前言
在社交网络或者电商网站中,存在着用户关注其他用户或者用户浏览商品的二部图,而这些关系网络之中经常蕴藏大量的刷单,虚假,伪造行为,社区检测算法正是针对这些场景,进行深度行为挖掘,本文主要讲述一种社区检测算法在评论场景下的应用。
业务场景描述
应用商店下载评论业务人员发现有大量刷单行为,通过分析发现他们评论的内容和时间点都有明显的聚合效应,业务风控需要协助业务方挖掘出此场景下的恶意,需要评论人员,再依据发掘的信息进行跟踪二次处理。
算法选型
FRAUDAR算法来源于2016年KDD会议,该论文获得了当年的最佳论文奖。该算法要解决的问题是找出站内最善于伪装的虚假账户簇。其原理是虚假账户会通过增加和正常用户的联系来进行伪装,而这些伪装(边)会形成一个很紧密的子网络,这样就可以通过定义一个全局的度量,再移除二部图结构中的边,使得剩余网络结构对应的度量的值最大,这样就找到了最紧密的子网络,而这个网络就是最可疑的。
算法过程
算法的核心计算过程可以简要描述如下,具体可以参考原论文中Algorithm1的伪代码:
a、建立优先树(一种用于快速移除图结构边的树结构);
b、对于二部图中的任意节点,贪心地移除优先级最高(由优先树得到)的节点,直至整个网络结构为空;
c、比较上述每一步得到的子网络结构对应的全局的度量,取该值最大的子网络结构,那么该子网络结构就是最紧密的子网络,也就是最可疑的团伙。
其中最关键的地方是定义了一个全局度量,该Metric的定义是(目标度量),可以理解成子网络结构中每个点的平均可疑程度
g(s)=f(s)/|s|
其中,
f(s)=fv(s)+fe(s)
通过这样的定义,很容易可以得出4条性质:
1、固定其他条件,包含更高可疑度节点的子网络比包含较低可疑度节点的子网络更可疑;
2、固定其他条件,增加可疑的边使得子网络更可疑;
3、如果节点和边的可疑程度固定,那么大的子网络比小的子网络更可疑;
4、总的可疑程度相同,那么包含节点数少的子网络更可疑。
核心过程
该算法的核心计算过程就是贪心地移除图中的点,使得每次变更f的变化最大,在移除一个节点的同时,只有与之相邻的节点会发生变化,那么这样最多产生O(|E|)次变更,如果找到合适的数据结构使得访问节点的时间复杂度为O(log|V|),那么总的时间复杂度就是O(NlogN)。
基于这样的考虑建立了优先树,这是一个二叉树,图中的每个节点都是树的一个叶子节点,其父节点为子节点中优先级较高的,树建完之后就可以按照O(log|V|)的速度获得优先级最高的节点。
抗虚假行为
该算法的核心计算过程就是贪心地移除图中的点,使得每次变更f的变化最大,在移除一个节点的同时,只有与之相邻的节点会发生变化,那么这样最多产生O(|E|)次变更,如果找到合适的数据结构使得访问节点的时间复杂度为O(log|V|),那么总的时间复杂度就是O(NlogN)。
基于这样的考虑建立了优先树,这是一个二叉树,图中的每个节点都是树的一个叶子节点,其父节点为子节点中优先级较高的,树建完之后就可以按照O(log|V|)的速度获得优先级最高的节点。
线上特征工程
1、定时获取线上评论数据,包括但不限于:
用户id、应用id、设备id、创建时间等等
2、数据进行编码处理(由于设备id及应用id数字过大,需要去重后重新编码处理)

3、设备及应用关注映射构造
4、设置最大社群10个
5、保存分类簇结果(以设备id为分群数据提取)
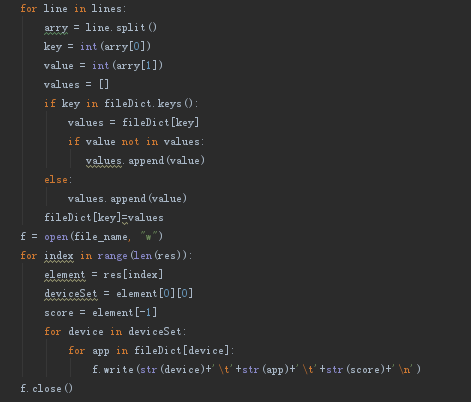 6、设定最小阈值,选择最可疑社区群簇里面的设备
6、设定最小阈值,选择最可疑社区群簇里面的设备
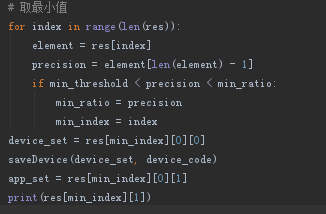
线上效果
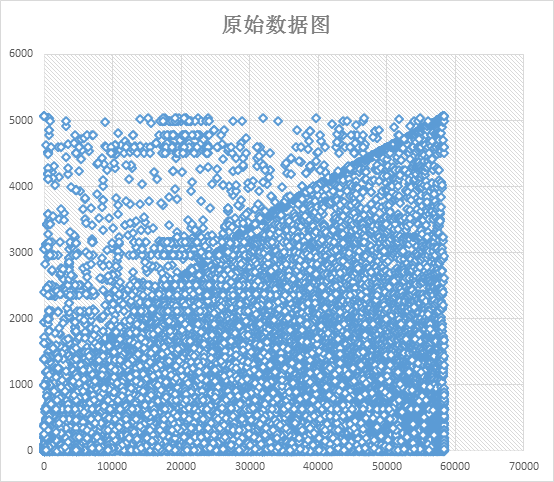
我们选择线上抽取连续一个月的数据进行分析,数据集合79927个,原始数据如下:
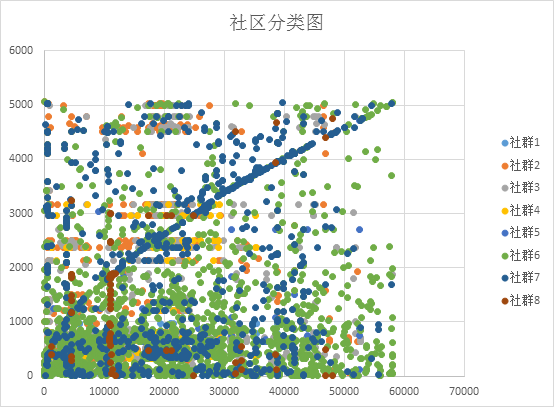
经过FRAUDAR检测出8个问题群簇,效果图如下:
总结
上述社群8类从小到大可疑度依次递增,系统中可以依据运营经验设置一个可疑阈值,选择此阈值下的所有社群。检测之后可以针对发掘的用户做行为跟踪或者限制行为处理,同时还可以结合监督学习进行分析,实现系统自动挖掘及模型线上防御,尽可能的来减少人工运营流程。
来源:freebuf.com 2019-02-22 11:50:52 by: flyking