在freebuf上莫名地被喷,可能是因为被喷让人气上来了,最后得到的金币比前一篇文章更多。塞翁失马,焉知非福?
尽管现在呼吁所有的程序都使用unicode编码,所有的网站都使用utf-8编码,来一个统一的国际规范。但仍然有很多,包括国内及国外(特别是非英语国家)的一些cms,仍然使用着自己国家的一套编码,比如gbk,作为自己默认的编码类型。也有一些cms为了考虑老用户,所以出了gbk和utf-8两个版本。
我们就以gbk字符编码为示范,拉开帷幕。gbk是一种多字符编码,具体定义自行百度。但有一个地方尤其要注意:
通常来说,一个gbk编码汉字,占用2个字节。一个utf-8编码的汉字,占用3个字节。在php中,我们可以通过输出
echo strlen("和");来测试。当将页面编码保存为gbk时输出2,utf-8时输出3。
除了gbk以外,所有ANSI编码都是2个字节。ansi只是一个标准,在不用的电脑上它代表的编码可能不相同,比如简体中文系统中ANSI就代表是GBK。
以上是一点关于多字节编码的小知识,只有我们足够了解它的组成及特性以后,才能更好地去分析它身上存在的问题。
说了这么多废话,现在来研究一下在SQL注入中,字符编码带来的各种问题。
0×01 MYSQL中的宽字符注入
这是一个老话题了,也被人玩过无数遍。但作为我们这篇文章的序幕,也是基础,是必须要提的。
我们先搭建一个实验环境。暂且称之为phithon内容管理系统v1.0,首先先新建一个数据库,把如下压缩包中的sql文件导入:
测试代码及数据库:http://pan.baidu.com/s/1eQmUArw 提取密码:75tu
之后的phithon内容管理系统会逐步完善,但会一直使用这个数据表。
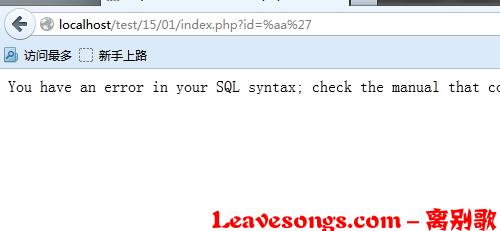
源码很简单(注意先关闭自己php环境的magic_quotes_gpc):
<?php
//连接数据库部分,注意使用了gbk编码,把数据库信息填写进去
$conn = mysql_connect('localhost', 'root', 'toor!@#$') or die('bad!');
mysql_query("SET NAMES 'gbk'");
mysql_select_db('test', $conn) OR emMsg("连接数据库失败,未找到您填写的数据库");
//执行sql语句
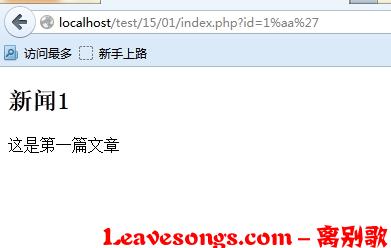
$id = isset($_GET['id']) ? addslashes($_GET['id']) : 1;
$sql = "SELECT * FROM news WHERE tid='{$id}'";
$result = mysql_query($sql, $conn) or die(mysql_error()); //sql出错会报错,方便观察
?>
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>新闻</title>
</head>
<body>
<?php
$row = mysql_fetch_array($result, MYSQL_ASSOC);
echo "<h2>{$row['title']}</h2><p>{$row['content']}<p>n";
mysql_free_result($result);
?>
</body>
</html>SQL语句是SELECT * FROM news WHERE tid='{$id}',就是根据文章的id把文章从news表中取出来。
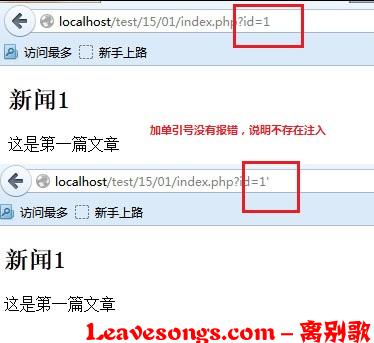
在这个sql语句前面,我们使用了一个addslashes函数,将$id的值转义。这是通常cms中对sql注入进行的操作,只要我们的输入参数在单引号中,就逃逸不出单引号的限制,无法注入,如下图:
那么怎么逃过addslashes的限制?众所周知addslashes函数产生的效果就是,让'变成',让引号变得不再是“单引号”,只是一撇而已。一般绕过方式就是,想办法处理'前面的:
1.想办法给前面再加一个(或单数个即可),变成\',这样被转义了,'逃出了限制
2.想办法把弄没有。
我们这里的宽字节注入是利用mysql的一个特性,mysql在使用GBK编码的时候,会认为两个字符是一个汉字(前一个ascii码要大于128,才到汉字的范围)。如果我们输入%df'看会怎样:

我们可以看到,已经报错了。我们看到报错,说明sql语句出错,看到出错说明可以注入了。
为什么从刚才到现在,只是在'也就是%27前面加了一个%df就报错了?而且从图中可以看到,报错的原因就是多了一个单引号,而单引号前面的反斜杠不见了。
这就是mysql的特性,因为gbk是多字节编码,他认为两个字节代表一个汉字,所以%df和后面的也就是%5c变成了一个汉字“運”,而'逃逸了出来。
因为两个字节代表一个汉字,所以我们可以试试%df%df%27:
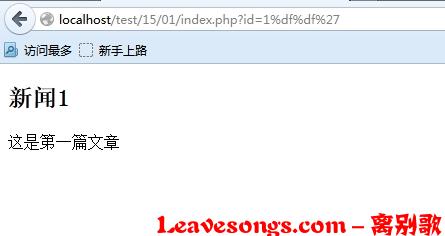
不报错了。因为%df%df是一个汉字,%5c%27不是汉字,仍然是'。
那么mysql怎么判断一个字符是不是汉字,根据gbk编码,第一个字节ascii码大于128,基本上就可以了。比如我们不用%df,用%a1也可以:
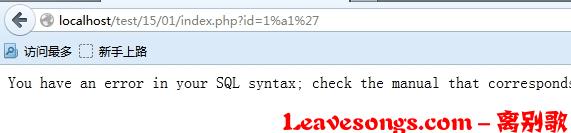
%a1%5c他可能不是汉字,但一定会被mysql认为是一个宽字符,就能够让后面的%27逃逸了出来。
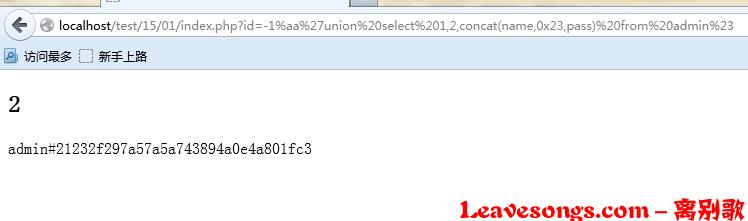
于是我可以构造一个exp出来,查询管理员账号密码:
0×02 GB2312与GBK的不同
曾经有一个问题一直困扰我很久。
gb2312和gbk应该都是宽字节家族的一员。但我们来做个小实验。把phithon内容管理系统中set names修改成gb2312:
结果就是不能注入了:
有些同学不信的话,也可以把数据库编码也改成gb2312,也是不成功的。
为什么,这归结于gb2312编码的取值范围。它的高位范围是0xA1~0xF7,低位范围是0xA1~0xFE,而是0x5c,是不在低位范围中的。所以,0x5c根本不是gb2312中的编码,所以自然也是不会被吃掉的。
所以,把这个思路扩展到世界上所有多字节编码,我们可以这样认为:只要低位的范围中含有0x5c的编码,就可以进行宽字符注入。
0×03 mysql_real_escape_string解决问题?
部分cms对宽字节注入有所了解,于是寻求解决方案。在php文档中,大家会发现一个函数,mysql_real_escape_string,文档里说了,考虑到连接的当前字符集。

于是,有的cms就把addslashes替换成mysql_real_escape_string,来抵御宽字符注入。我们继续做试验,phithon内容管理系统v1.2:,就用mysql_real_escape_string来过滤输入:
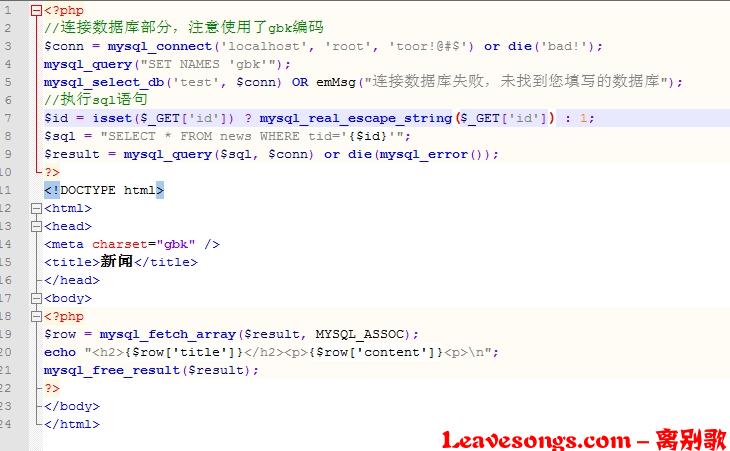
我们来试试能不能注入:

一样没压力注入。为什么,明明我用了mysql_real_escape_string,但却仍然不能抵御宽字符注入。
原因就是,你没有指定php连接mysql的字符集。我们需要在执行sql语句之前调用一下mysql_set_charset函数,设置当前连接的字符集为gbk。
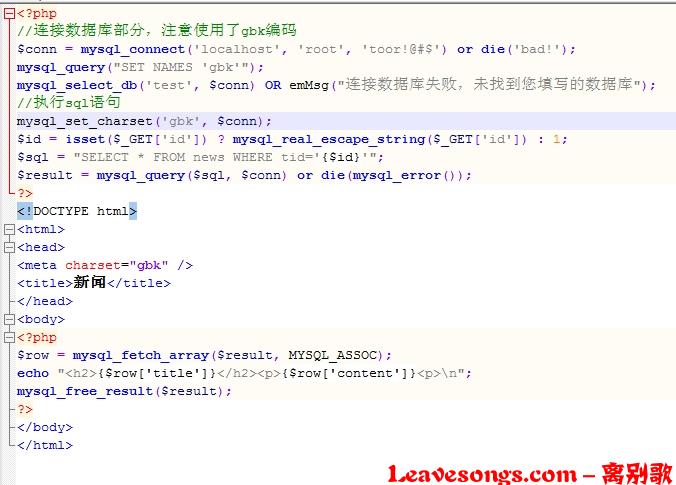
就可以避免这个问题了:
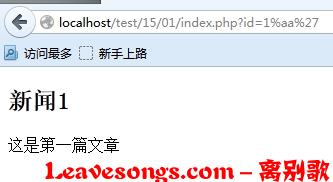
0×04 宽字符注入的修复
在3中我们说到了一种修复方法,就是先调用mysql_set_charset函数设置连接所使用的字符集为gbk,再调用mysql_real_escape_string来过滤用户输入。
这个方式是可行的,但有部分老的cms,在多处使用addslashes来过滤字符串,我们不可能去一个一个把addslashes都修改成mysql_real_escape_string。我们第二个解决方案就是,将character_set_client设置为binary(二进制)。
只需在所有sql语句前指定一下连接的形式是二进制:
SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary这几个变量是什么意思?
当我们的mysql接受到客户端的数据后,会认为他的编码是character_set_client,然后会将之将换成character_set_connection的编码,然后进入具体表和字段后,再转换成字段对应的编码。
然后,当查询结果产生后,会从表和字段的编码,转换成character_set_results编码,返回给客户端。
所以,我们将character_set_client设置成binary,就不存在宽字节或多字节的问题了,所有数据以二进制的形式传递,就能有效避免宽字符注入。
比如,我们的phithon内容管理系统v2.0版本更新如下:
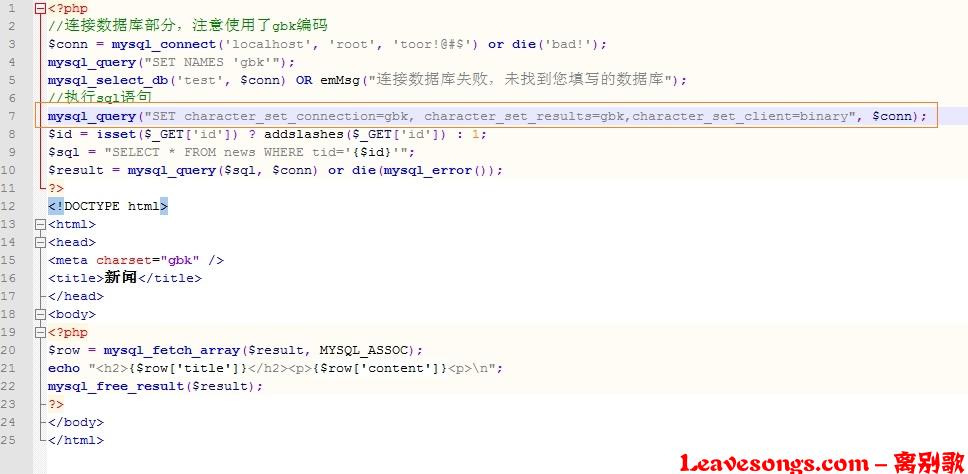
已经不能够注入了:
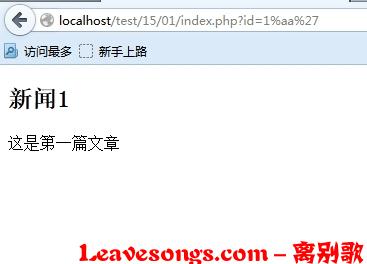
在我审计过的代码中,大部分cms是以这样的方式来避免宽字符注入的。这个方法可以说是有效的,但如果开发者画蛇添足地增加一些东西,会让之前的努力前功尽弃。
0×05 iconv导致的致命后果
很多cms,不止一个,我就不提名字了,他们的gbk版本都存在因为字符编码造成的注入。但有的同学说,自己测试了这些cms的宽字符注入,没有效果呢,难道是自己姿势不对?
当然不是。实际上,这一章说的已经不再是宽字符注入了,因为问题并不是出在mysql上,而是出在php中了。
很多cms(真的很多哦,不信大家自己网上找找)会将接收到数据,调用这样一个函数,转换其编码:
iconv('utf-8', 'gbk', $_GET['word']);目的一般是为了避免乱码,特别是在搜索框的位置。
比如我们的phithon内容管理系统v3.0
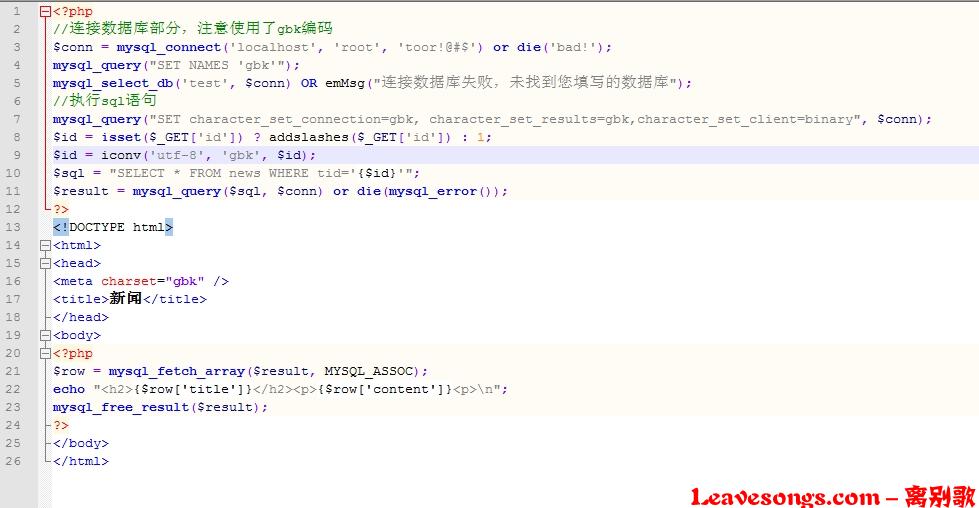
我们可以看到,它在sql语句执行前,将character_set_client设置成了binary,所以可以避免宽字符注入的问题。但之后其调用了iconv将已经过滤过的参数$id给转换了一下。
那我们来试试此时能不能注入:

居然报错了。说明可以注入。而我只是输入了一个錦'。这是什么原因?
我们来分析一下。“錦“这个字,它的utf-8编码是0xe98ca6,它的gbk编码是0xe55c。
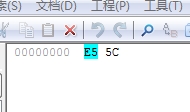
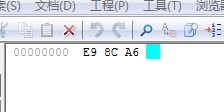
有的同学可能就领悟了。的ascii码正是5c。那么,当我们的錦被iconv从utf-8转换成gbk后,变成了%e5%5c,而后面的'被addslashes变成了%5c%27,这样组合起来就是%e5%5c%5c%27,两个%5c就是,正好把反斜杠转义了,导致’逃逸出单引号,产生注入。
这正利用了我之前说的,绕过addslashes的两种方式的第一种:将转义掉。
那么,如果我是用iconv将gbk转换成utf-8呢?
我们来试试:
果然又成功了。这次直接用宽字符注入的姿势来的,但实际上问题出在php而不是mysql。我们知道一个gbk汉字2字节,utf-8汉字3字节,如果我们把gbk转换成utf-8,则php会每两个字节一转换。所以,如果'前面的字符是奇数的话,势必会吞掉,'逃出限制。
那么为什么之前utf-8转换成gbk的时候,没有使用这个姿势?
这跟utf-8的规则有关,UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。从2我们可以看到,对于多字节的符号,其第2、3、4字节的前两位都是10,也就是说,(0x0000005c)不会出现在utf-8编码中,所以utf-8转换成gbk时,如果有则php会报错:

但因为gbk编码中包含了,所以仍然可以利用,只是利用方式不同罢了。
总而言之,在我们处理了mysql的宽字符注入以后,也别认为就可以高枕无忧了。调用iconv时千万要小心,避免出现不必要的麻烦。
0×06 总结
在逐渐国际化的今天,推行utf-8编码是大趋势。如果就安全性来说的话,我也觉得使用utf-8编码能够避免很多多字节造成的问题。
不光是gbk,我只是习惯性地把gbk作为一个典型的例子在文中与大家说明。世界上的多字节编码有很多,特别是韩国、日本及一些非英语国家的cms,都可能存在由字符编码造成的安全问题,大家应该有扩展性的思维。
总结一下全文中提到的由字符编码引发的安全问题及其解决方案:
- gbk编码造成的宽字符注入问题,解决方法是设置character_set_client=binary。
- 矫正人们对于mysql_real_escape_string的误解,单独调用
set names gbk和mysql_real_escape_string是无法避免宽字符注入问题的。还得调用mysql_set_charset来设置一下字符集。 - 谨慎使用iconv来转换字符串编码,很容易出现问题。只要我们把前端html/js/css所有编码设置成gbk,mysql/php编码设置成gbk,就不会出现乱码问题。不用画蛇添足地去调用iconv转换编码,造成不必要的麻烦。
这篇文章是我对于自己白盒审计经验的一点小总结,但自己确实在很多方面存在欠缺,文中所提到的姿势难免存在纰漏和错误,希望有相同爱好的同学能与我指出,共同进步。
这篇文章不像上篇xss的,能够举出很多0day实例来论证宽字符造成的危害。原因有二:
- 宽字符问题确实不如富文本xss那么普遍,gbk编码的cms所占的比例也比较小,怪我才疏学浅,并不能每一章都找到相应的实例。
- 注入的危害比xss大得多,如果作为0day发出来,影响很坏。但我确实在写文章以及以前的审计过程中找到不少cms存在的编码问题。
所以我用实验的形式,自己写了的php小文件,给大家作为例子,希望不会因为例证的不足,影响大家学习的效果。
例子php文件和sql文件打包下载:
链接:http://pan.baidu.com/s/1eQmUArw 提取密码:75tu
本文PDF版本:链接: http://pan.baidu.com/s/1eprLs 密码: yoyw
一直想研究验证码的识别技术,这个晚上终于闲下来,来好好研究下python验证码的识别! 首先我们需要找一个能够支持识别图像文字的python库文件,这里我使用的是pytesser,还有一款叫pytesseract,其实原理大致相同,利用OCR的识别技术,将图像…