做文本挖掘相关任务时,第一步要做文本的预处理就是分词,英文单词由于本身已空格隔开,故按照空格分词,但是因需求而定,如‘New York’需要被看做是一个词,中文由于没有空格,因此需要有专门的分词工具去解决,本文将对分词原理做一个详细介绍。
分词基本原理
现代分词大多数都是基于统计的方法,统计的样本内容都是来自于一些标准语料库,如人民日报的语料,假如有一个句子“南京市长江大桥”我们可能得到有几种分词方式,如
“南京市/长江大桥/在/上个世纪/修建”
“南京/市长/江大桥/在/上个世纪/修建”
显然第一种分词方式的概率要比第二种分词的概率大,那是如何得到这样的选择呢?,以下就开始介绍语言模型
什么是语言模型呢?所谓语言模型,简单明了:它是用来计算一个句子的概率模型,也就是判断一句话是否是人话的概率?,那有人就会问,这个和分词原理有什么关系呢?别急,让我娓娓道来
假设有一个句子S,它有m种分词方式选项如下:
![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924040.png)
那么分词最终要做的事情就是使得其中一种分词的概率最大(相当于分词之后组合得到的概率最大,这个就和语言模型的思想不谋而和了)
![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924041.png)
由于涉及到 ![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924042.png) 个分词的联合分布,并不好直接求出来,因此语言模型出来放大招了,令
个分词的联合分布,并不好直接求出来,因此语言模型出来放大招了,令
![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924043.png)
它的概率可以表示为:
![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924044.png)
可是这样的方法有两个问题:
1:某些生僻词,或者相邻分词联合分布在语料库没有,这样就会出现概率为0,这时候通常需要采用拉普拉斯平滑
2:参数维度过多:条件概率可能性太多,无法有效计算。
因此为了解决这种问题,我们引入马尔科夫假设。
马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
一元语言模型:
如果一个词的出现与周围词无关,也就是它是独立的,那称这种模型为一元语言模型(unigram)
![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924045.png)
在这里,这个式子成立的条件是有一个假设,就是条件无关假设,我们认为每个词都是条件无关的。
例如:
P(南京市/长江大桥/在/上个世纪/修建)=P(南京市)*P(长江大桥)*P(在)*P(上个世纪)*P(修建)
P(南京/市长/江大桥/在/上个世纪/修建) = P(南京)*P(市长)*P(江大桥)*P(在)*P(上个世纪)*P(修建)
根据在语料库中对应词出现的概率相乘即可得到上面的概率结果
二元语言模型:
如果一个词的出现依赖于前面一个词,那称这种模型为二元语言模型(bigram)
![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924046.png)
例如:
P(南京市/长江大桥/在/上个世纪/修建)=P(^|南京市)*P(南京市|长江大桥)*P(长江大桥|在)*P(在|上个世纪)*P(上个世纪|修建)
P(南京/市长/江大桥/在/上个世纪/修建)=P(^|南京)*P(南京|市长)*P(江大桥|在)*P(在|上个世纪)*P(上个世纪|修建)
N元语言模型:
以此类推,如果一个词的出现依赖于前面N-1个词,那称这种模型为N元语言模型(N-gram)在实践中用的最多的就是二元语言模型和三元语言模型,高于三元用的非常少,因为这样导致计算效率很低,时间复杂度高,精度提升很有限。
在NLP中,通常我们用到齐次马尔科夫假设,即每一个分词出现的概率只与前面一个分词相关,与其他分词无关。
因此: ![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924047.png)
可以改写为: ![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924048.png)
通过我们标准语料库,可以计算所有分词的二元条件概率:
![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/924049.png)
其中 ![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/9240410.png) 表示
表示 ![[公式]](http://aqxbk.com/wp-content/uploads/2021/12/9240411.png) 在语料库中相邻一起出现的频数,因此通过以上方法我们即可求出各种分词组合的联合分布概率,找到最大概率对应的分词即为最优分词。
在语料库中相邻一起出现的频数,因此通过以上方法我们即可求出各种分词组合的联合分布概率,找到最大概率对应的分词即为最优分词。
接下来我们介绍一下Viterbi算法,这个算法的功力可算是上乘功夫,听我给你娓娓道来
Verterbi算法与分词
这里我不详细介绍Verterbi算法原理了,若需要了解,可自行去百度或者Google,先说下Verterbi算法是用来干嘛的,说白了它是用来解决动态规划最优化问题的:基于局部最优寻找全局最优,是一种动态规划最大概率寻找法,首先我们来看下它在NLP中的应用,例如:“人生如梦境”。它的分词可能情况如下图:
")
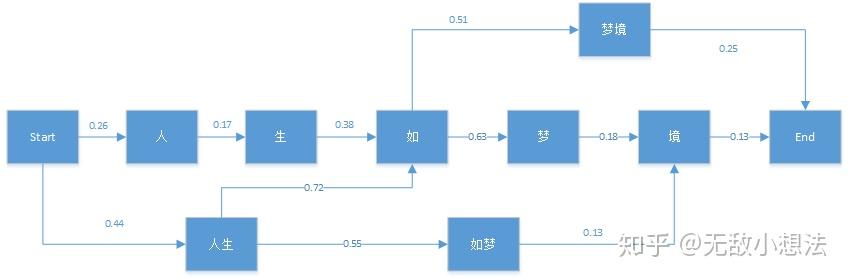
图中的箭头为通过统计语料库而得到的对应的各分词位置BEMS(开始位置,结束位置,中间位置,单词)的条件概率。比如P(生|人)=0.17。有了这个图,维特比算法需要找到从Start到End之间的一条最短路径。对于在End之前的任意一个当前局部节点,我们需要得到到达该节点的最大概率δ,和记录到达当前节点满足最大概率的前一节点位置Ψ。
我们先用这个例子来观察Verterbi算法的过程,首先我们初始化有:
δ(人) = 0.26*Ψ(人) = Start*δ(人生)=0.44 *Ψ(人生) = Start
对于节点“生”,它只有一个前向节点,因此有:
δ(生) =δ(人)P(生|人) =0.0442*Ψ(生) =人
对于节点“如”,就稍微有一点复杂,因为它有很多前向节点,我们要计算出到“如”的概率最大的路径:
δ(如)=max{δ(生)P(如|生),δ(人生)P(如|人生)} = max{0.01680,0.3168} = 0.3168*Ψ(如) = 人生
类似的方法可以用于其他节点如下:
δ(如梦)=δ(人生)P(如梦|人生)=0.242Ψ(如梦) = 人生
δ(梦)=δ(如)P(梦|如)=0.1996Ψ(梦) = 如
δ(境)=max{δ(梦)P(境|梦),δ(如梦)P(境|如梦)} = max{0.0359,0.0315} = 0.0359*Ψ(境) =梦
δ(梦境)=δ(如)P(梦境|如)=0.1585Ψ(梦境) = 如
最后我们看看最终节点End:
δ(End)=max{δ(梦境)P(End|梦境),δ(境)P(End|境)} = max{0.0396,0.0047} = 0.0396*Ψ(End) =梦境
由于最后的最优解为“梦境”,现在我们开始从后反推,将其串起来。
Ψ(End)=梦境——>Ψ(梦境)=如——>Ψ(如)=人生——>Ψ(人生)=start
最终得到的分词结果为“人生/如/梦境”,是不是很神奇!!!,至此中文分词原理已经介绍完了,接下来我们开始讲解常见的分词工具,未完待续!!!