把以前学过的东西再复习总结一下,温故而知新。由于相较其他heap,largebin 中的机制相对复杂,所以largebin attack 一直是CTF的堆漏洞利用常规而少见的一种,但是却一直活着人们的心中。
背景知识
我们以64位,libc 2.27为例,其实与2.23差不多,只不过2.27中,0x420以下堆块会进入tcache,但是2.23中0x400就能进入largebin了
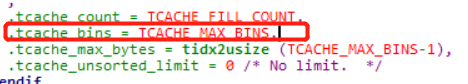
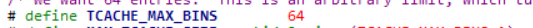
开始介绍large bin的相关机制。在此之前,请学习堆的申请与释放等相关知识。
largebin 从哪里来
在堆的机制中,free掉的chunk会进入bin,如果此chunk的大小大于fastbin,free后就会先进unsorted bin,之后,再次申请更大堆块,unsorted bin无法满足,heap就会进入large bin,那么large bin的范围是多少呢?
源码告诉我们一切:
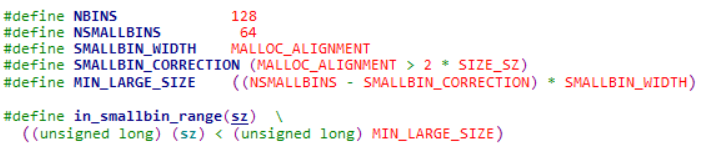
源码中可以看到,MIN_LARGE_SIZE是(64 – 0)*0x10 = 0x400,也就是最小的large bin。这里的MALLOC_ALIGNMENT其实等于SIZE_SZ,即系统位数乘以2,64位系统即 0x8乘以2=0x10,32位为0x4乘以2=0x8。
也就是说我们可以申请0x400的chunk,然后free掉进unsorted bin ,之后申请更大chunk,就可以将0x400的堆放入largebin。
注意:此时,我们使用的是libc 2.27,所以,其实0x400到不了largebin,而是tcache的范围,所以,在libc 2.27中,一般使用0x420,但是如果可以将0x400的tcache填满,也是可以申请到largebin的
那么large bin 的index如何确定呢,这里,系统采取了相对于fastbin和smallbin更加粗犷的方式:

large bin采取了分段的存储,比如第一个范围就是0x400到(48<<6),即0x400到0xc00,而其中,每个链表之间大小差为(1<<6)=0x40,结果如下表:
| index | size范围 |
|---|---|
| 64 | [0x400,0x440) 相差0x40 |
| 65 | [0x440,0x480)相差0x40 |
| …… | ……相差0x40 |
| 96 | [0xc00,0xc40)相差0x40 |
| 97 | [0xc40,0xe00)相差0x1c0 |
| 98 | [0xe00,0x1000)相差0x200 |
| …… | ……相差0x200 |
| …… | …… |
largebin 的内部
因为largebin,一个bin内部并不是一个size,所以需要fd_nextsize与bk_nextsize将其串起来。
那么largebin内部是如何布置的呢:
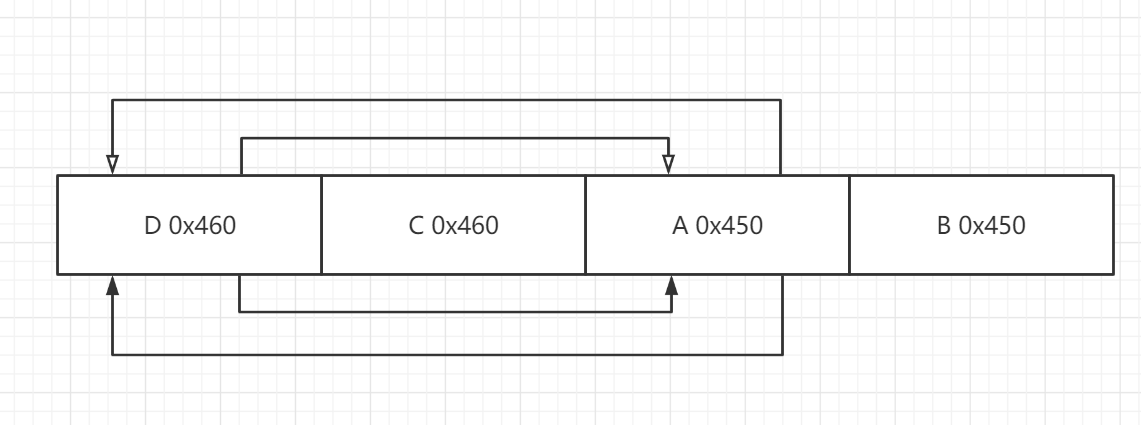
首先fd_nextsize指向比他小的最大heap,而bk_nextsize指向比他大的最小的heap,最后将两条链条首尾相连。而fd和bk和其原来的任务一样,都是指向和其大小相同的堆块。那么,画个草图:
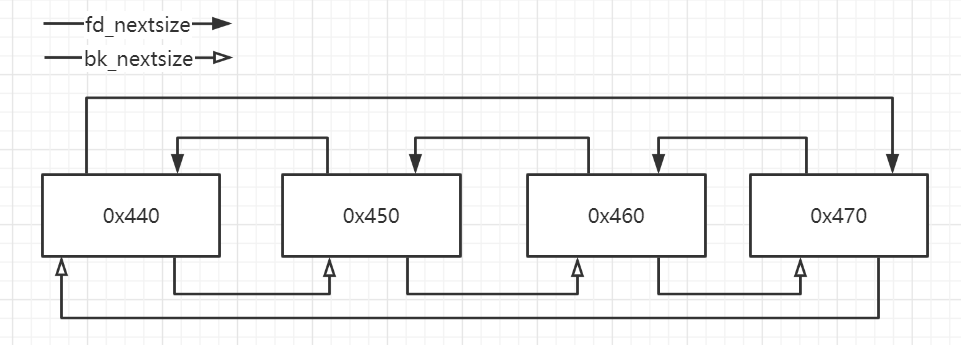
那么如果bin里的大小都一样的话,那么第一个释放的堆块作为此bin链的链首(这个和fastbin和tcache都不一样),fd_nextsize与bk_nextsize都指向自己,其余的大小相同的堆块free的时候,fd_nextsize与bk_nextsize就都为0了。
而fd和bk与原本作用一样,指向上一个释放的堆块,但是,这里的链头始终为第一个释放的chunk。
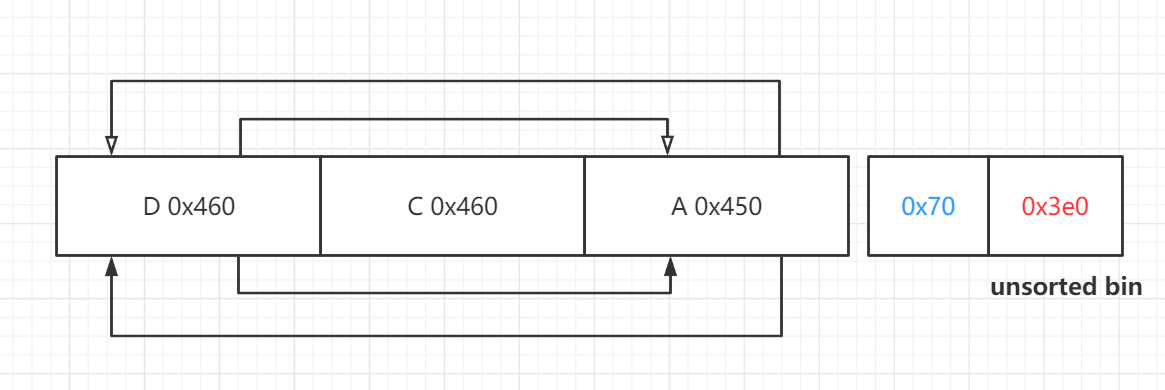
做个小实验,申请4个堆块ABCD,AB大小为0x450,CD大小为0x460,如下图:

其堆块如下:
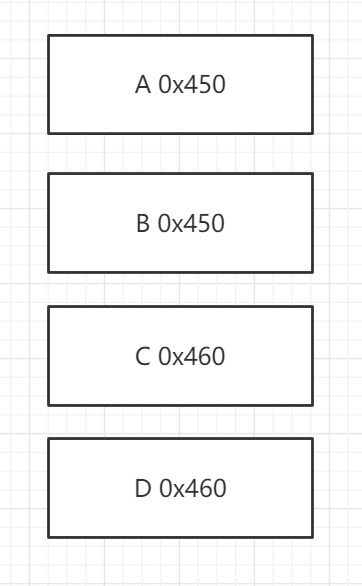
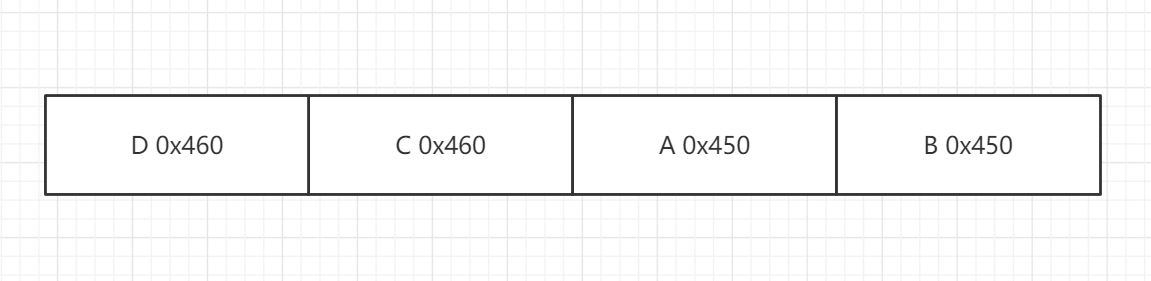
将其释放至unsorted bin,释放顺序为A B D C:

之后我们申请0x470堆块,此时unsorted bin无法满足,将ABCD放入large bin:


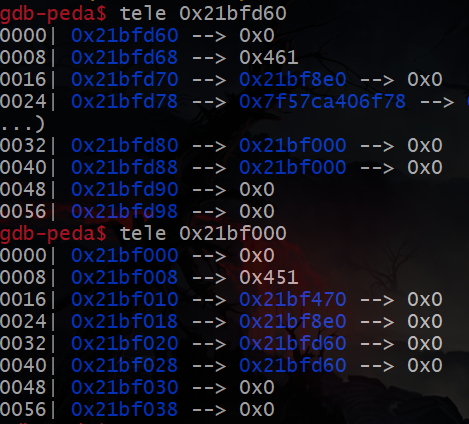
此时largebin内由fd和bk组成的链为:
此时的fd_nextsize与bk_nextsize:
最后的示意图即:
那么large bin 是如何申请到的呢?
源码中显示:
首先通过申请的size找到index,进而找到指定的bin链
在找到bin链后,从最小的heap开始通过bk_nextsize找到第一个大于等于size的heap
在找到heap后,利用fd判断下一个heap的size是否于当前heap的size,如果相等,将下一个heap返回,这样可以减少设置链头的操作
利用unlink取下得到的heap
判断heap的size减去申请的size是否大于MINSIZE,如果大于就将其放入unsorted bin,如果小于,那么直接分配给用户
这就是largebin的分配过程,那么largebin只有这一种被申请的方式吗?
如果在申请堆块的时候没有找到合适heap的时候,会从topchunk开始申请,在此之前,程序会遍历比当前index大的索引,如果在大于fastbin的范围内,存在heap,就会从中切割申请的大小,当前heap的size减去申请的size是否大于MINSIZE,如果大于就将其放入unsorted bin,如果小于,那么直接分配给用户。
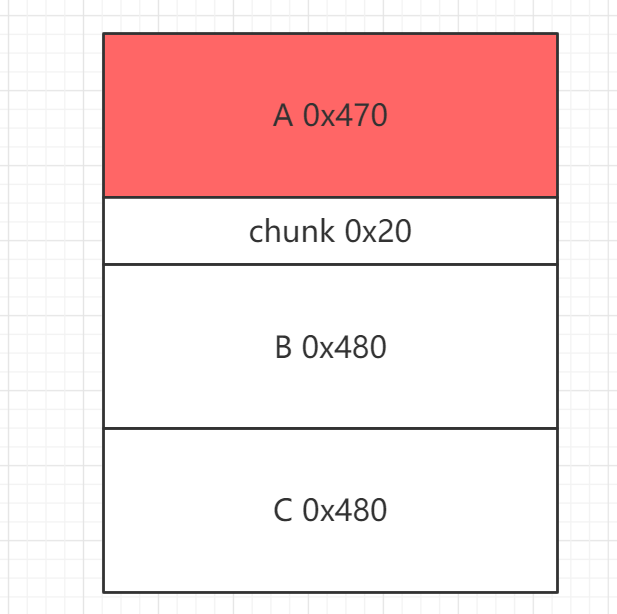
即,如果在上述情况下申请0x60,就会从B中分配0x60,余下0x3e0归入unsorted bin
这就是largebin在ptmalloc中的机制了。
large bin attack
那么large bin attack又是怎么进行的呢?
现在有两种常见的利用方式:
在申请largebin的过程中,伪造largebin的bk_nextsize,实现非预期内存申请。
在largebin插入的过程中,伪造largebin的bk_nextsize以及bk,实现任意地址写堆地址。
申请时利用
在申请largebin的时候,从最小的heap开始,利用bk_nextsize寻找合适的heap,如果找到了合适的heap,就将其取出,那么如果我们将bk_nextsize指向其他地方,就可以申请到其他地方。看下源码:
if ((victim = first (bin)) != bin
&& (unsigned long) chunksize_nomask (victim)
>= (unsigned long) (nb))
{
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb)))
victim = victim->bk_nextsize; //寻找堆块
......
remainder_size = size - nb;
unlink (av, victim, bck, fwd); //unlink所以只需要在目标地方符合unlink,那么就可以通过检查了。举个例子:申请一个largebin,之后free,再申请一个大堆块使之前堆块进入large bin:
申请A和底下分割的0x20,之后freeA,申请B和C。
之后,我们开始利用,这里提供两种思路吧,但是其本质都是修改bk_nextsize。
直接将bk_nextsize指向B的头
将bk_nextsize指向B的内容
第一种和第二种本质上一样,但是第二种可以顺便利用unlink,向bss段上写一个bss段地址,这里假设bss段上存着堆地址,如果PIE开启了,就不好操作了,这里我们关掉PIE,演示第二种漏洞利用。修改A的bk_nextsize,假设此时有UAF:也就是将bk_nextsize = B+0x10,而B+0x10一般存在bss段上,所以,此时B上伪造以一个的fd = bss - 0x18,bk= bss - 0x10的堆块,这都属于unlink常规操作。注意伪造堆块的fd_nextsize要等于0,因为unlink有检查。

之后注意对于伪造堆块检查,即检查下一个堆块的pre_size。最后得到:
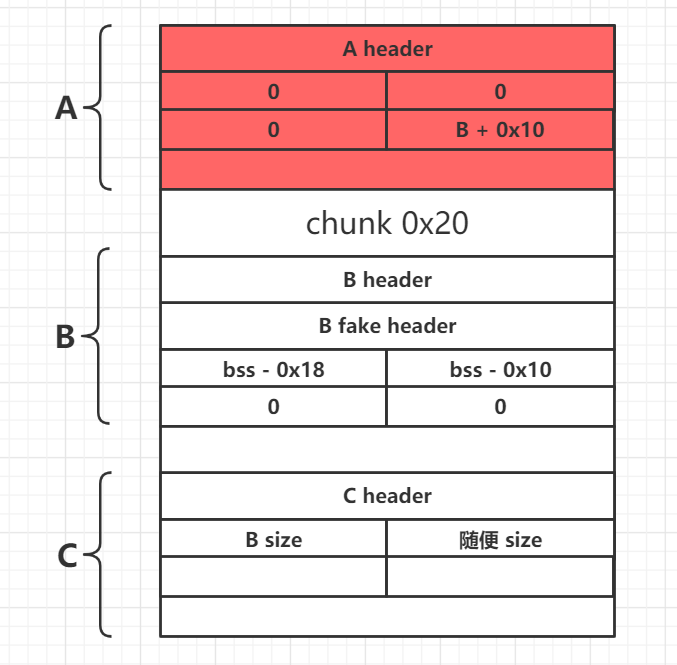
此时申请large bin ,就会得到fake B的内存区域。
插入时利用
在申请大堆块后,unsorted bin不满足size要求,会将其放入large bin,此时,我们可以通过一些办法,达到一次任意地址写堆地址的目的,看代码:
victim_index = largebin_index (size);
bck = bin_at (av, victim_index); //这个是main_arena的地址
fwd = bck->fd;//这是最大size的链首
/* maintain large bins in sorted order */
if (fwd != bck)
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size) //bck->bk是最小size的链首
< (unsigned long) chunksize_nomask (bck->bk)) //如果当前申请的size小于最小szie
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;//这里不好整
}
else //如果当前申请的size不是最小的
{
assert (chunk_main_arena (fwd));
while ((unsigned long) size < chunksize_nomask (fwd)) //从最大块开始寻找一个小于szie的链
{
fwd = fwd->fd_nextsize;
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd)) // 如果找到的链和申请的size相同
/* Always insert in the second position. */
fwd = fwd->fd;
else//如果不同,则说明应该插在这个链前面
{
victim->fd_nextsize = fwd;//小的链在victim上
victim->bk_nextsize = fwd->bk_nextsize;//这里如果可以控制
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;//这里能写一个victim
}
bck = fwd->bk;
}
}
else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;//最后这里,还可以有一次写,如果fwd->bk可控
可以看到,这段代码中有两次可以写入victim的地方,由于其比较简单,没啥检查,所以可以直接搞起:
搞到一块large bin 然后搞到一块更大的large bin,且其index一样。在得到这个large bin之前,先改写原本就在large bin中的堆块的bk或bk_nextsize。
举个例子:
首先申请3个chunk,free A堆块,之后申请更大的chunk
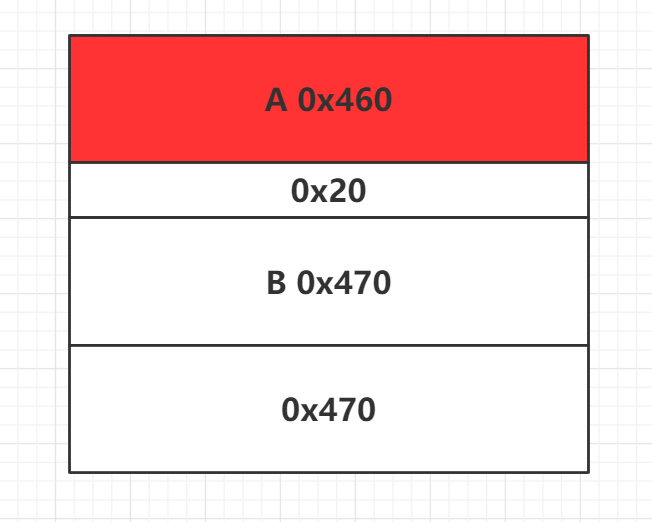
此时A在large bin内,之后修改A的bk或bk_nextsize:
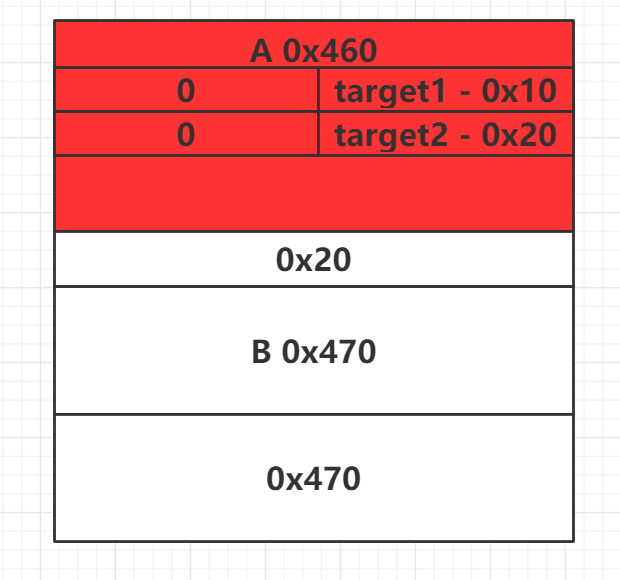
修改上述的bk和bk_nextsize,后续就可以达到在target1和target2中写堆B地址的目的。
之后,free chunk B,然后申请大于等于0x480的堆块,比如申请malloc(0x470),就可以达到漏洞利用目的了。
写在最后
如有错误欢迎指正:[email protected]
参考
[1]https://ray-cp.github.io/archivers/ptmalloc_argebin_attack
、*本文作者:白里个白sofr,转载请注明来自FreeBuf.COM
来源:freebuf.com 2020-04-28 16:00:45 by: 白里个白sofr