日站时经常会遇到在一顿骚操作拿到了管理员账号密码后却怎么也找不到网站后台的尴尬局面。这里总结一些查找后台的常用方法。
后台常见位置查找
猜解常用路径
Admin、admin_login.asp、admin_login.php部分网站默认都是admin目录后台。虽然开发人员安全意识逐渐完善,但还是有相当一部分网站管理员直接就用默认的路径。我们找后台时从常见的默认界面入手往往会有意外收获。
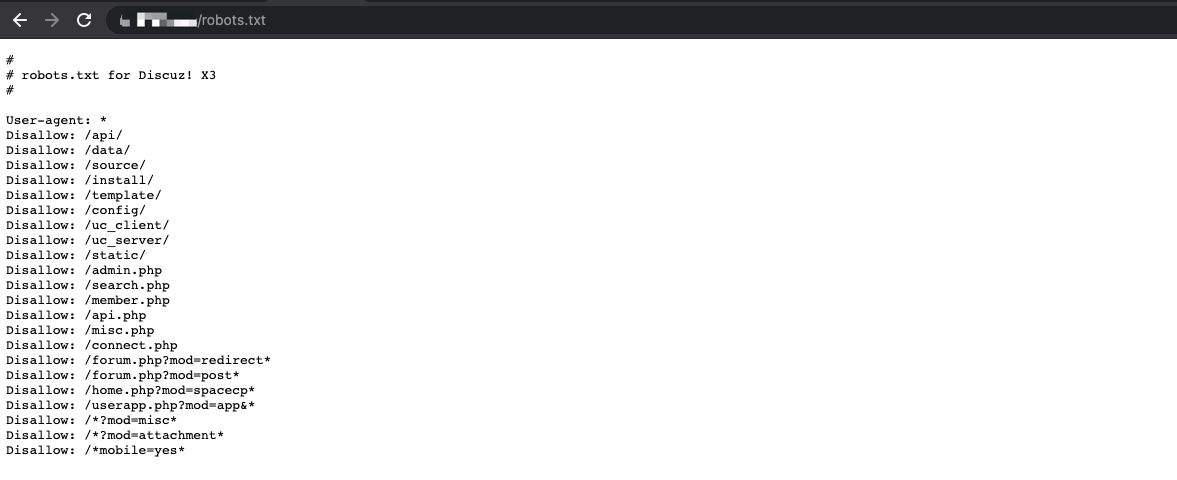
robots.txt
robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎,此网站中的哪些内容是不能被搜索引擎获取的,哪些是可以被获取的。管理员们为了让搜索引擎不要收录admin页面而在robots.txt里面做了限制规则。但是这个robots.txt页面,谁都可以看,于是我们就可以比较清楚的了解网站的结构,比如admin目录啊、include目录啊等等。
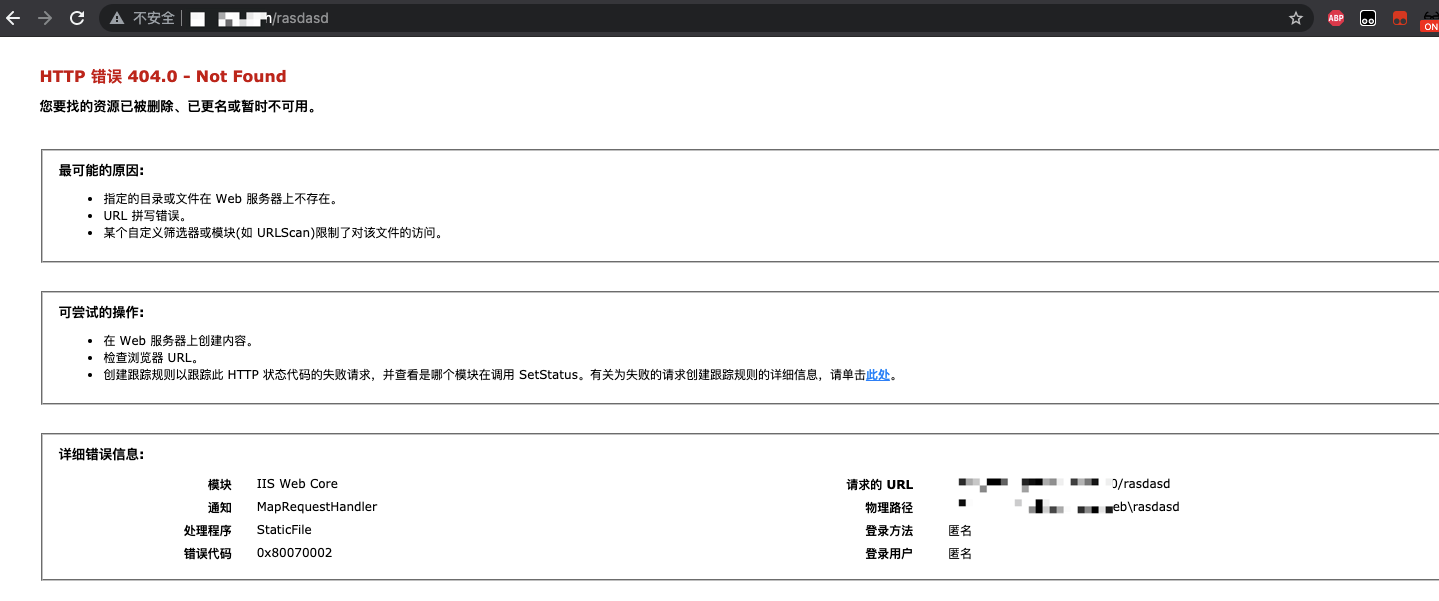
访问报错页面
当我们正常浏览网页找不到后台时可以尝试去请求一些网站不存在的页面,让网页显示报错信息有时也能看到网站的真实路径。
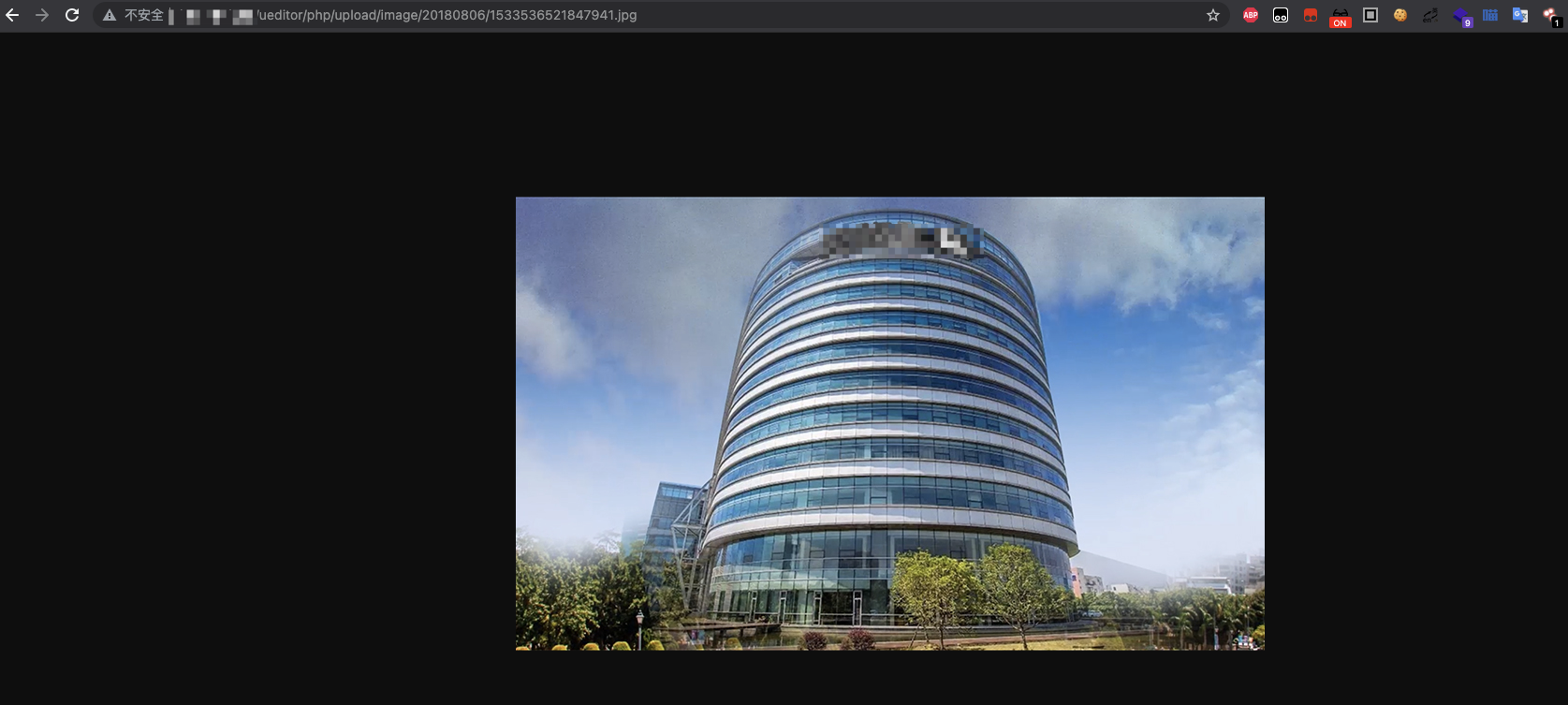
查看图片相关属性
当进入网站后,可以先随意点击下几张图片的属性,看看它们的文件路径是否可以加以利用。因为有些旧网站会直接把编辑器放在后台目录后面,所有当我们查看图片属性的时候会将网站路径上传点暴露出来。
CMS指纹识别
CMS的全程为”Content Management System”的,意为”内容管理系 统”。CMS只需要修改几个静态模版,就可以当成一个网站使用。可以利用在线CMS指纹识别、云悉识别等网站来进行CMS识别 。
比如像dede,后台就是/dede。除此以外,还有很多开源程序,如Joomla就是/administrator,wordpress就是/wp-admin。国内的CMS通常就是/admin和/manage,要么就是/login,这样命名后台主要还是管理员登陆起来比较方便。如果你知道了这是个什么CMS,但是却不知道他的后台登陆入口,也可以去官网或者一些下载站下载源码,看看都有哪些路径。
利用谷歌黑语法来查找
搜索也是一门艺术,在我们平时使用搜索引擎的过程中,通常是将需要搜索的关键字输入搜索引擎,然后就开始了漫长的信息提取过程。其实Google对于搜索的关键字提供了多种语法,合理使用这些语法,将使我们得到的搜索结果更加精确。当然,Google允许用户使用这些语法的目的是为了获得更加精确的结果,但是黑客却可以利用这些语法构造出特殊的关键字,从而搜索到我们想要的关键信息。
搜索网站后台地址
site:目标网站 intitle:管理/后台/登陆/管理员
site:目标网站 inurl:login/admin/guanlidenglu
site: 目标网站 intext: 管理/后台/登陆/管理员
搜索网站敏感信息
intitle:”Index of” .sh_history intitle:”index of” etc/shadow intitle:”index of” spwd
搜索网站特定文件
site:目标网站 filetype:doc
site:目标网站 filetype:xls
site:目标网站 filetype:pdf
利用工具查找
爬虫扫描
利用AWVS、BurpSuite自带的爬虫功能访问网站首页从而获取网站的敏感文件敏感目录等信息。爬取网站目录原理可以这样理解:我们在首页A中存在爬取A的所有 URL链接B,C,D……接着继 续爬取B ,C, D网页中的URL链接,层层递进,直到将所有URL链接爬取完成。之后便能看到我们需要的信息。
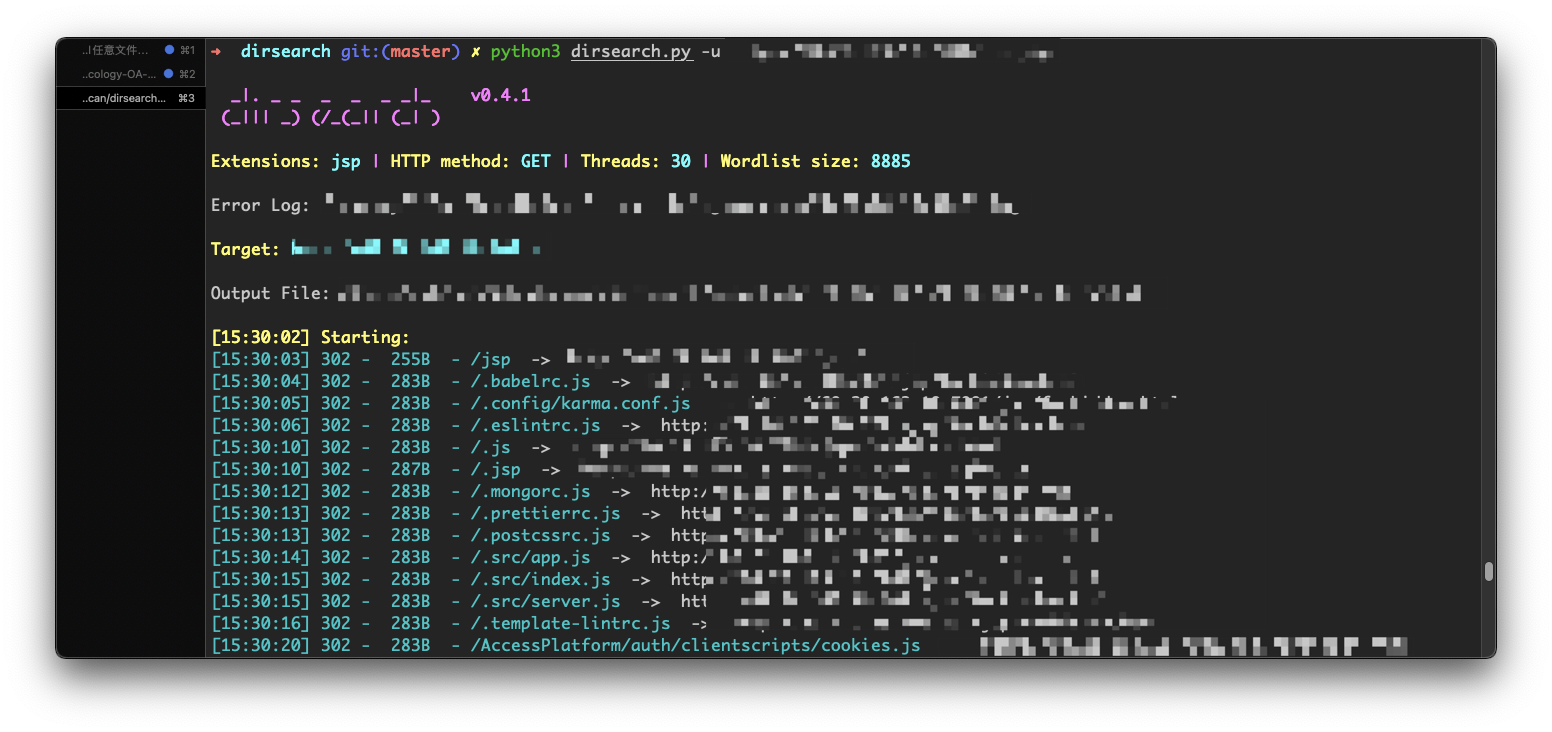
字典爆破后台路径
当进行完爬虫扫描后,发现目录中没有我们需要的网站后台地址。也许这后台地址并没有像我们想象中被放置链接中或者爬行深度不够等等原因。别灰心,我们还可以另行途径,尝试用后台字典来爆破后台地址。常用的工具有dirsearch、御剑等工具。我们是否能成功跑出后台取决于字典是否足够强大。因此,建议大家在日常测试中遇到的后台地址及时记录下来不断扩充我们的字典,从而方便以后的工作中使用。
端口扫描
还有一些管理员喜欢把服务器划分在一个比较大的端口号,然后单独把网站后台地址放置其中。对于这种情况,可以通过扫描网站来获取端口信息,然后逐 一对其进行访问浏览,看看会不会后台地址被放置在某个端口。对于端口的扫描,比较推荐的是nmap。有些比较狡猾的管理员不放心把后台地址放到当前站点页面,就喜欢把后台地址放置到子域名当中。可以通过对其子域名收集,说不定就有你想要的后台地址信息。
上述方法只是一些思路,真实环境往往是复杂多变的,渗透测试过程能不能找到突破口关键还是在于想法够不够骚。不要只在一棵树上吊死,尝试换棵树多试几次说不定就进去了。
来源:freebuf.com 2021-07-01 00:15:21 by: 教练我想开高达






















请登录后发表评论
注册