0x01 概要
之前的糖果实验室介绍了一般网站的系统的服务器及网络部署的结构,也介绍了大数据平台上的数的流向流程 。我们从整体上对生产环境的情况的有一个俯瞰的视野了解,接下来我们要具体的介绍日志处理的落地方法,用一个看得见的具体例子,来说明的网站的日志是如何收集到大数据系统里的,又如何在大数据系统间交换数据。
我们以之前的介绍的系统结构为蓝本, 构建一个靶机系统,部署一个开源的WAF系统:NAXSI。我们通过这个简单的实例,看如何从一个典型的网站服务器应用上取得日志数据,及如何推送到日志到Kafaka上,写到Clickhouse里,和我们是通过什么工具读取的到ClickHouse中的数据的。
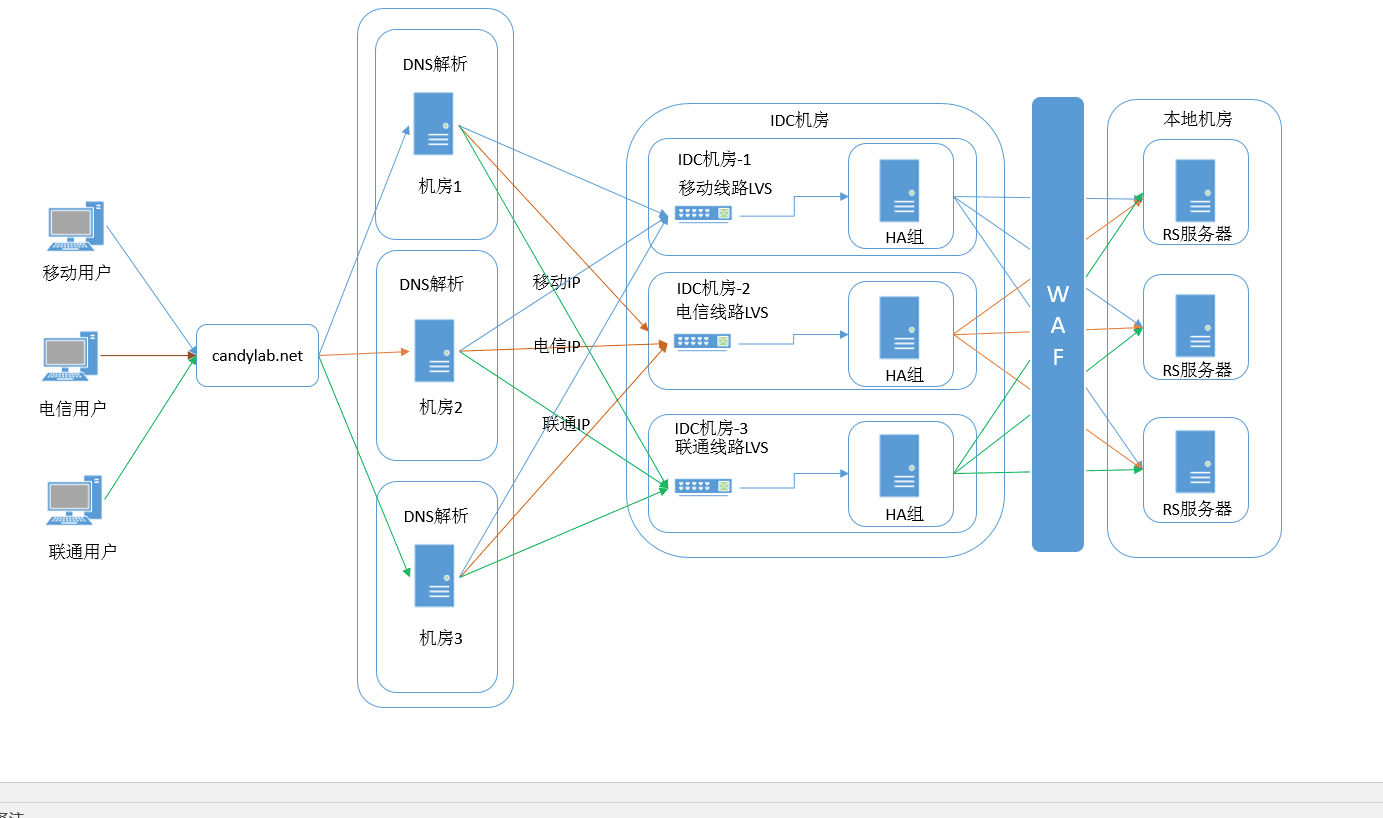
Naxsi是一个软WAF,实际上是一个Nginx的C扩展,这不同于其他基于Nginx系统LUA的开源WAF,Naxsi给Nginx创建了新的关键字,用于安全人员来构建安全策略,下图是之前我们介绍的一般网站系统的结构图。
0x02 安装Openresty
Naxsi是一个Nginx的的扩展模块,实际上我们安装使用Openresty达到的效果是等价的,并且我们在使用Openresty的同时,还可以使用Openresty的相关各种生态工具。之前糖果实验室介绍的开源WAF是春哥团队自主研发的系统,也不是基于纯LUA的WAF,是一种全新的基于小语言的WAF系统。之前糖果实验室也发过相关的文章,如果大家有兴趣,可以翻看之前写的文章。
https://openresty.org/download/openresty-1.xx.x.x.tar.gz
yum install -y gcc gcc-c++ readline-devel pcre-devel openssl-devel tcl perl
tar -zxvf openresty-1.xx.x.x.tar.gz
cd /openresty-1.xx.x.x
./configure
make
make install
0x03 部署Naxsi(WAF)
Naxsi是作为Nginx的一个模块存在的,经过实验基于Openresty编译安装naxsi也可以达到同样的效果, 在安装时需要安装相关的依赖,为了减去麻烦,直接运行bootstrap安装是最方便的,减少了手动安装依赖软件的过程。
其实开源社区里还有一个比较有名的WAF就是mode security,mod security的社区对安全规则支持是很好的,我们选择用Naxsi做实验,还是考虑他和Nginx本身作为一个整体存在的,而且我们可以对C模块进行修改定制,并且还可在些基础上加入Lua模块,通过Lua和C一起,这样以来就丰富了我们的开发工具链。
wget https://github.com/nbs-system/naxsi/archive/0.56rc1.tar.gz
tar -zxvf naxsi-0.56rc1.tar.gz
cd 0.56rc1
./configure –user=www –group=www –prefix=/usr/local/openresty –with-luajit –with-http_stub_status_module –with-http_ssl_module –with-http_sub_module –with-http_realip_module –add-module=/usr/home/candylab/naxsi-0.56rc1/naxsi_src
gmakegmake install
0x04 Naxsi的配置WAF
因数Naxsi是C写的,在Nginx的配置文件里,有naxsi的关键字。如果命中的策略就返回412, 如果没有命中就将请求推给上游。实际上,Naxsi是支持变量累计的。Naxsi有一个最核心的策略代码:https://github.com/nbs-system/naxsi/blob/master/naxsi_config/naxsi_core.rules
Naxsi除了WAF本身还有其它工具链支持,因为这次主要介绍的是日志推送,不展开其它部分的说明。
http {
include mime.types;
default_type application/octet-stream;
MainRule id:1001 “str:liwq” “msg: test candylab” “mz:$HEADERS_VAR:Cookie” “s:$SQL:2”;
MainRule id:1002 “str:0x” “msg:0x, possible hex encoding” “mz:BODY|URL|ARGS|$HEADERS_VAR:Cookie” “s:$SQL:2”;
server {
listen 8080;
server_name localhost;
location / {
SecRulesEnabled;
DeniedUrl “/RequestDenied”;
CheckRule “$SQL >= 4” BLOCK;
proxy_pass http://www.candylab.net/;
}
location /RequestDenied {
return 412;
}
}
}
通过curl触发策略,发出一个请求:
curl -v ‘127.0.0.1:8080/’ -H’cookie: candylab’ -H’cookie: 0x’
0x05 Nginx输出JSON日志
nginx一般产生的日志文件的格式都是文本形式的,后期Nginx加入了生成JSON的支持功能,这样我们直接把nginx的日志生成JSON推到Kakka上,然后Kafka消费者程序把日志数据写到ClickHouse里。
首先,是定义日志格式:
log_format accessjson escape=json ‘{“source”:”192.168.0.6″, “ip”:”$remote_addr”,”user”:”$remote_user”,”time_local”:”$time_local”,”statuscode”:$status,”bytes_sent”:$bytes_sent,”http_referer”:”$http_referer”,”http_user_agent”:”$http_user_agent”,”request_uri”:”$request_uri”,”request_time”:$request_time,”gzip_ration”:”$gzip_ratio”,”query_string”:”$query_string”}’;
其次,是引用格式:
access_log ./logs/access-json.log accessjson;
完整一些的配置例子。
http {
include mime.types;
default_type application/octet-stream;
log_format accessjson escape=json ‘{“source”:”192.168.0.6″,”ip”:”$remote_addr”,”user”:”$remote_user”,”time_local”:”$time_local”,”statuscode”:$status,”bytes_sent”:$bytes_sent,”http_referer”:”$http_referer”,”http_user_agent”:”$http_user_agent”,”request_uri”:”$request_uri”,”request_time”:$request_time,”gzip_ration”:”$gzip_ratio”,”query_string”:”$query_string”}’;
MainRule id:1001 “str:liwq” “msg: test candylab” “mz:$HEADERS_VAR:Cookie” “s:$SQL:2”;
MainRule id:1002 “str:0x” “msg:0x, possible hex encoding” “mz:BODY|URL|ARGS|$HEADERS_VAR:Cookie” “s:$SQL:2”;
server {
listen 8080;
server_name localhost;
access_log ./logs/access-json.log accessjson;
location / {
SecRulesEnabled;
DeniedUrl “/RequestDenied”;
CheckRule “$SQL >= 4” BLOCK;
proxy_pass http://www.candylab.net/;
}
location /RequestDenied {
return 412;
}
}
}
如此之后,Openresty再生成日志,就会生成JSON格式的日志文件,这里要注意的一点是,“escape=json” 这个关键字一定要加上,只有加上这句,日志生成的过程中一些特殊的日志字符才会被转义。
在没有使用Kakfa接收数据时,以前的方案是让openresty直接推送日志的到syslog服务器,再由监听程序写入到ES里,这种方试的日志收集也比较好设置:
access_log syslog:server=192.168.0.6:10001;
这样设置就可将nginx日志推送到sysog服务器上。
0x06 日志推送Kafka

之前我们有一遍专门写了收集的流程同,如上图。Openresty本身是有kafka部件的,将数据推送到kafka上,而kafkacat是一个独立的工具,可以直接将文本文件通tail命令转给kafkacat,由kafkacat转到kafaka上。
安装kafkacat,直接到github上下载工具即可。
wget https://github.com/edenhill/kafkacat/archive/1.3.1.tar.gz
cd kafkacat
./configure
make
sudo make install
命名用bootstrap,让依赖包的问题更好解决。
./bootstrap.sh
sudo make install
关键的部分是如何把本地的JSON文本文件推送到kafka上,下面一句就可以了。
tail -F -q access-json.log | kafkacat -b 1.kafka1.candylab.net:9091,2.kafka1.candylab.net:9091,3.kafka1.candylab.net:9091,4.kafka1.candylab.net:9091 -t candylab_topic
kafkacat使用简单而且效率也不错。
0x07 clickhouse-client的安装

关于ClickHouse是如何收集日志的,之前也有介绍如上图。当日志被kafka消费程序推送到clickhouse上,我们就可以通过clickhouse-client客户端,像使用mysql程序一样,进行SQL查询了。clickhouse-client在这个实验中,使用的是docker的方式存在,并运行的。
docker run –it —rm yandex/clickhouse–client –h candylab.net —port 9006 –m –u candylab —password nicaishisha –d candylab
执行以上代码后,docker就会下载clickhouse-client镜像,并运行程序,当出现新的提示符时,我们就可以用SQL查询了。
0x08 总结
之前糖果实验室发布的都是说系统的整体结构,而这篇我们主要重点说的是,这个系统如何通过各种程序运行在现实世界里的,我们分别针对前几篇文章中关键图,给出了具体的实施方案,这些工具基本上都是开源免费的,只要按文章介绍,实施难度不大,后续糖果实验室会继续介绍,如何使用这套开源构建的低成本系统,来解决实际的日志分析问题。
来源:freebuf.com 2018-03-22 17:16:45 by: 糖果L5Q