本文的起源几乎跟Chrome 的历史一样久远:开始于十年前,刚好从5.0.375版本开始,也恰恰是应用程序缓存(AppCache)首次被加入到Chrome之时。
该缓存模块主要提供一下三种功能:
离线浏览:允许用户在断网时能够正常浏览网站。
速度保障:直接从硬盘加载资源,而不用请求网络。
弹性作业:假如网站崩了,依然能够提供离线浏览体验。
时光荏苒,网络不断更新换代之后,Service Workers等新功能异军突起,AppCache逐渐被打入冷宫,沦为web开发的边缘。
不仅如此,Chrome 的AppCache逐渐成为安全性和稳定性的累赘:Web 平台最麻烦的客户端存储 API排名中荣登第二,在 2018 年和 2019 年期间拥有超过 400 个Chromium CL。
所以,当AppCache 被WHATWG标准弃用删除,以及在W3C的 HTML 5.1 标准中被标记为过时的时侯,也就见怪不怪了。
随后,Chrome 团队在Chrome 67中声明要弃用 AppCache,为移除不安全来源做了重要贡献。不久,在 Chrome 70 中,APPCache移除了一些不安全内容。
最终,AppCache计划在Chrome 82版本中被彻底删除(但实际上被推迟到Chrome 85版本)。
Chrome 的 AppCache 最终在 Chrome 85 版本中被默认删除,但仍留了个小余地:没有及时转换的网站可以选择“反向”回到原始版本,并在安全上下文环境中重新启用它。也即:虽然AppCache没有彻底消亡,也不过是苟延残喘。
最终删除将在 Chrome 93版本中实现(估计在 2021 年 10 月左右)。
是时候说再见
了解了 AppCache 满目疮痍的历史后,我认为这是一个绝佳的机会,可以在它完全死透之前再挖一些漏洞。 我很好奇在这个功能的最后生命周期中是否还有一些值得探索的地方。
对应用程序缓存的工作原理有了大致的理解之后,又仔细研读了@filedescriptor和Frans Rosén的相关研究(他们都独立发现了使用沙箱域的方法来利用 AppCache) ,我对于研究的大致方向开始有了眉目。
由于本人对跨域攻击比较感兴趣(它们有更广泛的影响),所以暂时丢弃了FALLBACK和CHROMIUM-INTERCEPT这两部分作为可能的影响因素,毕竟它们只使用同源 URL。

小提示:观众朋友们可能已经注意到CHROMIUM-INTERCEPT部分并没有在上面列出,也没有出现在 HTML 标准中。
原因在于,Chrome 决定放弃标准,使用自己的规则。
虽然本文不会讨论这些内容,但观众朋友们可以通过阅读 Jun Kokatsu 的Chrome 的旧功能简介或者研读该功能的报告来获得更多信息。
Cache分区
通过之前对XSLeaks相关的 Cache 分区的研究中,鄙人意识到可以利用它来检测跨源请求是否会导致重定向漏洞,故以此为起点并尝试发散研究。
通过如下方式设置缓存清单和 HTML 页面:
CACHE MANIFEST
https://www.facebook.com/settings
<html manifest="manifest.appcache">
<script>
applicationCache.onerror = () => console.log("User isn't logged since there was a redirect");
applicationCache.oncached = () => console.log("User is logged since there wasn't a redirect");
</script>
</html>
由于 Facebook 上的/settings页面只能由已登录的用户访问(否则会重定向到/login.php),因此可以利用错误和缓存事件来检测重定向是否发生,从而泄漏当前用户的状态。
这整体上是可行的,因为应用程序缓存无法缓存导致重定向的url路径,个中原因在WHATWG标准中有所描述。

图片译文:网页的重定向至关重要,它们要么表明网络存在问题(例如网络门户); 要么表示允许将资源添加到URL 下的缓存中,这些 URL 与网络模型允许访问的任何 URL 不同,导致生成孤立url页面; 或者允许资源存储在URL下(不同于其真实 URL )。不管是哪一种情况,都很糟糕。
虽然上述涉及的技巧很巧妙,但有两个无法单独使用 Cache分区来克服的限制:
页面必须根据 Web 应用程序的状态有条件地发出重定向。
只有一丢丢信息被泄露出来。
使用一个真实案例场景(例如https://www.facebook.com/me页面提供的场景)可以最好地说明这些限制。
当用户未登录时,会重定向到
/。当用户登录时,会重定向到
/victim(用户的个人资料页面)。
目前,我们只能问:“重定向发生了吗?”并且由于缺乏粒度,并不能区分两次重定向(因为在两种情况下都会触发同样的错误事件)。
之后尝试了不同的方法,但是没能再进一步,一度陷入迷茫。
network分区
network分区对我来说是一个未知的领域。因为到目前为止,我从未使用过network分区,并且对它的工作原理也只有一个模糊的概念。
通过阅读 MDN 文档,我的理解是:其中列出的资源将始终从网络中检索,而不是从缓存中检索。 但是,未列出的资源将首先从缓存中检索,如果未找到,才会从网络中检索。
为了确定其工作原理,测试中鄙人在清单中添加一个Network分区,并包含/settings页面作为它的参数。
CACHE MANIFEST
NETWORK:
https://www.facebook.com/settings
然后更改 HTML 文件以获取所述页面。
<html manifest="cache.manifest">
<script>
applicationCache.oncached = () => {
fetch("https://www.facebook.com/settings", { mode: "no-cors", credentials: "include" });
}
</script>
</html>
访问页面后,没有任何异常发生。页面请求按预期执行。登录 Facebook 之后,没有发生任何重定向。

但是当我决定退出 Facebook 并再次访问该页面时,发生了一些令人惊讶的事情。
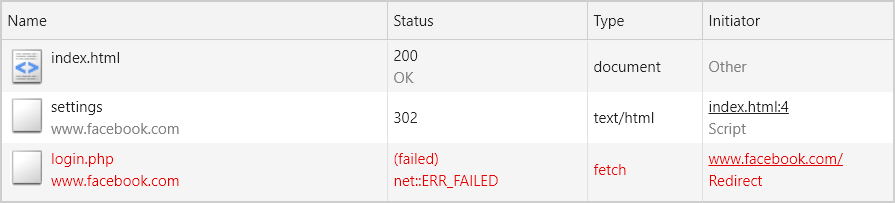
鉴于我已注销登录,重定向到/login.php页面在预料之中,但随后的请求居然失败了。
当我试图查找个中原因时,才发现我对网络分区的工作方式有很大误解。
如果在清单中设置了网络分区,并且尝试请求一个既不是网络分区也不是缓存分区中的URL,则该请求将被拒绝,这就是高效的许可名单工作原理。 更有趣的是,它也适用于源自重定向的请求,如上所示。
考虑到这一点,我将/login.php页面添加为 Network 分区的参数,并在仍然登出的情况下再次访问该页面:结果成功完成请求,没有被阻止。
一个新攻击的诞生
这一发现对于改进攻击的粒度至关重要,我能够因此确认任何给定的 URL 是否是重定向的一部分,从而开辟了很多可能性。
为了进行测试,我创建了以下清单。
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/victim
以及如下HTML文件:
<html manifest="cache.manifest">
<script>
applicationCache.oncached = () => {
fetch("https://www.facebook.com/me", {
mode: "no-cors",
credentials: "include"
}).then(() => {
console.log("The profile of the user is /victim");
}).catch(()= > {
console.log("The profile of the user isn't /victim");
});
}
</script>
</html>
上述攻击方法的思路为:使用网络分区中类似许可名单的属性,结合检测Fetch API网络错误的便捷方式使之泄漏更多的信息(在这种情况下是为了使用户去匿名化)。
(Fetch API是什么呢?它提供了一个获取资源的接口(包括跨域请求)。任何使用过 XMLHttpRequest 的人都能轻松上手,而且新的 API 提供了更强大和灵活的功能集。注)
该流程可描述为以下几步:
用户导航到恶意页面。
安装清单文件:它会阻止除
/me和/victim页面之外的所有网络连接。一旦清单安装完成,就会向
/me发出一个提取请求。由于
/me是网络分区中列入许可名单的url路径,因此该请求被允许。鉴于用户已登录 Facebook,将重定向至
/victim页面(即用户的个人资料页面)。如果用户的用户名是“victim”,请求将正常完成,因为
/victim是网络分区中列入许可名单的url路径。如果用户的用户名不是“victim”,则由于不存在与该用户名匹配的url路径而导致网络错误,请求将被拒绝。
这种攻击的一个明显缺点是:我们需要使用不同的用户名来创建一个清单并向/me页面发出一个请求,直到我们获得匹配的url路径为止。这一过程将耗费大量时间。
幸运的是,我们可以通过创建如下所示的清单来加速这个过程:同时包含数十万个用户名。一旦获得匹配后,使用二分搜索可以快速找到触发匹配的那个请求。
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/victim1
https://www.facebook.com/victim2
https://www.facebook.com/victim3
[...]
https://www.facebook.com/victin99998(本来是m,但是m和9连起来居然是敏感词,好疑惑……)
https://www.facebook.com/victin99999
https://www.facebook.com/victin100000
这是一个很大的改进,唯二美中不足的是需要数量庞大的用户名列表和爆棚的运气……
深入研究
我仍然对网络分区的内部工作原理感到好奇,因而决定阅读 Chrome 的 AppCache分区的源代码,在源代码中,诸如“URL 模式”和“非标准化”之类的关键字引起了我的注意。

由于存在很多非标准特性的参考资料,涉及到一些我比较陌生的模式。一番快速搜索后,我发现了224426号课题,该课题涉及到此特定功能的实现。
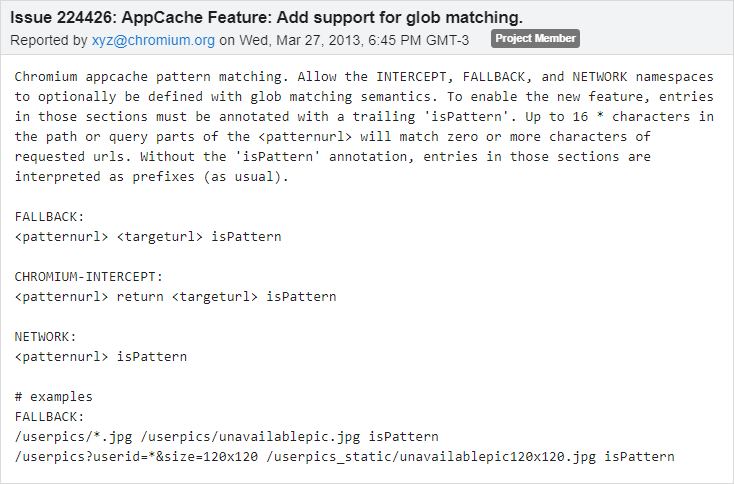
通过该课题我了解到,大约在 2013 年初,Chrome 应用程序缓存的FALLBACK、INTERCEPT和NETWORK分区添加了对模式匹配的支持。
自那以后,如果某url路径以“isPattern”结尾,则可以使用glob语义匹配来自这些部分的 URL。
有一个方法能够快速证明上述的准确性:两个清单都允许网络连接到/me和/victim页面。
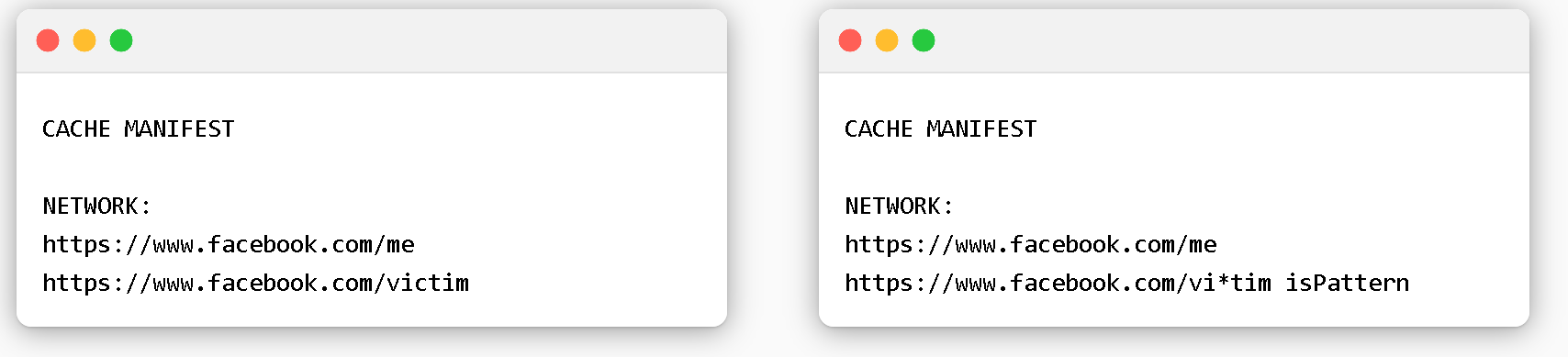
旧功能夺得胜利
在oracle的背景下,模式匹配是一个强大的工具:利用网络分区的类似许可名单的行为与非标准模式匹配功能相结合的方式,使得我们能够使用暴力破解方式来针对部分跨源重定向链的 URL。
然后可以通过以下步骤总结新修订的向量:
创建一个包含网络分区的清单。
发起重定向的目标页面作为url路径添加到网络分区。
另一个url路径被添加到网络分区,其中包含一个基本 URL,后跟一个随机字符(尾随通配符和“isPattern”必须包含在url路径的末尾)。
向目标页面发出一个请求,攻击者检查该请求是否会导致网络错误。
如果该请求导致网络错误,则意味着所选字符不是目标重定向链中 URL 的一部分。
考虑到之前的场景,向/me页面发出的请求(受以下清单建立的规则控制)将导致网络错误(因为用户已登录到“victim”帐户)。
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/a* isPattern
另一方面,如果根据以下清单的规则发出的请求成功的话,攻击者就能够推断出受害者用户名的第一个字符是“v”。
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/v* isPattern
对于每个注册清单,我们可以通过二分搜索法来查找成功的请求,从而提高效率。
上述方法是通过创建单个清单来实现的,该清单包含网络分区中的url路径,这些url路径与可能出现在目标页面 URL 中的字符有一半的几率能够匹配得上。
假设字符集仅限于 [a-z],则可以将它们分成两半并使用从“a”到“m”的字符(字符集的一半)来创建恶意清单。
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/a* isPattern
https://www.facebook.com/b* isPattern
https://www.facebook.com/c* isPattern
[...]
https://www.facebook.com/g* isPattern
[...]
https://www.facebook.com/k* isPattern
https://www.facebook.com/l* isPattern
https://www.facebook.com/m* isPattern
如果上面的清单已注册并向/me页面发出请求,则会出现以下两种可能的结果:
1.该请求成功返回,则表示受害者用户名的第一个字符在 [a-m] 范围内。
2.该请求导致网络错误,则表示第一个字符在 [n-z] 范围内。
这个过程会重复几次,每次迭代都会将字符范围缩小一半,直到只剩下一个,从而泄露了受害者用户名的第一个字母。
用户名随后的字符也可以被相同的方法获得,每个找到的字符都被附加到缓存清单中目标 URL 的末尾。
实践环节
通过 Chrome VRP,我向 Google 报告了我的发现(报告编号为1039869),他们迅速修复了该漏洞( 7 天内)。
与此同时,我开始思考跨域重定向的完整URL泄漏会产生影响的场景:
重定向到在请求参数中包含会话令牌的URL。
重定向到在请求参数中包含
CSRF令牌的URL。重定向到敏感信息(私人文档、照片等)。
重定向到用户的个人资料(用于去匿名化)。
基于此,我找了一个真实案例来确认其现实的可利用性。有趣的是,我甚至不需要离开 Chrome 的问题跟踪网站就能实现。
我偶然发现了https://bugs.chromium.org/p/chromium/issues/entryafterlogin页面,在用户进行身份验证后,该页面用于将其重定向到“报告表单”。
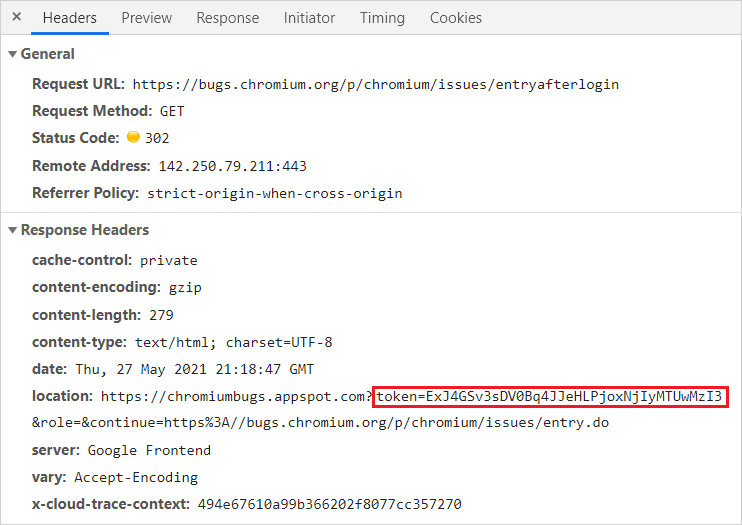
方便的是,该页面正在重定向到一个在请求参数中包含CSRF令牌的页面,如上所示,满足了展开攻击的先决条件之一!
放之四海而皆准的请求
当我编写POC时,我意识到我错过了一个很重要的事,将导致无法攻击该特定页面。
由于攻击的工作方式使然,必须向/p/chromium/issues/entryafterlogin页面发出几个请求,直到攻击者能够泄漏完整令牌。
但是这样子又有一个问题:在每个请求发送之后,都会生成一个全新的令牌,这反过来会改变将被重定向到的页面位置,从而阻止攻击流程。
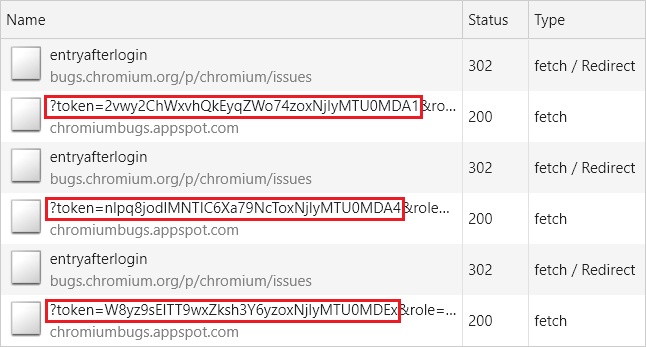
幸运的是,经过仔细检查发现,因为Cache-Control的header设置为“private”,我们可以使用“force-cache”选项集执行提取并缓存页面的响应(包括某些URL中带有 CSRF 令牌的位置header)。
fetch("https://bugs.chromium.org/p/chromium/issues/entryafterlogin", {
mode: "no-cors",
credentials: "include",
cache: "force-cache"
});
通过这种方式,我可以确保后续请求不会从网络加载,而是从缓存加载(这样可以有效冻结重定向的 URL ,也因此冻结 CSRF 令牌),从而允许攻击者执行攻击。
后记
此后一马平川,我完成了POC的编写(整个漏洞可以在https://gist.github.com/lbherrera/6e549dcf49334b637c22d76518a90ff6上找到)。
但故事并没有就此结束……
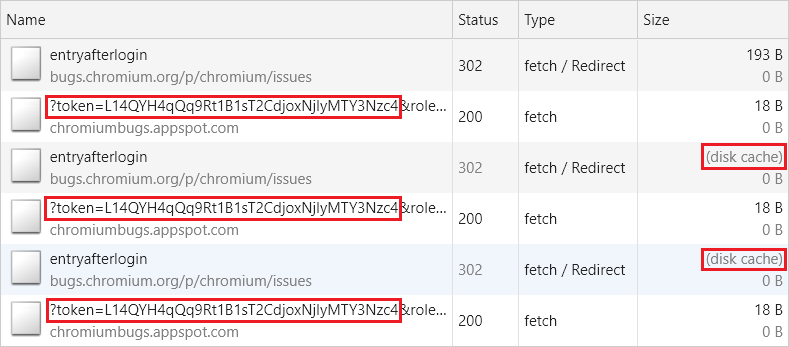
差不多一年后,我修改了攻击代码,注意到仍然可以通过另一种方式实现攻击,事后看来这是显而易见的。

由于AppCache规范中的一个缺陷(上图红框处),使得攻击者有可能通过滥用 URL 匹配的方式(前缀匹配)再次执行攻击。
如果注册了如下所示的缓存清单,则对以https://facebook.com/v前缀开头的 URL 的请求,将被列入许可名单并成功返回,而不以该前缀开头的请求将被拒绝。
CACHE MANIFEST
NETWORK:
https://facebook.com/me
https://facebook.com/v
这意味着根据上述缓存清单的规则,对以下 URL 的请求都可以正常工作:
https://facebook.com/v
https://facebook.com/vi
https://facebook.com/vic
https://facebook.com/vict
https://facebook.com/victi
https://facebook.com/victim
并且对https://facebook.com/anothervictim的请求不会导致上次攻击的发生。
所以又可以向 Chrome VRP 提交另一份报告!
在我意识到这是存在于规范中的问题后,我测试了其他浏览器,了解到虽然 Firefox 曾经也存在这个漏洞,但它们早已弃用 AppCache,并且在其稳定版本中默认禁用了它(如果要重新激活,用户必须启用一个标志)。
这两次提交的漏洞编号为CVE-2020-6399 和 CVE-2021-21168,总共 10000 美元的赏金:)
谢谢阅读!
原文链接:https://blog.lbherrera.me/posts/appcache-forgotten-tales/
来源:freebuf.com 2021-07-02 19:10:24 by: 会飞的猪434



















请登录后发表评论
注册