*本文作者:ERFZE,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
前言
之前Alpha_h4ck分享了一个工具R3Con1Z3R,觉得很不错,虽然代码很简短,但是功能很强大,而且跨平台,同时支持Pyhthon2与Python3。
所以想从代码的角度去解读这个工具,并将它每一部分的功能分析一下。最后,我将它这个脚本进行了修改,可以单独取出里面的部分功能去执行。
另外,此文章主要面向新手及小白,大佬请自行绕过,勿喷。
脚本结构(大致如下图):
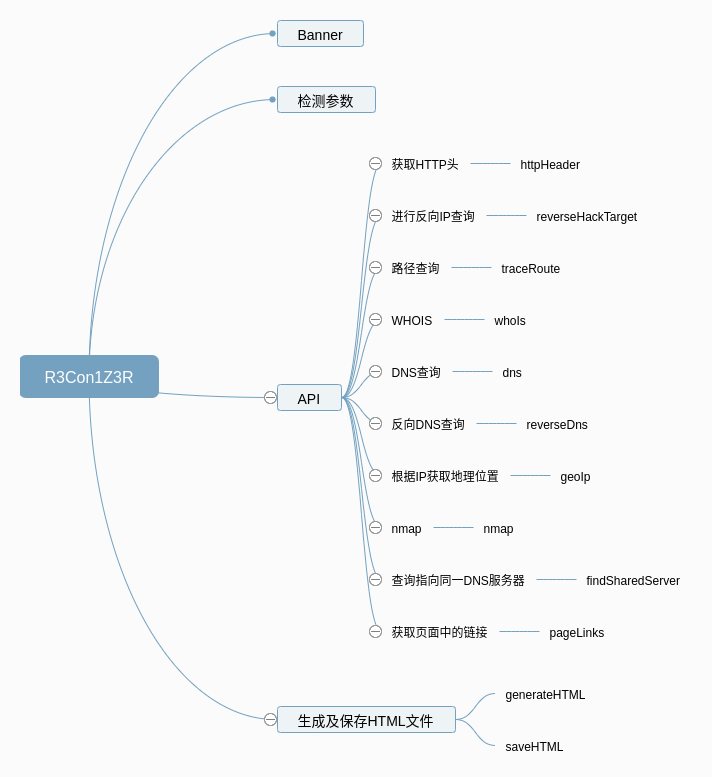
源代码解读
1. 打印Banner部分
if sys.platform.startswith('win'):
R, B, Y, C, W = '\033[1;31m', '\033[1;37m', '\033[93m', '\033[1;30m', '\033[0m'
try:
import win_unicode_console, colorama
win_unicode_console.enable()
colorama.init()
except:
print('[+] Error: Coloring libraries not installed')
R, B, Y, C, W = '', '', '', '', ''
else:
R, B, Y, C, W = '\033[1;31m', '\033[1;37m', '\033[93m', '\033[1;30m', '\033[0m'
# Banner Printing
def header():
print('''%s
_____ ____ _____ ___ _ _ __ ______ ____ _____
| __ \ |___ \ / ____| / _ \ | \ | | /_ | |___ / |___ \ | __ \
| |__) | __) | | | | | | | | \| | | | / / __) | | |__) |
| _ / |__ < | | | | | | | . ` | | | / / |__ < | _ /
| | \ \ ___) | | |____ | |_| | | |\ | | | / /__ ___) | | | \ \
|_| \_\ |____/ \_____| \___/ |_| \_| |_| /_____| |____/ |_| \_\
%sBy https://github.com/abdulgaphy - @mrgaphy%s >|%s #GAPHY %s
'''%(R, B, R, C, W))这一部分代码没什么可看的,只是设置颜色及打印Banner,效果可以见下图:

我的环境是Linux,Windows环境没有测试。
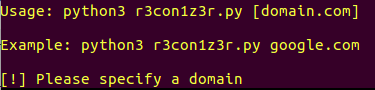
2. 检测参数部分
这一部分是我不太满意的地方,在我的修改版本中会有所体现。
if len(sys.argv) < 2 or len(sys.argv) > 2:
header()
print('{}Usage: python3 r3con1z3r.py [domain.com]\n'.format(Y, C))
print('{}Example: python3 r3con1z3r.py google.com\n'.format(Y, C))
print('{}[!] Please specify a domain'.format(Y, C))
sys.exit()
else:
url = str(sys.argv[1])这一部分检测是否提供了domain参数,如果没有,会给出下图所示的提示:
3. 各种API
获取HTTP头部分:
def httpHeader():
baseApi = "http://api.hackertarget.com/httpheaders/?q=" + url
base = requests.get(baseApi).text
return base该函数功能是获取响应头部分,下面的结果分别是我测试google.com及www.baidu.com得到的。
HTTP/1.1 301 Moved Permanently
Location: http://www.google.com/
Content-Type: text/html; charset=UTF-8
Date: Wed, 30 Jan 2019 10:53:05 GMT
Expires: Fri, 01 Mar 2019 10:53:05 GMT
Cache-Control: public, max-age=2592000
Server: gws
Content-Length: 219
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGINHTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: Keep-Alive
Content-Length: 277
Content-Type: text/html
Date: Thu, 31 Jan 2019 12:14:10 GMT
Etag: 575e1f6f-115
Last-Modified: Mon, 13 Jun 2016 02:50:23 GMT
Pragma: no-cache
Server: bfe/1.0.8.18进行反向IP查询部分:
def reverseHackTarget():
baseApi = "http://api.hackertarget.com/reverseiplookup/?q=" + url
base = requests.get(baseApi).text
return base
反向IP查找可返回单个IP上托管的域名,我在hackertarget的网站上进行了下面的查询:
结果可想而知了,多得数不胜数。
路径查询部分:
def traceRoute():
baseApi = "http://api.hackertarget.com/mtr/?q=" + url
base = requests.get(baseApi).text
这一部分功能再明显不过了,路由跟踪,在Linux下用traceroute,在windows则是tracert都能实现此功能。
WHOIS部分:
def whoIs():
baseApi = "http://api.hackertarget.com/whois/?q=" + url
base = requests.get(baseApi).text
return base
下面是对google.com进行WHOIS查询的结果:
Domain Name: GOOGLE.COM
Registry Domain ID: 2138514_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.markmonitor.com
Registrar URL: http://www.markmonitor.com
Updated Date: 2018-02-21T18:36:40Z
Creation Date: 1997-09-15T04:00:00Z
Registry Expiry Date: 2020-09-14T04:00:00Z
Registrar: MarkMonitor Inc.
Registrar IANA ID: 292
Registrar Abuse Contact Email: [email protected]
Registrar Abuse Contact Phone: +1.2083895740
Domain Status: clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited
Domain Status: clientTransferProhibited https://icann.org/epp#clientTransferProhibited
Domain Status: clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited
Domain Status: serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited
Domain Status: serverTransferProhibited https://icann.org/epp#serverTransferProhibited
Domain Status: serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited
Name Server: NS1.GOOGLE.COM
Name Server: NS2.GOOGLE.COM
Name Server: NS3.GOOGLE.COM
Name Server: NS4.GOOGLE.COM
DNSSEC: unsigned
URL of the ICANN Whois Inaccuracy Complaint Form: https://www.icann.org/wicf/
>>> Last update of whois database: 2019-01-30T10:53:11Z <<<
For more information on Whois status codes, please visit https://icann.org/epp
The Registry database contains ONLY .COM, .NET, .EDU domains and
Registrars.DNS查询部分:
def dns():
baseApi = "http://api.hackertarget.com/dnslookup/?q=" + url
base = requests.get(baseApi).text
return base
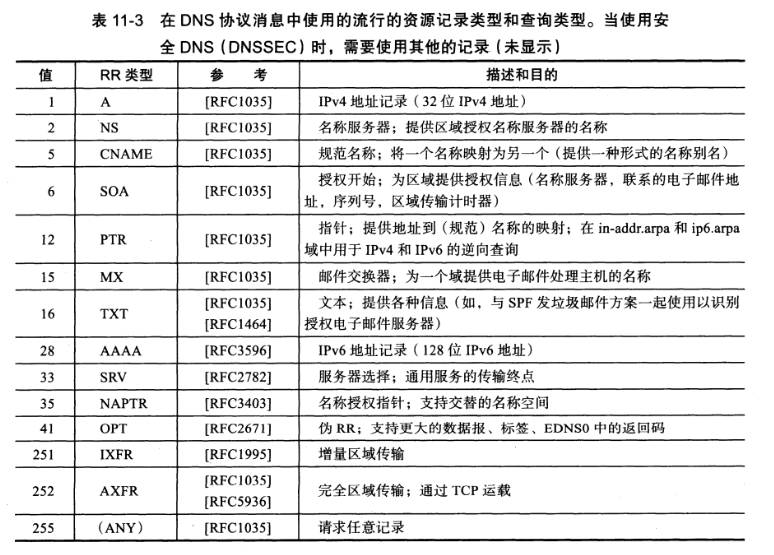
结果中的A、MX、NS、TXT可以参考下图(来自TCP/IP详解卷1):
反向DNS查询部分:
(这一部分没有出现在输出的结果中,不知是不是作者忘记写了)
def reverseDns():
baseApi = "http://api.hackertarget.com/reversedns/?q=" + url
base = requests.get(baseApi).text
return base
hackertarget网站给出的描述:这一项查找可以通过单个IP 8.8.8.8或是某个范围内的IP 127.0.0.1-10 或是CIDR形式127.0.0.1/27。你也同样可以使用主机名比如 example.com。
根据IP获取地理位置部分:
(这一部分也没有出现在输出的结果中,hackertarget指出此项查询目前处于测试阶段,不保证准确性)
def geoIp():
baseApi = "http://api.hackertarget.com/geoip/?q=" + url
base = requests.get(baseApi).text
return base
我对这一部分功能进行的测试发现,执行后会明显感觉到耗费时间增加。所以如果无此需求,建议使用我修改的脚本时也尽量不要使用此项功能。
nmap部分:
def nmap():
baseApi = "http://api.hackertarget.com/nmap/?q=" + url
base = requests.get(baseApi).text
return base
nmap的功能就不用多说了,不过hackertarget上给出的这个API接口是使用了-sV参数,而且只扫描21,22,23,25,80,110,143,443,445,3389这10个端口:
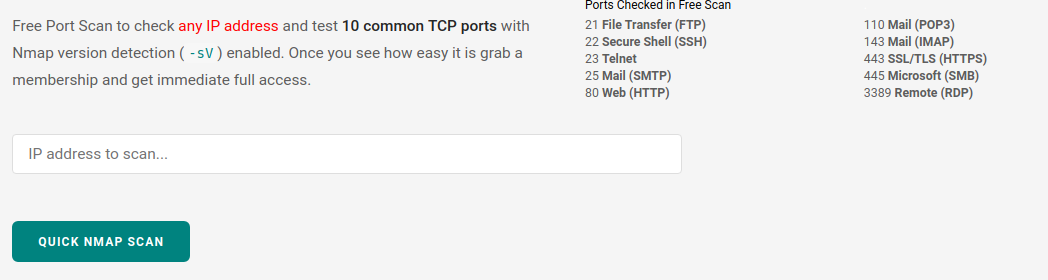
只能购买会员后才能够使用高级功能,作为“贫农”的我自然是没钱买的了,只能看看:
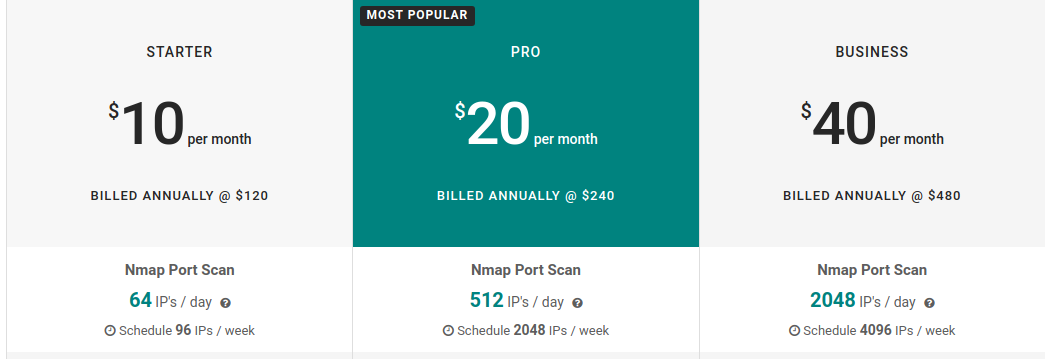
不过这些都不重要,最重要的是朋友使用后告诉我 它的扫描结果存在误报,我测试了一波,果然是这样,各位师傅可以自行测试一下。
另外,我感觉它这个功能写在脚本里有些鸡肋。
查询指向同一DNS服务器部分:
def findSharedServer():
baseApi = "http://api.hackertarget.com/findshareddns/?q=" + url
base = requests.get(baseApi).text
return base
获取页面中的链接部分:
def pageLinks():
baseApi = "http://api.hackertarget.com/pagelinks/?q=" + url
base = requests.get(baseApi).text
return base
更准确的说应该是将页面中的链接提取出来。
4. 生成及保存HTML文件
生成HTML文件部分:
def generateHTML():
create = """<!DOCTYPE html>
<html>
<head>
<title>R3C0N1Z3R Report</title>
</head>
<body>
<center> <h1>R3C0N1Z3R Report - [{}]</h1></center>
<strong>HTTP header information</strong>
<pre>{}</pre>
<strong>Trace Route</strong>
<pre>{}</pre>
<strong>Whois Information</strong>
<pre>{}</pre>
<strong>DNS server record</strong>
<pre>{}</pre>
<strong><Nmap- running services/strong>
<pre>{}</pre>
<strong>Website on the same server</strong>
<pre>{}</pre>
<strong>Reverse IP Address</strong>
<pre>{}</pre>
<strong>Page Links</strong>
<pre>{}</pre><hr>
<center> All Rights Reserved © <strong>R3CON1Z3R</strong></center>
</body>
</html>
""".format(url,httpHeader(),traceRoute(),whoIs(),dns(),nmap(),findSharedServer(),reverseHackTarget(),pageLinks())
return create
它的页面效果是这样的,很简单:

保存HTML文件:
def saveHTML():
saveFile = open(url + '.html', 'w')
saveFile.write(generateHTML())
saveFile.close()
print('{}[+] HTML Report Successfully Generated{}'.format(Y, C))
print('{}[+] File saved as {}{}.html{}'.format(Y, R, url, C))
print('{}[+] R3CON1Z3R Operation Completed!{}'.format(Y, W))
将结果以domain.html的文件名保存在同一目录下。
修改版本v1.7
#!/usr/bin/env python
# coding: utf-8
# Original Author: Raji Abdulgafar
# Twitter: @mrgaphy
# Mender:ERFZE
# R3CON1Z3R v1.7
import sys
import requests
import argparse
import re
# OS Compatibility : Coloring
if sys.platform.startswith('win'):
R, B, Y, C, W = '\033[1;31m', '\033[1;37m', '\033[93m', '\033[1;30m', '\033[0m'
try:
import win_unicode_console, colorama
win_unicode_console.enable()
colorama.init()
except:
print('[+] Error: Coloring libraries not installed')
R, B, Y, C, W = '', '', '', '', ''
else:
R, B, Y, C, W = '\033[1;31m', '\033[1;37m', '\033[93m', '\033[1;30m', '\033[0m'
# Banner Printing
def header():
print('''%s
_____ ____ _____ ___ _ _ __ ______ ____ _____
| __ \ |___ \ / ____| / _ \ | \ | | /_ | |___ / |___ \ | __ \
| |__) | __) | | | | | | | | \| | | | / / __) | | |__) |
| _ / |__ < | | | | | | | . ` | | | / / |__ < | _ /
| | \ \ ___) | | |____ | |_| | | |\ | | | / /__ ___) | | | \ \
|_| \_\ |____/ \_____| \___/ |_| \_| |_| /_____| |____/ |_| \_\
%sv1.0 By https://github.com/abdulgaphy - @mrgaphy%s >|%s #GAPHY %s
%sv1.7 By ERFZE
'''%(R, B, R, C, W,B))
# Api : functionalities
#WEB Tools
def httpHeader():
if args.web or args.all:
baseApi = "http://api.hackertarget.com/httpheaders/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
def pageLinks():
if args.web or args.all:
baseApi = "http://api.hackertarget.com/pagelinks/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
#nmap
def nmap():
if args.nmap or args.all:
baseApi = "http://api.hackertarget.com/nmap/?q=" + url
result=requests.get(baseApi).text
char_index=result.index('SERVICE\n')+8
nmap_title=result[:char_index]
union_string=re.sub(r'\d{2,4}/[a-zA-Z]{3,5}.*?filtered.*?\n',"",result)
base=nmap_title+union_string
return base
else:
return 'NO Result!'
#IP Address
def reverseHackTarget():
if args.address or args.all:
baseApi = "http://api.hackertarget.com/reverseiplookup/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
def geoIp():
if args.address or args.all:
baseApi = "http://api.hackertarget.com/geoip/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
#traceRoute
def traceRoute():
if args.trace or args.all:
baseApi = "http://api.hackertarget.com/mtr/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
#WHOIS
def whoIs():
if args.whois or args.all:
baseApi = "http://api.hackertarget.com/whois/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
#DNS Queries
def dns():
if args.queries or args.all:
baseApi = "http://api.hackertarget.com/dnslookup/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
def reverseDns():
if args.queries or args.all:
baseApi = "http://api.hackertarget.com/reversedns/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
def findSharedServer():
if args.queries or args.all:
baseApi = "http://api.hackertarget.com/findshareddns/?q=" + url
base = requests.get(baseApi).text
return base
else:
return 'NO Result!'
# Generating reports in HTML format
def generateHTML():
create = """<!DOCTYPE html>
<html>
<head>
<title>R3C0N1Z3R Report</title>
</head>
<body>
<center> <h1>R3C0N1Z3R Report - [{}]</h1></center>
<strong>HTTP header information</strong>
<pre>{}</pre>
<strong>Page Links</strong>
<pre>{}</pre>
<strong>Namp</strong>
<strong><Nmap- running services/strong>
<pre>{}</pre>
<strong>Reverse IP Address</strong>
<pre>{}</pre>
<strong>IP Location Lookup</strong>
<pre>{}</pre>
<strong>Trace Route</strong>
<pre>{}</pre>
<strong>Whois Information</strong>
<pre>{}</pre>
<strong>DNS server record</strong>
<pre>{}</pre>
<strong>Reverse DNS Lookup</strong>
<pre>{}</pre>
<strong>Website on the same server</strong>
<pre>{}</pre><hr>
<center> All Rights Reserved © <strong>R3CON1Z3R</strong></center>
</body>
</html>
""".format(url,httpHeader(),pageLinks(),nmap(),reverseHackTarget(),geoIp(),traceRoute(),whoIs(),dns(),reverseDns(),findSharedServer())
return create
# Saving the report
def saveHTML():
saveFile = open(url + '.html', 'w')
saveFile.write(generateHTML())
saveFile.close()
print('{}[+] HTML Report Successfully Generated{}'.format(Y, C))
print('{}[+] File saved as {}{}.html{}'.format(Y, R, url, C))
print('{}[+] R3CON1Z3R Operation Completed!{}'.format(Y, W))
if __name__ == '__main__':
parser=argparse.ArgumentParser()
parser.add_argument('-d','--domain',help='domain')
parser.add_argument('-a','--all',action="store_true",help='ALL functions')
parser.add_argument('-w','--web',action="store_true",help='WEB Tools(httpHeader AND pageLinks)')
parser.add_argument('-n','--nmap',action="store_true",help='nmap')
parser.add_argument('-i','--address',action="store_true",help='IP Address')
parser.add_argument('-t','--trace',action="store_true",help='traceRoute')
parser.add_argument('-s','--whois',action="store_true",help='WHOIS')
parser.add_argument('-q','--queries',action="store_true",help='DNS Queries(dnslookup AND reversedns AND findshareddns)')
args=parser.parse_args()
if args.domain:
header()
url = args.domain
saveHTML()
else:
header()
print('{}[!] Please specify a domain'.format(Y, C))
sys.exit()
这是我修改后的代码,主要改动如下:
a. 使用argparse模块,增加参数,使得用户可以选择部分功能执行。
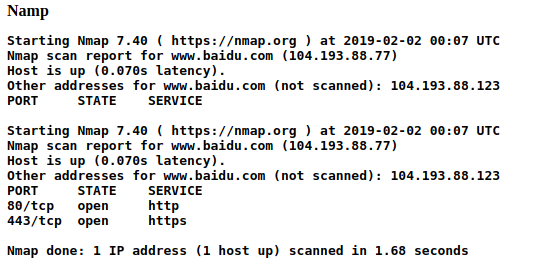
b. 将nmap结果中的filtered的项剔除,不出现到最后的HTML中。(虽然这个功能很鸡肋,但是还是留下了它)
结语
我已经将我修改的v1.7发给了原作者(一个非洲帅哥),如果后期还有改动的话,我会第一时间将代码放到评论区。等到最终它完全修改完成后,会上传到Github。
*本文作者:ERFZE,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。
来源:freebuf.com 2019-02-18 10:00:17 by: ERFZE