前言
笔者的基友们参加了第二届“强网杯”,并且拿到了总决赛的入场券。受他们的影响,笔者也开始关注并学习CTF的相关知识。
搜罗了一下网上关于CTF入门的相关资料,大家都说从取证题开始入手比较合适,因为简单又有趣。“听人劝,吃饱饭”,就从取证题开始学起吧!
0x01 Forensics?MISC?
笔者查阅了国内外近几年的CTF比赛,发现国内比赛使用“MISC”较多,并且将Forenics包含在了MISC里面;而国外则使用“Forensics”较多。目前,电子取证已经形成了一门单独的计算机学科(https://en.wikipedia.org/wiki/Computer_forensics)。
0x02电子取证的概念
笔者在翻阅的资料的过程中(包括高校教材),发现业内对“电子取证”这一概念并没有一个统一的定义,也许是因为计算机技术的更替太快的原因吧。
目前较为广泛的认识是:电子数据取证是指能够为法庭接受的、足够可靠和有说服力的、存在于计算机和相关外设中的电子证据的确定、收集、保护、分析、归档以及法庭出示的过程。
0x03 电子取证证据的来源及分类
电子取证证据主要有如下三个来源:
1. 计算机主机系统
计算机主机系统就是我们通常所说的台式机电脑、笔记本电脑、平板电脑等。
2. 计算机网络
这里说的网络主要是网络流量包。
3.其它数字设备
移动硬盘、MP3、U盘等具有存取数据功能的设备。
电子取证证据的分类主要有如下四种:
以证据来源为标准:主机取证、网络取证和其它相关设备取证
主机取证:对计算机中具有数据存储功能的设备的取证,如硬盘、内存、BIOS等。
网络取证:对网络数据流量包中的内容进行取证。
其它相关设备取证:对移动存储设备或其它具有数据存储功能的设备的取证。
以信息获取时潜在证据的特征为标准:静态信息取证和动态信息取证
静态信息取证:静态主要是指获取存储在硬盘、光盘等设备中的数据。当设备被断电后,数据依然存在。
动态信息取证:动态获取是指收集电源被切断后会消息的数据,如操作系统的进程、计算机内存数据、网络数据包等。
以信息获取的时间为标准:事前信息取证和事后信息取证
事前是指事件正在发生,比如对网络流量包的取证,对数据包一边捕获,一边分析,取证难度相对较大。事前取证通常指对动态信息的取证,
事后是指事件已经发生,且信息被存储在硬盘、光盘等设备上。事后取通常是指对静态信息的取证,
以调查人员是否需要到现场为标准:现场取证和远程取证
0x04了解文件头
CTF的赛题通常没有扩展名,需要选手自行判断文件类型。有以下两种方法可以识别文件:1.使用支持16进制的文本工具查看文件头;2.使用已有的文件识别工具。
文件识别工具的原理实质上还是从文件头、尾来判断,所以需要先学习一下文件头的相关知识。
文件头:文件头是位于文件开头的一段承担一定任务的数据。有了文件头,操作系统就可以识别这个文件,并用不同的程序来打开这个文件。
用PNG文件举个例子:
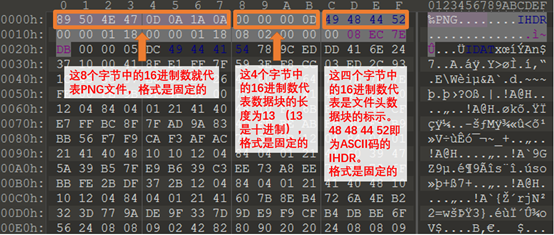
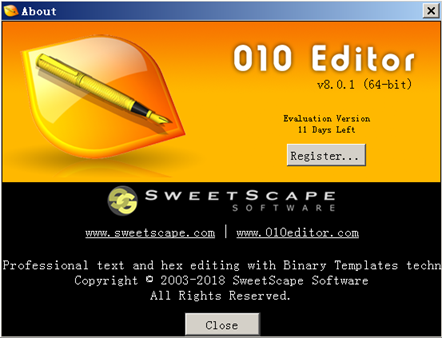
(固定)八个字节89 50 4E 47 0D 0A 1A 0A为png的文件头
(固定)四个字节00 00 00 0D(即为十进制的13)代表数据块的长度为13
(固定)四个字节49 48 44 52(即为ASCII码的IHDR)是文件头数据块的标示(IDCH)
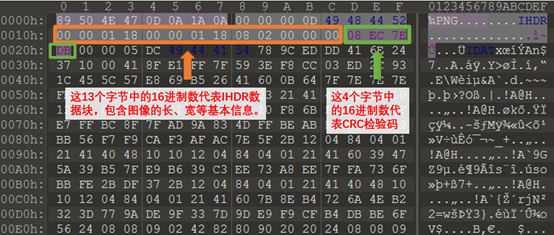
(可变)13位数据块(IHDR)
(可变)剩余四字节为该PNG的CRC检验码,由从IDCH到IHDR的十七位字节进行CRC计算得到
文件尾:标示整个文件数据的数据结尾。
有些文件尾不是必须有的,比如图像文件
有些文件尾是必须有,且不可随意更改的,比如压缩文件
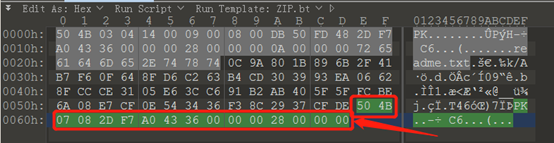
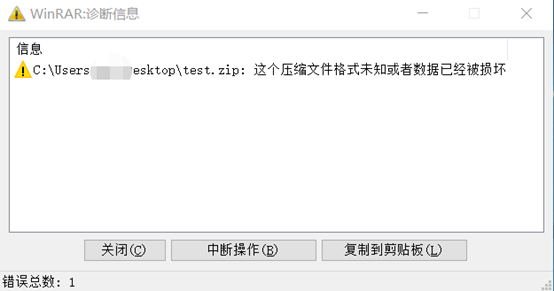
上图绿色的部分即为ZIP格式的压缩文件的文件尾,如果更改了其中的值,可能会造成压缩文件无法正常解压,如下图就是文件尾被破坏后,解压软件提示的出错信息。
0x05 查看文件头的软件。
通常我们都是用十六进制编辑器来查看文件头。
Windows系统
有诸如WinHex、010Editor等大量十六进制编辑器,笔者比较偏爱010editor,它可以将文件中的不同含义的数据块用不同的颜色标示出来,一目了然。
Linux系统
hexeditor,全键盘操作,不适合对习惯使用鼠标操作的人。
Hexdump命令

用这个命令得到结果与在编辑器里看到的数据不一样,个人认为不太好用。
0x06 用工具识别文件格式
除了用查看文件头的方式识别外,还有很多工具可以帮助我们更快、更直接的识别未知文件。
Linux系统中,常用 file命令判断文件类型。使用方法很简单,
file 要识别的文件名

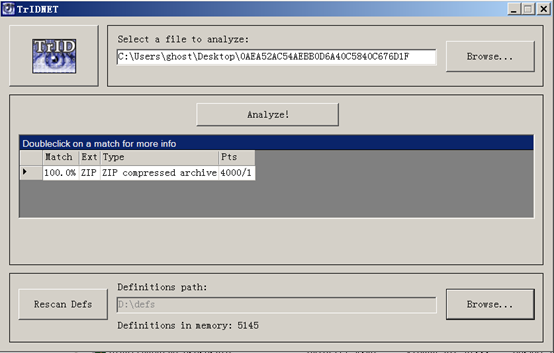
Windows系统中,推荐使用TrID,这个工具能识别近万种文件格式。有DOS版(TrID_dos),和视窗版(TrIDNet)。TrIDNet使用起来相当简单,导入要分析的文件路径后,点击分析按钮即可看到分析结果。
需要注意的是,必需下载官方的字典(一个名为triddefs的压缩包),并在软件中将其导入,才能使用完整功能。
0x07 用Python写个文件识别脚本
现有的文件识别工具的原理就是提取文件头部的部分字节,然后与字典进行对比,并输出对比结果。
Python有一个filetype库,用filetype的官方文档中的示例即可实现识别功能,不过能识别的文件格式较少。
为了锻炼锻炼编程能力,还是尝试自己写一个简单的实现代码吧。Python3实现:
import struct
import binascii
fTD = {
'FFD8FFE1':'JPEG',
'89504e47':'PNG',
'47494638':'GIF',
'49492A00':'TIFF'
}
openfile = open("8", "r+b")
data = openfile.read(4)
ascii2bin = binascii.hexlify(data)
ascii2bin = ascii2bin.decode('ascii')
if ascii2bin in fTD:
print(fTD[ascii2bin])
else:
print('Unknown')
openfile.close()
来源:freebuf.com 2018-05-07 01:43:45 by: DigApis