elk本身是非常强大的日志处理系统,分别由elasticsearch、logstash、kibana构成,功能分别是数据库、数据处理、前端展示。利用这些搭建一套用于密码topN统计的系统。当然要完成这种统计需要强大的处理性能。
搭建基础环境
基础环境
操作系统: ubuntu 20.4 64位
内存:16G
硬盘:2T数据盘,128G ssd系统盘
ElasticSearch:7.10.1
Kibana:7.10.1
Logstash:7.10.1
1、elasticsearch
解压文件,tar -zxvf elasticsearch*.tar.gz,切换目录到elasticsearch中,之后所有关于elasticsearch的设置基本发生在此目录中
修改配置文件,conf/elasticsearch.yml
建议修改如下 配置
———-路径———-
根据实际情况做修改
#数据存储路径
#path.data: /path/to/data
#日志文件路径
#path.logs: /path/to/logs
———-内存———-
#在启动过程中是否为内存加锁:
bootstrap.memory_lock: true
请保证 `ES_HEAP_SIZE` 环境变量的设置大约为系统可用内存的一半———-网络———–
#绑定IP地址,单机搭建的情况建议改成127.0.0.1,
network.host:127.0.0.1
http.port:9200
启动elasticsearch
通过命令./bin/elasticsearch 直接启动,以前台的形式运行。通过命令curl 127.0.0.1:9200查看是否启动成功。
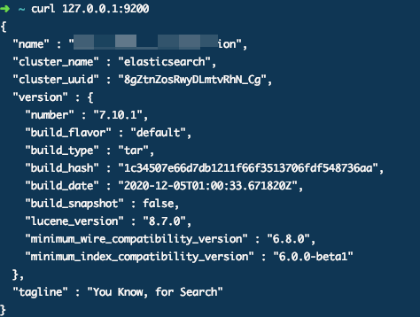
但是可以在使用过程中会报错,就是内存不足。此时需要修改jvm的大小。这个大小建议改成实际内存的一半。比我的电脑实际内存为16G,这里我用的就是8g。
文件位置:./config/jvm.options
–Xms8g
–Xmx8g
之后使用命令nohup ./bin/elasticsearch &以后台的方式运行ES
2、Kibana
下载kibana
解压文件,tar -zxvf kibana*.tar.gz,切换目录到kibana中,之后所有关于kibana的设置基本发生在此目录中。
kibana配置文件位置./config/kibana.yml
#监听端口
server.port: 5601 #默认配置
#IP配置
server.host: 0.0.0.0 #建议改成全部网卡
#elasticsearch 地址
elasticsearch.hosts:[“http://localhost:9200”] #根据实际情况配置,我上面配置的是localhost也就是127.0.0.1
之后通过命令nohup ./bin/kibana &在后台运行kabana,通过host:5601在浏览器访问kibana
3、logstash
添加数据实际上比较好用的方式是使用logstash进行数据导入,这种方式可以根据自己的实际情况,编写数据格式,定制化高,但是有一定的难度。实际上logstash也是整个部分中最重要的地方,就是数据导入,通过logstash可以将各种类型的数据格式后后导入到ES 中存储。
3.1 基础知识
下载logstash
解压文件,tar -zxvf logstash*.tar.gz,切换目录到logstash中,之后所有关于logstash的设置基本发生在此目录中。
开始进行数据 导入前,我们先理解一个东西,logstash实际上是用来收集日志并进行格式化处理的一个工具,集input、filter和output等插件
input可以接受来自beat(elk中一个轻量级的客户端,有多种beat,有兴趣的朋友可以自行了解)、日志文件、syslog等方式收集的日志。具体的可以参考官方手册https://www.elastic.co/guide/en/logstash/current/input-plugins.html。我们这里使用的是file插件。
filter可以使用grok、json、xml等方式格式化数据,根据实际情况选择某种方式具体的可以参考官方手册https://www.elastic.co/guide/en/logstash/current/filter-plugins.html。我们这里使用的主要是grok,可以根据文件情况编写不同的正则表达式来处理文件。
output实际上是结果的输出,也支持多种插件如syslog、csv、file等,具体参考官方手册https://www.elastic.co/guide/en/logstash/current/output-plugins.html ,我们这里使用的elasticsearch,将结果输出到es中。
3.2 简单的配置
示例文件weakpass.txt
admin—-123456
admin—-admin
admin—-1
admin—-12345
test—-123
test—-test
test—-1234
……
config 目录下有个名为lostash-sample.conf的示例文件
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
#数据源也就是输入配置
input {
#这里使用的是beats插件
beats {
port => 5044
}
}
#数据输出使用的是elasticsearch插件
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
我们根据上面的示例文件配置一个weakpass.conf文件
input{
file {
#要导入的示例文件
path => "path/weakpass.txt"
#开始位置
start_position => "beginning"
}
}
filter{
grok{
match => {
#格式化数据
"message"=>"(?<name>.*?)----(?<pwd>.*)"
}
}
}
output{
#使用debug将结果输出到屏幕中
stdout {
codec => rubydebug
}
}
使用命令 ./bin/logstash -f config/weakpass.conf来使用我们写的配置文件导入数据。

如果运行命令之后没有数据输出,建议删除<u>./data</u>的所有文件,一定要看清楚目录。

3.3 垃圾数据剔除
为了减少数据的冗余度及硬盘空间的大小,所以我们要根据情况删除一些无用字段,如path、message、host等。我们在gork中加入配置
remove_field=>[“path”,”message”,”host”]
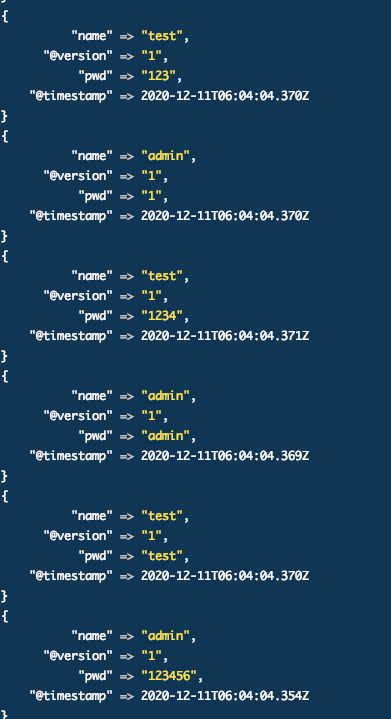
通过这样的配置,我们的数据量就减少了,其实时间戳也是可以删除了,而且并没有存在的意义,每条记录都带一个时间戳,实在是占用硬盘 空间。
3.4 数据导入ES
因为我们是在测试,所有使用的文件一直是weakpass.txt,logstash存在一个问题,处理过一次的数据,不会重复处理(描述不一定正确)。所有建议清空data目录。再进行下面的操作。
修改配置文件如下
input{
file {
#要导入的示例文件
path => "/media/k2/5fcda6c4-e009-41dd-a314-c54c3c55126b/elk/weakpass1.txt"
start_position => "beginning"
}
}
filter{
grok{
match => {
#格式化数据
"message"=>"(?<name>.*?)----(?<pwd>.*)"
}
remove_field=>["path","message","host","@timestamp"]
#设置标签,当我们数据量比较多的时候可以区分数据
add_tag => "weakpass"
}
}
output{
#使用debug将结果输出到屏幕中
#stdout{ codec => rubydebug}
elasticsearch{
action => "index"
index => "weakpass"#索引名称
hosts => ["127.0.0.1:9200"] #ES地址
}
}
3.5 使用kinaba
之后我们就可以在kibana中的索引管理中看到我们的索引
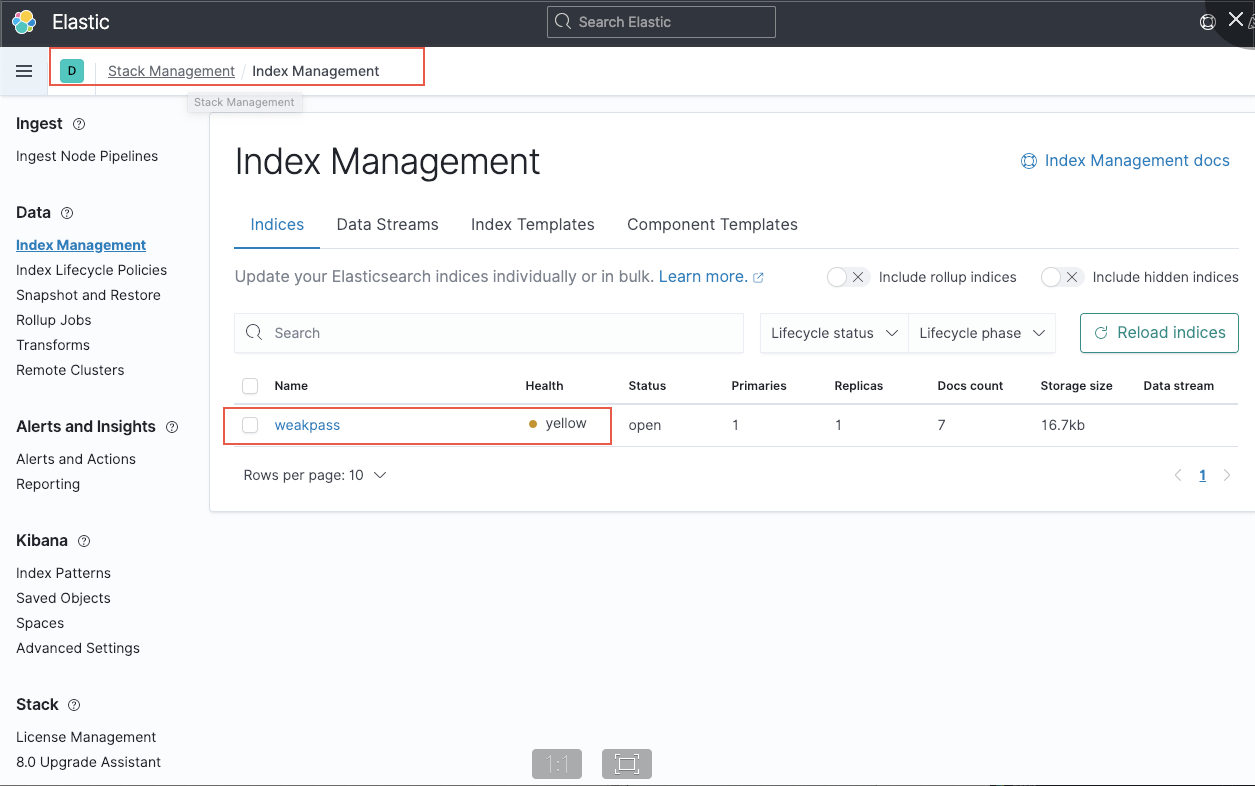
这是我们就可以根据所以创建索引模式了
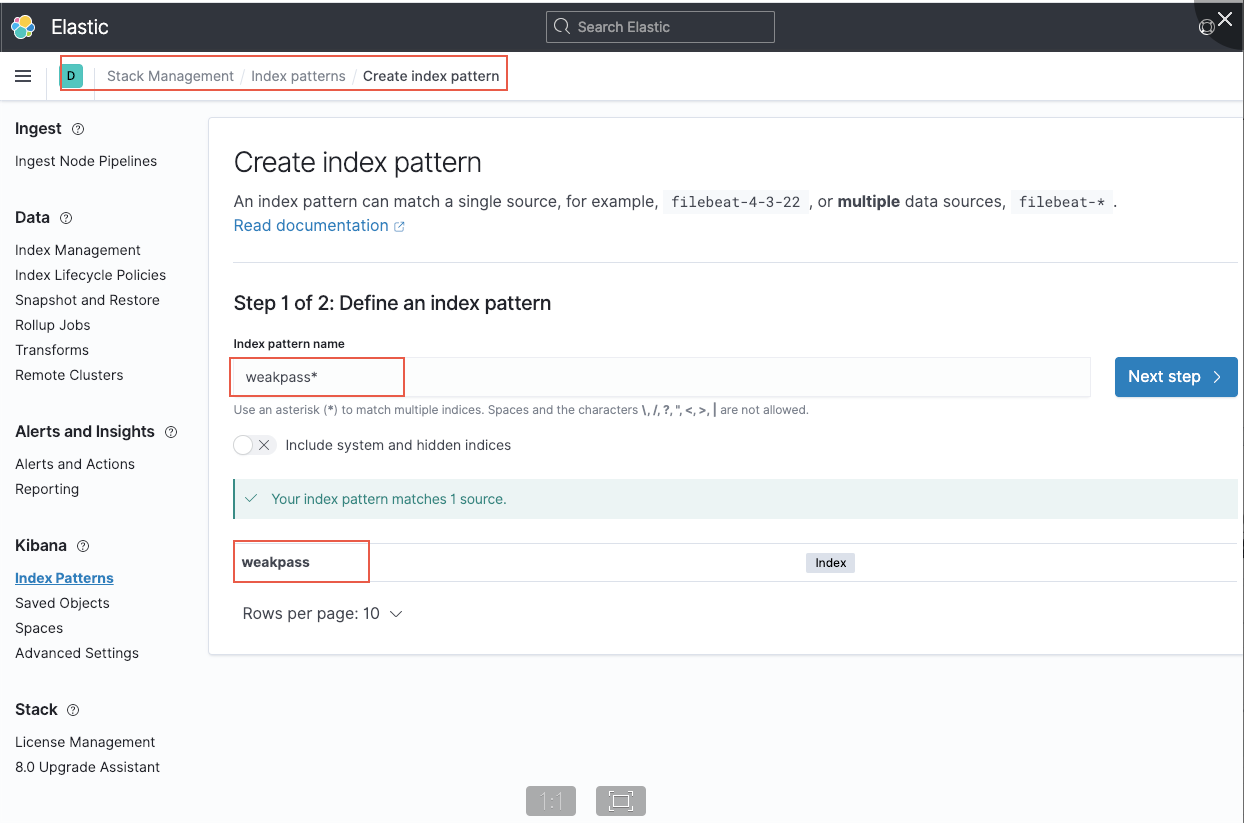
创建完成后就可以在discover中检索数据了
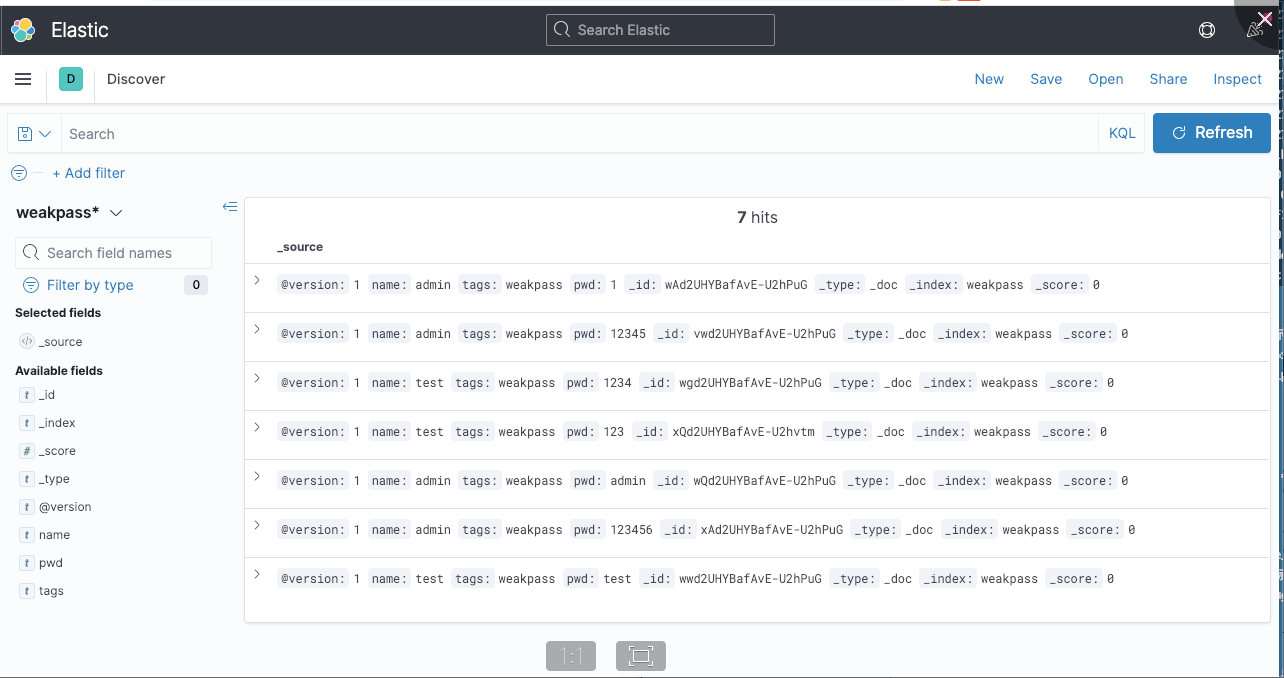
比如我们输入1,就可以检索到所有跟1相关的数据,
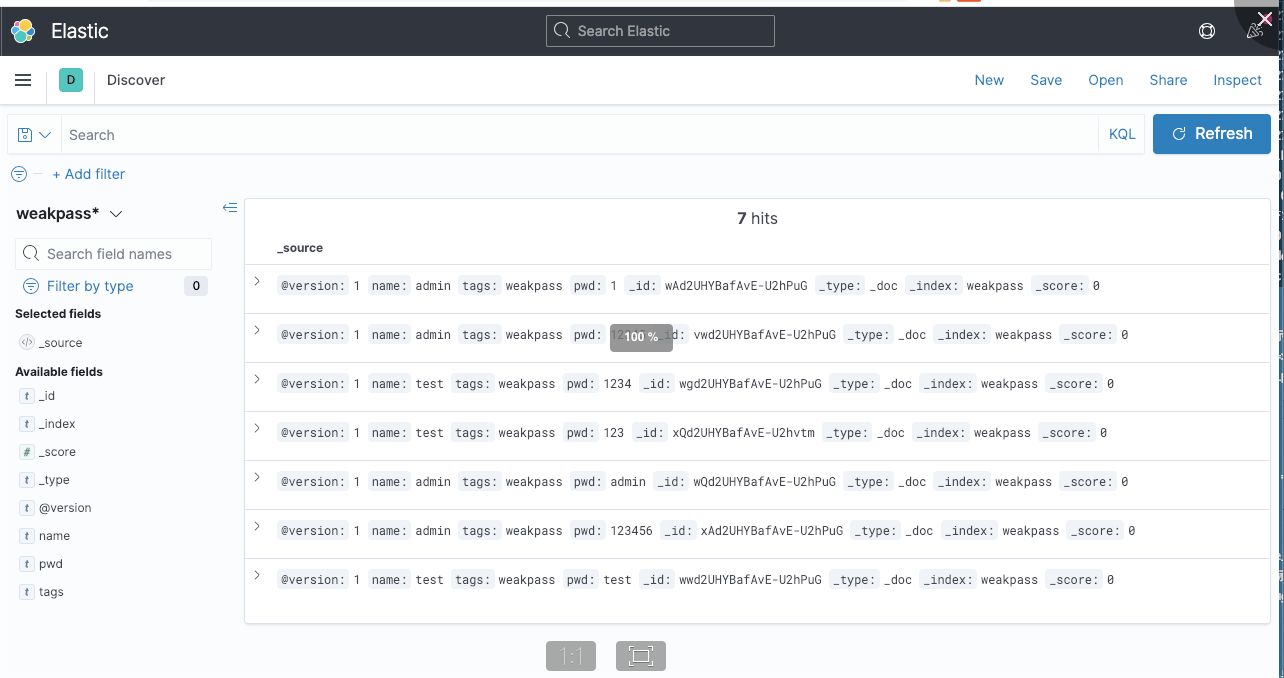
我们也可以检索用户名为admin的数据,这个就之会出来用户名为admin的用户了
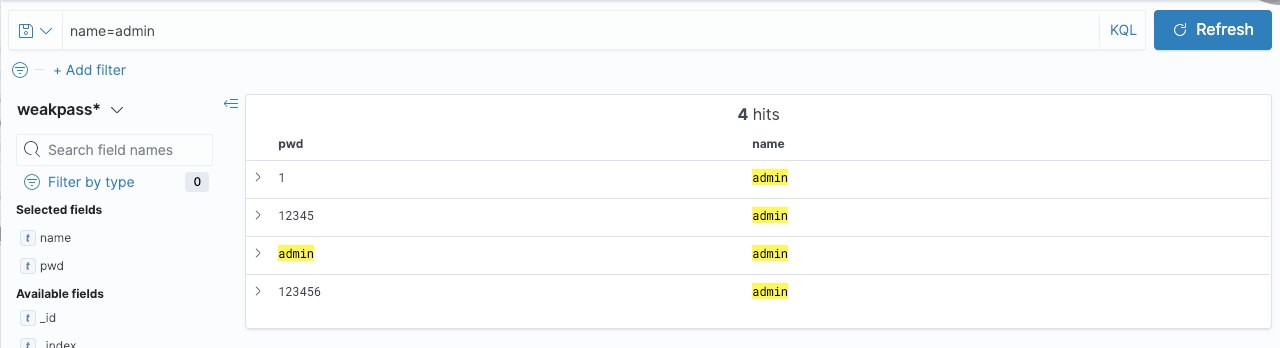
统计密码排行
使用kibana的dashboard可以统计密码排行
创建Data Table,选择源为我们上面创建的,之后进行如下的配置
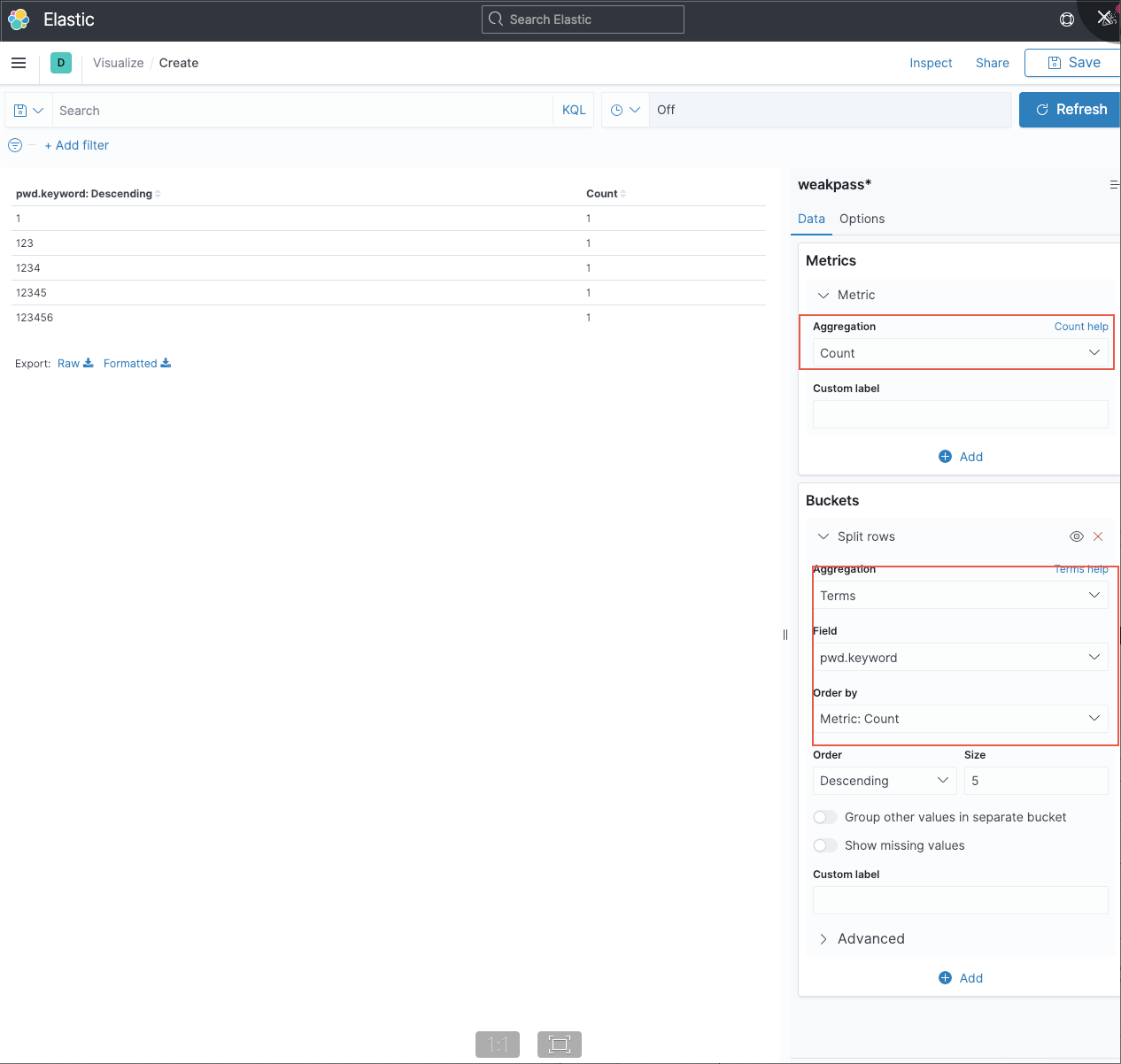
这样我们就得到了上面排名了。因为数据比较少,所以统计速度快,这里就做了演示,没有进行更多的数据导入了。
优化
优化存储
由于logstash在导入数据中会加入一些无用的字段,这些字段会在每一条记录中都出现,所以可以删除来减少服务器的存储空间。
path 原始路径
message 完整记录
host 主机名
@timestamp 时间戳
input{}
filter{
grok{
match => {
#格式化数据
"message"=>".*"
}
remove_field=>["path","message","host","@timestamp"]
#设置标签
add_tag => "weakpass"
}
}
output{}
优化索引
由于我们要导入不同的口令文件,所以我们要为后面的检索做好准备,这里我们就要根据导入内容的不同在output部分写上不同类型的索引,方便后面做检索使用。
output{
#使用debug将结果输出到屏幕中
# stdout{ codec => rubydebug}
elasticsearch{
action => "index"
index => "weakpass-mail-111" # 索引名
hosts => ["127.0.0.1:9200"]
}
}
index => 索引名,如果我们要导入的密码包括不同类型,这里抖机灵一下,写上不同的类型,
如weakpass-mail-1、weakpass-q-1、weakpass-b-1,这样我们在利用kibana进行创建索引样式时就可以创建weakpass*这一类的样式了。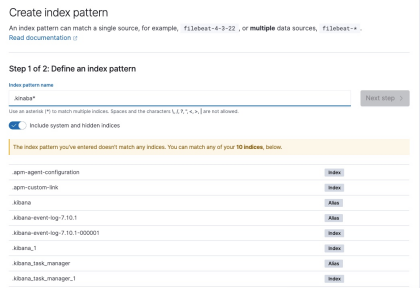
之后便可以在discover中选择对应的pattern来检索某一类数据。其实很有意思。
来源:freebuf.com 2020-12-21 21:41:01 by: lostCooky




















请登录后发表评论
注册