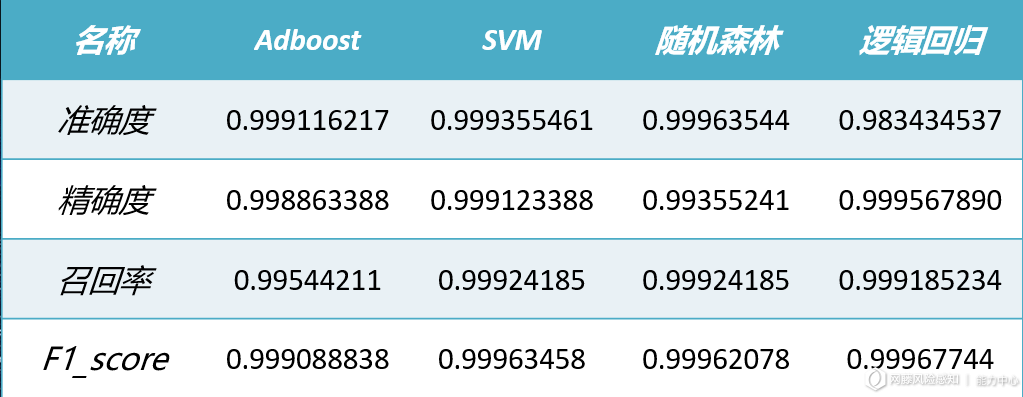
(图5)
四、具体实施
4.1 检测流程
基于机器学习的webshell检测整体业务逻辑如下图6所示,简述如下:首先,从各种终端设备和第三方库中导入数据进行特征提取模型训练;之后,将训练好的模型部署到生产环境中对真实数据做检测,对检出产生告警信息;最后将检出结果做人工确认,并将误报数据重新导入训练库中定期重训练模型。
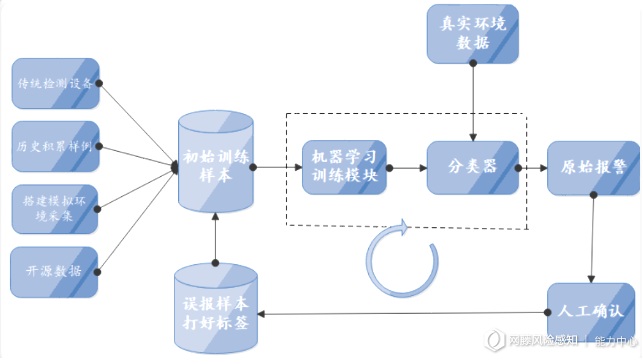
(图6)
4.2 技术选型
将基于机器学习的Webshell检测部署到生产环境中,需要考虑大数据规模对模型的时效性、吞吐量等性能指标的影响。经多方考量,最终选用如下图7所示的组件搭配作为产品化的技术选型。此方案结合了spark大数据处理的高效性,Kafka对数据流动的中高性能低延迟性,Hbase对对大规模数据集的实时读性访问性。采用下图中技术架构,可保证大流量环境中对Webshell的检测,和机器学习模型的自动优化。
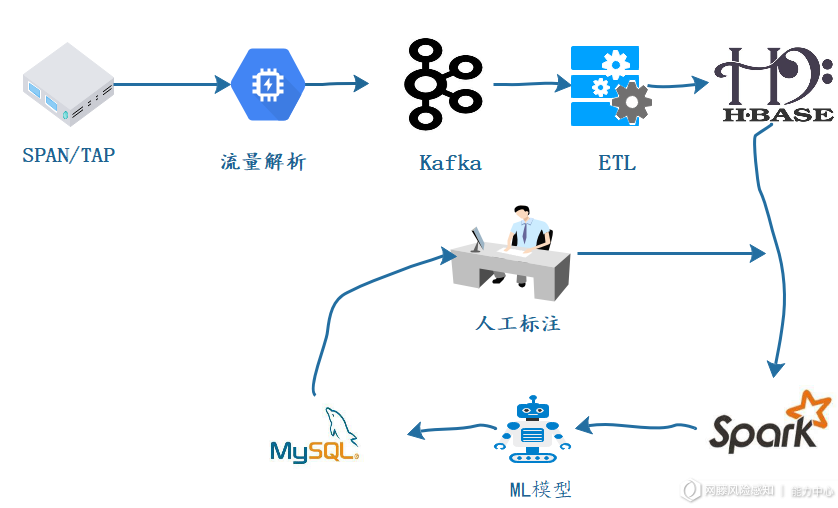
(图7)
五、总结
本文介绍了基于机器学习检测webshell的方法和落地实施中的一些技术组件选型。首先,基于机器学习的webshell检测重点是需要结合安全专家知识设计提取出高效的模型特征,只有较好的特征构建才能保证模型在真实环境中的检出效果。其次,对于机器学习模型训练阶段,数据一直是最重要的,而网络安全领域数据稀缺是普遍现象,我们在文中介绍了如何自动化构建webshell异常数据,保证模型的训练数据量。最后,通过对比验证了各算法的检测效果,并引入了人工审核确认流程保证在产品化阶段可以对模型定期优化,提高检测准确度。
在现有的样本中,采取以上提到的特征已经获得了比较优秀的准确度。但除了上述方法,仅依据一条流量做特征提取并进行结果预测,难免存在误报情况。因此我们除了对单一一条流量信息特征进行检测,另外引入了需要一定量的数据积累统计后才能体现的特征,以下先罗列部分:
● 对单个网页的访问频率;
● 单个访问网页User-agent的差异性;
● 单个网页在整个网页图结构中的出入度统计;
● 单个网页结构与整体网页结构的相似度对比;
这些特征能从另一个视角体现webshell的特征,但是对于单条数据并不能很好地体现。因此需要一定量和一定时间段的积累流量进行统计分析。基于阶段统计信息融入到wehshell检测模型特征中,进行联合分析,将会在下篇中我们会具体讲解如何使用上述的几个特征,从样本采集、工程设计、特征工程、模型训练等几个方面具体阐述。敬请期待。也期待与大家进行技术交流。
TCC team长期招聘,包含各细分领域安全研究、机器学习、数据分析、大数据研发、安全研发等职位。感兴趣不妨联系我们,email: [email protected]。
来源:freebuf.com 2018-08-16 16:24:24 by: 斗象智能安全平台