小安前言
随着网络安全信息数据大规模的增长,应用数据分析技术进行网络安全分析成为业界研究热点,小安在这次小讲堂中带大家用Python工具对风险数据作简单分析,主要是分析蜜罐日志数据,来看看一般大家都使用代理ip干了一些啥事。

大家可能会问小安啥是蜜罐,网上一些黑客或技术人员经常做一些"事情"的时候,需要隐藏自己身份,这样他们会使用代理IP来办事。而蜜罐(Honeypot)是一种新型的主动防御的安全技术,它是一个专门为了被攻击或入侵而设置的欺骗系统——既可以用于保护产品系统,又可用于搜集黑客信息,是一种配置灵活、形式多样的网络安全技术。
说得通俗一点就是提供大量代理IP,引诱一些不法分子来使用代理这些代理ip,从而搜集他们的信息。
数据分析工具介绍
工欲善其事,必先利其器,在此小安向大家介绍一些Python数据分析的“神兵利器“。
Python中著名的数据分析库Panda
Pandas库是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建,也是围绕着 Series 和 DataFrame 两个核心数据结构展开的,其中Series 和 DataFrame 分别对应于一维的序列和二维的表结构。
Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。这个库优点很多,简单易用,接口抽象得非常好,而且文档支持实在感人。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
数据可视化采用Python上最常用的Matplotlib库
Matplotlib是一个Python的图形框架,也是Python最著名的绘图库,它提供了一整套和Matlab相似的命令API,十分适合交互式地进行制图。
我们有了这些“神兵利器“在手,下面小安将带大家用Python这些工具对蜜罐代理数据作一个走马观花式的分析介绍。
1 引入工具–加载数据分析包
启动IPython notebook,加载运行环境:
%matplotlib inline
import pandas as pd
from datetime import timedelta, datetime
import matplotlib.pyplot as plt
import numpy as np
2 数据准备
俗话说: 巧妇难为无米之炊。小安分析的数据主要是用户使用代理IP访问日志记录信息,要分析的原始数据以CSV的形式存储。这里首先要介绍到pandas.read_csv这个常用的方法,它将数据读入DataFrame。
analysis_data = pd.read_csv('./honeypot_data.csv') 对的, 一行代码就可以将全部数据读到一个二维的表结构DataFrame变量,感觉很简单有木有啊!!!当然了用Pandas提供的IO工具你也可以将大文件分块读取,再此小安测试了一下性能,完整加载约21530000万条数据也大概只需要90秒左右,性能还是相当不错。
3 数据管窥
一般来讲,分析数据之前我们首先要对数据有一个大体上的了解,比如数据总量有多少,数据有哪些变量,数据变量的分布情况,数据重复情况,数据缺失情况,数据中异常值初步观测等等。下面小安带小伙伴们一起来管窥管窥这些数据。
使用shape方法查看数据行数及列数
analysis_data.shapeOut: (21524530, 22) #这是有22个维度,共计21524530条数据记的DataFrame
使用head()方法默认查看前5行数据,另外还有tail()方法是默认查看后5行,当然可以输入参数来查看自定义行数
analysis_data.head(10) 
这里可以了解到我们数据记录有用户使用代理IP日期,代理header信息,代理访问域名,代理方法,源ip以及蜜罐节点信息等等。在此小安一定一定要告诉你,小安每次做数据分析时必定使用的方法–describe方法。pandas的describe()函数能对数据进行快速统计汇总:
对于数值类型数据,它会计算出每个变量:
总个数,平均值,最大值,最小值,标准差,50%分位数等等;
非数值类型数据,该方法会给出变量的:
非空值数量、unique数量(等同于数据库中distinct方法)、最大频数变量和最大频数。
由head()方法我们可以发现数据中包含了数值变量、非数值变量,我们首先可以利用dtypes方法查看DataFrame中各列的数据类型,用select_dtypes方法将数据按数据类型进行分类。然后,利用describe方法返回的统计值对数据有个初步的了解:
df.select_dtypes(include=['O']).describe() 
df.select_dtypes(include=['float64']).describe()| proxy_retlength | scan_os_fp | scan_os_sub_fp | scan_scan_mode | dtype_details |
|---|---|---|---|---|
| count | 6.417354e+06 | 0.0 | 0.0 | 0.0 |
| mean | 1.671744e+03 | NaN | NaN | NaN |
| std | 3.104775e+04 | NaN | NaN | NaN |
| min | 0.000000e+00 | NaN | NaN | NaN |
| 25% | NaN | NaN | NaN | NaN |
| 50% | NaN | NaN | NaN | NaN |
| 75% | NaN | NaN | NaN | NaN |
| max | 2.829355e+07 | NaN | NaN | NaN |
简单的观察上面变量每一维度统计结果,我们可以了解到大家获取代理数据的长度平均1670个字节左右。同时,也能发现字段scan_os_sub_fp,scan_scan_mode等存在空值等等信息。这样我们能对数据整体上有了一个大概了解。
4 数据清洗
由于源数据通常包含一些空值甚至空列,会影响数据分析的时间和效率,在预览了数据摘要后,需要对这些无效数据进行处理。
一般来说,移除一些空值数据可以使用dropna方法, 当你使用该方法后,检查时发现 dropna() 之后几乎移除了所有行的数据,一查Pandas用户手册,原来不加参数的情况下, dropna() 会移除所有包含空值的行。
如果你只想移除全部为空值的列,需要加上 axis 和 how 两个参数:
analysis_data.dropna(axis=1, how='all')另外,也可以通过dropna的参数subset移除指定列为空的数据,和设置thresh值取移除每非None数据个数小于thresh的行。
analysis_data.dropna(subset=['proxy_host', 'srcip'])#移除proxy_host字段或srcip字段没有值的行
analysis_data.dropna(thresh=10)#移除所有行字段中有值属性小于10的行
5 统计分析
再对数据中的一些信息有了初步了解过后,原始数据有22个变量。从分析目的出发,我将从原始数据中挑选出局部变量进行分析。这里就要给大家介绍pandas的数据切片方法loc。
loc([start_row_index:end_row_index,[‘timestampe’, ‘proxy_host’, ‘srcip’]])是pandas重要的切片方法,逗号前面是对行进行切片;逗号后的为列切片,也就是挑选要分析的变量。
如下,我这里选出日期,host和源IP字段——
analysis_data = analysis_data.loc([:, [‘timestampe’,'proxy_host','srcip']])首先让我们来看看蜜罐代理每日使用数据量,我们将数据按日统计,了解每日数据量PV,并将结果画出趋势图。
daily_proxy_data = analysis_data[analysis_data.module=='proxy']
daily_proxy_visited_count = daily_proxy_data.timestamp.value_counts().sort_index()
daily_proxy_visited_count.plot()
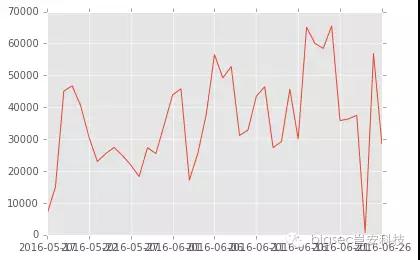
对数据列的丢弃,除无效值和需求规定之外,一些表自身的冗余列也需要在这个环节清理,比如说DataFrame中的index号、类型描述等,通过对这些数据的丢弃,从而生成新的数据,能使数据容量得到有效的缩减,进而提高计算效率。
由上图分析可知蜜罐代理使用量在6月5号,19-22号和25号这几天呈爆炸式增长。那么这几天数据有情况,不正常,具体是神马情况,不急,后面小安带大家一起来慢慢揪出来到底是那些人(源ip) 干了什么“坏事”。
进一步分析, 数据有异常后,再让我们来看看每天去重IP数据后量及其增长量。可以按天groupby后通过nunique()方法直接算出来每日去重IP数据量。
daily_proxy_data = analysis_data[analysis_data.module=='proxy']
daily_proxy_visited_count = daily_proxy_data.groupby(['proxy_host']).srcip.nunique()
daily_proxy_visited_count.plot()
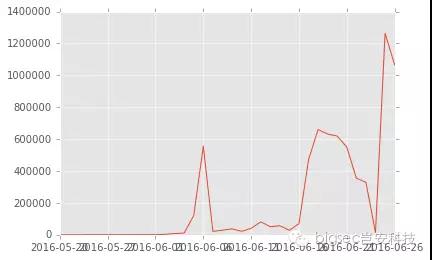
究竟大部分人(源ip)在干神马?干神马?干神马?让我们来看看被访问次数最多host的哪些,即同一个host关联的IP个数,为了方便我们只查看前10名热门host。
先选出host和ip字段,能过groupby方法来group 每个域名(host),再对每个域名的ip访问里unique统计。
host_associate_ip = proxy_data.loc[:, ['proxy_host', 'srcip']]
grouped_host_ip = host_associate_ip.groupby(['proxy_host']).srcip.nunique()
print(grouped_host_ip.sort_values(ascending=False).head(10))
| 代理访问host | 源ip |
|---|---|
| www.gan**.com | 1113 |
| wap.gan**.com | 913 |
| webim.gan**.com | 710 |
| cgi.**.qq.com | 621 |
| www.baidu.com | 615 |
| loc.***.baidu.com | 543 |
| baidu.com | 515 |
| www.google.com | 455 |
| www.bing.com | 428 |
| 12**.ip138.com | 405 |
再细细去看大家到底做了啥——查看日志数据发现原来在收集像二手车价格,工人招聘等等信息。从热门host来看,总得来说大家使用代理主要还是获取百度,qq,Google,Bing这类妇孺皆知网站的信息。
下面再让我们来看看是谁用代理IP“干事”最多,也就是看看谁的IP访问不同host的个数最多。
host_associate_ip = proxy_data.loc[:, ['proxy_host', 'srcip']]
grouped_host_ip = host_associate_ip.groupby(['srcip'_host']).proxy_host.nunique()
print(grouped_host_ip.sort_values(ascending=False).head(10))
| 源ip | 访问不同host个数 |
|---|---|
| 123.**.***.155 | 2850 |
| 64.**.**.122 | 2191 |
| 124.***.***.103 | 710 |
| 212.*.***.14 | 562 |
| 124.***.***.126 | 518 |
| 195.***.**.1 | 465 |
| 27.***.***.202 | 452 |
| 90.**.***.11 | 451 |
| 212.*.***.13 | 438 |
| 110.***.***.39 | 430 |
哦,发现目标IP为123.**.***.155的小伙子有大量访问记录, 进而查看日志,原来他在大量收集酒店信息。 好了,这样我们就大概能知道谁在干什么了,再让我们来看看他们使用proxy持续时长,谁在长时间里使用proxy。 代码如下——
这里不给大家细说代码了,只给出如下伪代码。
date_ip = analysis_data.loc[:,['timestamp','srcip']]
grouped_date_ip = date_ip.groupby(['timestamp', 'srcip'])
#计算每个源ip(srcip)的访问日期
all_srcip_duration_times = ...
#算出最长连续日期天数
duration_date_cnt = count_date(all_srcip_duration_times)
| 源ip | 持续日期(天) |
|---|---|
| 80.**.**.38 | 32 |
| 213.***.**.128 | 31 |
| 125.**.***.161 | 22 |
| 120.**.***.161 | 22 |
| 50.***.**.67 | 19 |
| 114.***.***.97 | 19 |
| 162.***.**.113 | 19 |
| 192.***.**.226 | 17 |
| 182.**.**.205 | 17 |
| 112.***.**.108 | 16 |
| 123.**.***.130 | 16 |
| 61.***.***.156 | 15 |
| 61.***.***.152 | 15 |
| 58.***.***.130 | 15 |
| 216.***.**.106 | 14 |
| 101.***.***.117 | 14 |
| 124.***.***.126 | 14 |
| 79.***.**.254 | 13 |
| 115.**.***.130 | 13 |
| 61.***.***.79 | 13 |
好了,到此我也就初略的知道那些人做什么,谁用代理时长最长等等问题额。取出ip = 80.**.**.38的用户使用代理ip访问数据日志,发现原来这个小伙子在长时间获取搜狐images。
蜜罐在全国各地部署多个节点,再让我们来看看每个源ip扫描蜜罐节点总个数,了解IP扫描节点覆盖率。结果见如下:
# 每个IP扫描的IP扫描节点总个数
node = df[df.module=='scan']
node = node.loc[:,['srcip','origin_details']]
grouped_node_count = node.groupby(['srcip']).count()
print grouped_node_count.sort_values(['origin_details'], ascending=False).head(10)
| 源ip | IP扫描节点总个数 |
|---|---|
| 106.***.**.161 | 9 |
| 45.**.**.214 | 9 |
| 94.***.**.174 | 8 |
| 119.**.**.216 | 7 |
| 61.***.***.222 | 7 |
| 182.**.**.205 | 6 |
| 182.**.***.75 | 6 |
| 42.**.***.89 | 6 |
| 123.**.**.64 | 6 |
| 42.**.***.128 | 6 |
| 42.**.***.106 | 6 |
| 42.**.***.82 | 6 |
| 114.***.***.157 | 6 |
| 80.**.**.38 | 6 |
| 42.**.***.149 | 6 |
| 115.**.**.163 | 6 |
由上述两表初步可知,一些结论:如源ip为182.**.**.205的用户长时间对蜜罐节点进行扫描,mark危险用户等等。
*本文作者:岂安科技,转载请注明来自FreeBuf.COM
来源:freebuf.com 2018-01-14 18:04:27 by: 岂安科技





















请登录后发表评论
注册